金額単位サンプルのサンプル サイズを計算
データ セットのサンプリングを実施する前に、統計的に適切なサンプル数と後続のサンプルおよび評価処理で必要な他の値を計算する必要があります。
Analytics のサンプル サイズの計算機能は、ユーザーが提供する入力値に基づき必要な値を計算します。
サンプル サイズを計算することの重要性
後続のサンプルの有効性を計るには、適切なサンプル サイズを計算することが重要になります。サンプルが有効でない、または代表を表してない場合は、全母集団に対してサンプルで実行する監査手続きの結果を信頼して予測することはできません。
サンプル サイズの計算を省略したり、サンプル サイズを推定しないでください。
サンプル サイズの計算に使用するほとんどの入力値は、専門的な判断に基づきます。運用環境でサンプリングの結果を信頼する前に、値が示す意味を十分理解するようにしてください。不明な点がある方は、監査サンプリング担当者、または監査サンプリング スペシャリストにお問い合わせください。
入力値がサンプル サイズに影響する方法
入力値は Analytics で計算されるサンプル サイズに影響します。[サイズ]ダイアログ ボックスの[計算]ボタンを使用すると、異なる入力値がサンプル サイズに影響する方法を実験できます。
以下の表は、サンプル サイズに対する入力値の影響をまとめています。
注意
本番環境では、サンプル サイズを小さくする目的だけで、入力値を操作しないでください。入力値は、サンプリングされるデータと監査目的に対して最も適切であるという専門的な判断に基づいているべきです。
| この入力値を増やす: | サンプル サイズを小さくします | サンプル サイズを大きくします |
|---|---|---|
| 信頼度 |
|
|
| 母集団 |
|
|
| Materiality |
|
|
| 想定される合計誤謬数 |
|
手順
メモ
値を指定する際、3 桁の区切り記号やパーセント記号は含めないでください。これらの文字を使用すると、コマンドを実行できないか、エラーが発生します。
- [サンプリング > レコード/金額単位サンプリング > サイズの計算]を選択します。
メモ
メニュー オプションは、テーブルが開いていない場合は無効です。
- [メイン]タブで、[金額単位]を選択します。
- サンプル サイズを計算するために使用する入力値を入力します。
- 信頼
- 母集団
- Materiality
- 想定される合計誤謬数
メモ
入力値は以下で詳細に説明します。
- (省略可能)[計算]をクリックすると、出力結果のプレビューが表示されます。
ヒント
[OK]の代わりに[計算]をクリックすると、結果を出力する前に別の入力値で実験できます。
メモ
出力結果は以下で詳細に説明します。
- [出力]タブ
- [To]パネルで、次のいずれかを選択します。
- 画面 - Analytics の表示領域に結果を表示します
- ファイルは結果をテキスト ファイルに保存または追加します
ファイルは Analytics の外部に保存されます。
- 出力タイプとして[ファイル]を選択した場合、次のいずれかを実行します。
- [名前]テキスト ボックスにファイル名を入力します。
- [名前]ボタンをクリックして、[保存]または[ファイルを保存する名前]ダイアログ ボックスでファイル名を入力するか、既存のファイルに上書きまたは追加する場合はそのファイルを選択します。
Analytics によってファイル名があらかじめ設定されている場合は、その設定されている名前を受け入れることも、あるいは変更することもできます。
また、絶対ファイル パスや相対ファイル パスを指定したり、別のフォルダーへ移動したり、プロジェクトの場所以外の場所にファイルを保存したり、その場所にあるファイルに追加したりすることもできます。たとえば、C:\Results\Output.txt または Results\Output.txt のように指定します。
メモ
ファイル タイプ オプションは、使用している Analytics のエディションに応じて、ASCII テキスト ファイルまたは Unicode テキスト ファイルのいずれかのみです。
- [To]パネルで、次のいずれかを選択します。
- [OK]をクリックします。
- 上書きを確認するメッセージが表示されたら、適切なオプションを選択します。
サイズ ダイアログ ボックスの入力と結果
次の表は、[サイズ]ダイアログ ボックスの入力値と出力結果の詳細を示します。
メイン タブ – 入力値
|
入力値 – サイズ ダイアログ ボックス |
説明 |
|---|---|
| 信頼度 |
必要な信頼度。この信頼度で、結果のサンプルが母集団全体を表します。 たとえば、95 を指定した場合は、サンプルが 実際に 95% の確率で母集団を代表しているとお客様が信頼したいということを意味します。信頼度は "サンプリング リスク" の補数です。信頼度が 95% ということはサンプリング リスクが 5% ということと同じです。 |
| 母集団 |
数値サンプル フィールドの絶対値 メモ 絶対値を取得するには、サンプル フィールドで統計情報をプロファイリングするか生成します。 |
|
Materiality |
サンプル フィールドの値として許容する最大の虚偽表示合計金額のことです。重大な虚偽表示額とまでは見なされません。 たとえば、29000 を指定するとは、虚偽表示合計金額が $29,000 を上回る場合に重大な虚偽表示額と見なすということです。 |
| 想定される合計誤謬数 |
サンプル フィールドの値として許容する最大の虚偽表示合計金額のことです。 たとえば、5800 を指定するとは、虚偽表示合計金額として $5,800 までを許容するということです。 メモ 指定する 推定定合計誤謬は Materiality 未満でなければなりません。これらの相違が小さすぎる場合は、計算するには誤謬率が高すぎますというエラー メッセージが表示されます。 監査サンプリング用語では、相違で代表されるサンプリングの精度の度合いは、指定した信頼度のレベルに対して計算するには小さすぎます。 |
メイン タブ – 出力結果
| 出力結果 – サイズ ダイアログ ボックス | 説明 |
|---|---|
| サンプル サイズ | 必要なサンプル数です。 |
| 間隔 | 間隔値–固定間隔とセルの選択方法に必要。 |
| 最大許容汚染(%) |
Materiality を超えずに、結果のサンプリングの虚偽表示金額で発生しうる最大累積汚染割合。 メモ Analytics が報告した最大許容汚染(%)値は 100% を超えることができます。 詳細については、最大許容汚染(%)を参照してください。 |
入力および結果の例
Invoices テーブルの金額単位サンプルのサイズを計算
次の図は、金額単位サンプリングのサンプル サイズを計算するときの入力値と出力結果の例です。
- 取引金額フィールドの絶対値は、$46,400,198.71 ドルです
- Materiality は絶対値の 3% 未満に設定されます
- 推定合計誤謬は絶対値の 1% 未満に設定されます
- 必要なサンプル サイズは 219 レコードです
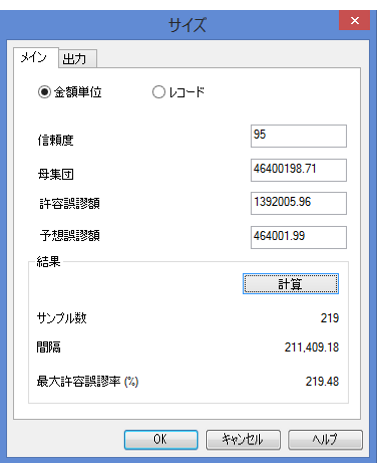
計算は、Invoices テーブルに基づきます。このテーブルは ACL_Rockwood.acl (ACL DATA\Sample Data Files\ACL_Rockwood\ACL_Rockwood.acl) にあります。
最大許容汚染(%)
メモ
Analytics で評価機能を使用する予定がある場合は、最大許容汚染 (%)によって報告される値を使用する必要はありません。代わりに、評価機能で計算される上限逸脱率を使用します。詳細については、金額単位サンプルの誤謬を評価するを参照してください。
最大許容汚染(%)は、母集団の虚偽表示を評価する 1 つの方法です。
この方法を使用する場合は、サンプリングされたデータで監査手順を開始する前に、Analytics が報告したしきい値が事前に分かっています。手順の実行中に観察された累積誤謬がしきい値を超える場合、サンプル フィールドに重大な虚偽表示があることがその時点で分かっています。
例
売掛金テーブルでは、簿価 $1000 が実際には $930 であることがわかります。虚偽表示金額では、汚染は、虚偽表示が表す簿価の割合です。
| 簿価 | 監査値 | 過大申告 | 汚染 |
|---|---|---|---|
| $1,000 | $930 | $70 | 7% (70/1000) |
サンプリングされたデータで独立した手順を実行した後、任意の虚偽表示金額からすべての個別の汚染割合を合計できます。汚染割合の合計が Analytics が報告した最大許容汚染(%)以下の場合は、サンプル フィールドの金額全体が、指定した信頼度レベルに対して重大な虚偽表示があると見なすことができます。
例
売掛金テーブルで 3 つの虚偽表示金額を見つけます。これは、次の汚染と合計汚染割合になります。
| 簿価 | 監査値 | 過大申告 | 汚染 |
|---|---|---|---|
| $1,000 | $930 | $70 | 7% (70/1000) |
| $2,500 | $1,500 | $1000 | 40% (1000/2500) |
| $2,750 | $2,695 | $55 | 2% (55/2750) |
| 49%(合計汚染割合) |
テーブルのサンプル サイズを計算したときに Analytics が報告した最大許容汚染(%)が 92.30% であったとします。汚染割合の合計が最大許容汚染 49% は 92.30% 未満であるため、サンプル フィールドの金額全体が、指定した信頼度レベルに対して重大な虚偽表示があると見なすことができます。
メモ
最大許容汚染(%)を使用した評価は、Analytics の評価機能よりも少し厳密です。
汚染割合の合計がわずかに最大許容汚染(%)値を超えている場合は、評価機能を使用し、サンプル フィールドが実際に重大な虚偽表示であることを確認してください。
詳細については、金額単位サンプルの誤謬を評価するを参照してください。
Analytics によって生成されるサンプル サイズの統計上の有効性
Analytics は、ほとんどの分析に対して、統計上有効なサンプル数のサンプルを抽出できます。ただし、以下の状況は例外となる可能性があります。
- 1000 レコードより少ないデータ セットのサンプリングを行なっている場合
- 組織内に、必要に応じて正確なサンプル数を定義できるサンプリングの専門家がいる場合
- 組織の方針により、ほかのサンプリング ツールまたはサンプリング手法を使用する場合
ポワソン分布と二項分布
サンプル数を生成する際、一般的に使用される 2 つの方法は、ポワソン分布と二項分布です。Analytics では、ポワソン分布によりサンプル数が生成されます。
データ セットの大きさが標準的な 1000 件以上のレコードである場合は、ポワソン分布および二項分布により生成されるサンプル数はほぼ同じになります。データ セットが 1000 件未満のレコードである場合、ポワソン分布により決定されるサンプル数は二項分布により決定される数と比べてやや大きくなる傾向にあり、そのためより控えめになります。データ セットが小さい場合、二項分布ではサンプル数が下方修正されるのに対し、ポワソン分布では下方修正されません。データ セットが非常に小さい場合には、ポワソン分布により生成されるサンプル数が実際にデータ セットのサイズを超過する場合があります。
Analytics でサンプル数を計算するときに、小さいデータ セットのレコード サンプリングを行う場合は、サンプル数が必要以上に大きくなることがあります。このことは分析の障害にはなりません。これは、小さい母集団に対して手動でオーバー サンプリングを行う場合にはよくあることです。