About fuzzy duplicates
Fuzzy duplicates are nearly identical character values that may refer to the same real-world entity. For example, the following four values may all be the same company:
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intrecity Couriers
Common causes of fuzzy duplicates are data entry errors such as typos and misspellings, differing methods of formatting data, and differing data entry conventions. The intentional creation of nearly identical values may indicate fraud. Fuzzy duplicates impede data analysis, which relies upon data referencing real-world entities in a consistent manner.
You can test individual character fields in a table to identify any fuzzy duplicates in a field, and produce output results that group fuzzy duplicates based on a degree of difference that you specify. The fuzzy duplicate groups provide you with a starting point. You will probably need to perform additional analysis, such as a duplicates test of fields associated with the fuzzy duplicates test field, to determine if any of the members of a group do in fact reference the same real-world entity.
The fuzzy duplicates test field can contain letters, numbers, and special characters, which allows you to test values such as names of people and companies, addresses, and social security numbers and product numbers, if the numbers are formatted as character data.
The fuzzy duplicates feature does not support fuzzy joins, or a fuzzy comparison of values in two separate fields or two separate tables.
Fuzzy duplicate output results
The example below shows the output results produced by testing for fuzzy duplicates in the Last Name field of a table.
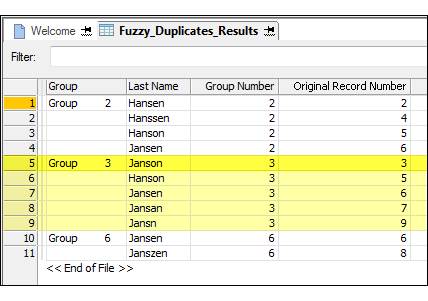
The output results are arranged in groups. The Original Record Number of the first fuzzy duplicate in each group is used to identify the group. For example, “Janson” is the last name in record number 3 in the original table, and because “Janson” is the first value in the group, based on record sequence in the original table, the group is identified as Group 3. For more information, see How fuzzy duplicates are grouped.
Character-based comparison
When comparing two values, the fuzzy duplicates feature performs a character-based comparison, not a word-based comparison. The feature treats blanks or spaces between words as characters, and does not differentiate between individual words. Regardless of the number of individual words in a value, the feature treats the value as a single, unbroken string of characters.
The implication of this approach is that some values that appear to be fuzzy duplicates may not be included in the output results, based on the nature of the data and the difference settings you specify in the Fuzzy Duplicates dialog box. Consider the following examples:
- “JW Smith” and “John William Smith”
- “Diamond Tire” and “Diamond Tire & Auto”
The first example could be two versions of the same name, one using initials and the other using spelled-out first and middle names. The second example could be a short version and a longer version of a company name. However, neither of these pairs will be returned as fuzzy duplicates unless the difference settings are set quite loosely, which would have the adverse effect of also returning large numbers of false positives. The fuzzy duplicates feature processes each pair in the examples as simply two strings of characters. In each case, because the two strings differ significantly in length, the two strings are significantly different from each other when considered at the character level.
For more information, see How the difference settings work.
Additional information about fuzzy duplicates
Testing a field for fuzzy duplicates does not require that the field is sorted, and sorting a field in advance of testing does not assist the fuzzy duplicates operation in any way. However, you may choose to sort a test field in advance because it can make the output results easier to scan, and the Fuzzy Duplicates dialog box does not include the Presort option.
When testing for fuzzy duplicates, you can optionally include exact duplicates in the output results. If you are interested in finding only exact duplicates, use the duplicates feature instead.