区切り文字付きテキスト ファイルのインポート
区切り文字付きテキスト ファイルを分析のために Analytics にインポートするには、多種多様なツールを使用することができます。
機能の仕組み
データ定義ウィザードを使用することで、1 つまたは複数の区切り文字付きテキスト ファイルを選択してそのデータを Analytics にインポートできます。 インポートされたデータを基に、1 つまたは複数の新しい Analytics テーブルおよび関連するデータ ファイル(.fil)が作成されます。 インポートした個々の区切り文字付きテキスト ファイルは、個別の Analytics テーブルとなります。
Analytics データ ファイルには、元の区切り文字付きテキスト ファイルから完全に独立した、区切り文字付きデータのコピーが格納されます。
お使いのローカル コンピューターまたはネットワーク ドライブにある区切り文字付きテキスト ファイルをインポートできます。 Analytics Exchange のユーザーは、Analytics サーバーにある区切り文字付きテキストにもアクセスできます。
1 つのファイルのインポートと複数のファイルのインポート
1 つの区切り文字付きテキスト ファイルをインポートすることも、複数の区切り文字付きファイルを 1 回の操作でインポートすることもできます。 どちらのオプションを使用するかによって、インポート処理が多少異なってきます。
- 1 つのファイル インポート処理時に、ファイル レベルのプロパティとフィールド レベルのプロパティをどちらも手動で定義することができます。
- 複数のファイル インポート処理時にファイル レベルのプロパティのみを手動で定義することができます。 フィールド レベルのプロパティは、Analytics により自動的に定義されるため、インポート時に手動で定義することはできません。
たとえば、複数のファイルのインポート時に以下を行うことはできません。
- フィールドのデータ型の指定
- インポート対象からフィールドを選択的に除外する
データを Analytics にインポート後、データ定義を[テーブル レイアウト]ダイアログ ボックスで必要に応じて調整することができます。
複数のファイルの結合
複数の区切り文字付きテキスト ファイルを個々の Analytics テーブルにインポート後に、それらを 1 つの Analytics テーブルとして結合できます。 たとえば、12 個の月次テーブルのデータをすべてのデータを含む単一の年次テーブルに結合できます。 ファイルを結合できるのは、それらのファイルを個別の Analytics テーブルにインポートした後に限ります。
複数の Analytics テーブルを結合する方法については、テーブルの追加 を参照してください。
ヒント
作業を減らすには、新しい結合されたテーブルでデータ定義に必要な調整を行う前に、複数のテーブルを結合してみてください。
区切り文字付きのテキスト ファイルの構造化
区切り文字付きテキスト ファイルのファイル拡張子は通常、.txt または .csv ですが、他のファイル拡張子も使用できます。 区切り文字付きテキスト ファイルは、主にスプレッドシートやデータベース アプリケーションからデータを Analytics にインポートするために使用します。 データベースまたはスプレッドシートの各行はそれぞれ区切り文字付きテキスト ファイルの 1 行となり、各行または各レコードが行区切り文字で区切られます。 有効な行区切り文字:
- CR キャリッジ リターン
- LF 改行
- CRLF キャリッジ リターン改行(標準 DOS/Windows 文字シーケンス)
フィールド区切り文字
区切り文字付きテキスト ファイルの各レコードのフィールドはフィールド区切り文字で区切られます。 主に 3 種類の区切り文字付きファイルがあります。これらはそれぞれ使用する次のようなフィールド区切り文字に基づいています。
- カンマ区切り(.csv) – 各レコード内のフィールドを区切るためにカンマが使用されます。
- タブ区切り – 各レコード内のフィールドを区切るためにタブが使用されます。
- テキスト ファイル(.txt) – カンマ、タブ、または別のフィールド区切り文字が、各レコードのフィールドを区切るために使用されます。 その他、一般的なフィールド区切り文字にはスペース、パイプ(|)およびセミコロン(;)があります。
テキスト修飾子文字
フィールド区切り文字が使用されている場合、テキスト修飾子文字を使用して文字フィールド値を囲み、その値をフィールド区切り文字と区別します。 一般的なテキスト修飾子は二重引用符(" ")または一重引用符(' ')です。
たとえば、カンマがフィールド区切り文字の場合に、値 $1,000 をテキスト修飾子で囲んで "$1,000" とすると、元の値は、2 つの値($1 と 000)ではなく、単一の値として解釈されます。
区切られたテキスト ファイル
次の例では、区切り文字付きテキスト ファイルの最初の 4 件の行を表示します。
- 最初の行にはフィールド名が格納されています。
- フィールド区切り文字はカンマです。 各行には 7 つのフィールドがありカンマで区切られています。
- テキスト修飾子は二重引用符です。 各行の最後のフィールドにはテキスト修飾子があり、ドルの値に含まれるカンマはフィールド区切り文字としては解釈されません。
First_Name,Last_Name,CardNum,EmpNo,HireDate,Salary,Bonus_2011 Lila,Remlawi,8590122497663807,000008,12/28/2007,52750,"$1,405.40" Vladimir,Alexov,8590122281964011,000060,10/5/2007,41250,"$4,557.43" Alex,Williams,8590124253621744,000104,8/12/2010,40175,"$7,460.02"
上書きの動作
区切り文字付きデータをインポートし、Analytics プロジェクト内の既存のテーブルと同じ名前を持つ新しい Analytics テーブルを作成する場合は、その既存のテーブルが上書きされます。
上書きされるテーブルの 2 つの部分
Analytics テーブルの上書きは、テーブルの以下の 2 つの部分が上書きされるため、複雑です。
- テーブル レイアウト。これはナビゲーターに表示される部分です。
- 関連するソース データ ファイル。これは Windows フォルダーに保存されている部分です
(テーブル レイアウトとソース データ ファイルについては、Analytics テーブルの構造を参照してください)。
テーブルのこれら 2 つの部分は、互いとは関係なく上書きされます。 これら 2 つの部分が新しいテーブルの対応する部分と同じ名前を持っている場合には、古い方の 2 つの部分が両方とも上書きされます。 このシナリオは最も一般的です。
これに対し、テーブル レイアウトまたはソース データ ファイルが新しいテーブルの対応する部分と異なる名前を持つ場合は、新しいテーブルの対応する部分と同じ名前を持つ部分のみが上書きされます。
この上書き動作は、インポートする区切り文字付きテキスト ファイルが 1 つか複数かに関係なく該当します。
複数の区切り文字付きテキスト ファイルをインポートする場合の上書き
複数の区切り文字付きテキスト ファイルをインポートする場合、上書きの動作は[既存のテーブルを上書きする]設定と[出力パス]設定によって変わります。
以下のセクションでは、複数の区切り文字付きテキスト ファイルをインポートする場合にあり得るさまざまな上書き結果をまとめます (最も一般的なシナリオから説明します)。
名前が同じ:新しいテーブル、既存のテーブル レイアウト、既存のソース データ ファイル
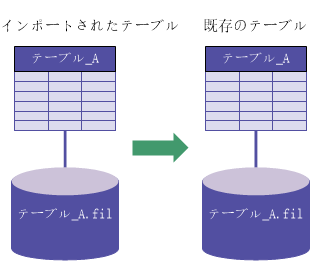
|
「出力パス」が既存のソース データ ファイルと同じ |
「出力パス」が既存のソース データ ファイルと異なる |
|
|---|---|---|
| [既存のテーブルを上書きする]がオン |
|
|
| [既存のテーブルを上書きする]がオフ |
|
|
名前が異なる:既存のテーブル レイアウト
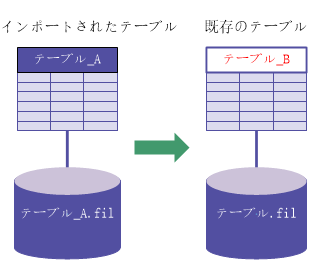
|
「出力パス」が既存のソース データ ファイルと同じ |
「出力パス」が既存のソース データ ファイルと異なる |
|
|---|---|---|
| [既存のテーブルを上書きする]がオン |
|
|
| [既存のテーブルを上書きする]がオフ |
|
|
名前が異なる:既存のソース データ ファイル
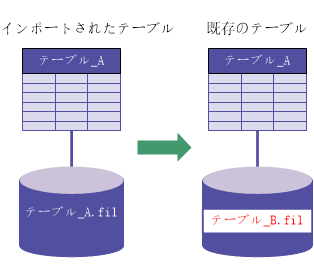
|
「出力パス」が既存のソース データ ファイルと同じ |
「出力パス」が既存のソース データ ファイルと異なる |
|
|---|---|---|
| [既存のテーブルを上書きする]がオン |
|
|
| [既存のテーブルを上書きする]がオフ |
|
|
1 つの区切り文字付きテキスト ファイルのインポート
1 つの区切り文字付きテキスト ファイルをインポートして新しい Analytics テーブルを作成します。 インポート処理時に、ファイル レベルのプロパティとフィールド レベルのプロパティをどちらも手動で定義することができます。
1 つの区切り文字付きファイルの検索と選択
- [インポート > ファイル] を選択します。
- [定義するファイルの選択]ダイアログ ボックスで、区切り文字付きテキスト ファイルを探して選択し、[開く]をクリックします。
区切り文字付きテキスト ファイルには、.txt や .csv など、複数の異なるファイル拡張子を使用できます。
区切り文字付きファイルのプロパティの指定
- [文字セット]ページで、正しい文字セット オプションが選択されていることを確認し、[次へ]をクリックします。
- [ファイル形式]ページで、[区切り文字付きテキスト ファイル]オプションが選択されていることを確認し、[次へ]をクリックします。
- [区切り文字付きファイルのプロパティ]ページで、Analytics によって、以下に一覧されたプロパティへと割り当てられた設定をレビューし、必要な更新を行い、[次へ]をクリックします。
プロパティ 説明 開始する行 ファイルの読み取りを開始する行番号。
この設定により、インポートしない情報を含むファイルが始まる行をスキップできます。 たとえば、ファイルの先頭 3 行にヘッダー情報が含まれている場合、4 行目からデータの読み取りを開始するには、「4」と入力します。
フィールド幅 プレビュー テーブルの選択された列見出しに、結果として得られるテーブル レイアウトのフィールド長を指定します。 文字で長さを指定します。
Analytics で割り当てられた長さを保持するか、別の長さを入力することができます。
メモ
最大フィールド長は 32,767 文字(非 Unicode エディションの場合)または 16,383 文字(Unicode エディションの場合)です。 上限までのフィールド長全体が Analytics にインポートされますが、テーブル ビューに表示されるのは最初の 256 文字だけです。 残りのデータも存在していて分析できますが、ビューには表示されません。 データ全体を表示するには、[テーブル レイアウト]ダイアログ ボックスを開きます。
ヒント
更新されたソース データから結果として得られる Analytics テーブルを定期的に更新する、またはインポート コマンドを再利用する予定である場合は、Analytics によって割り当てられたものより長いフィールド長を入力します。
ソース データの更新された値が現在のいずれかの値より長い場合は、それより長いフィールド長によって余分のスペースが与えられます。 利用可能なフィールド長を超える値は切り詰められます。
先頭の行をフィールド名として使用する ファイルの 1 行目の値は、生成されるテーブル レイアウトのフィールド名として使用されます。 メモ
この設定を使用する場合、フィールド名として使用される行は、行番号が[開始する行]で指定される行です。 フィールド名が正しくない場合は、[データ定義ウィザード]の後続ページで更新できます。
連続した修飾子は 1 文字として扱う 重複する修飾文字が無視されます。 たとえば、"ACL Services Ltd. dba Galvanize""(2 つの二重引用符で終わっています)は、このオプションがオンの場合には、"ACL Services Ltd. dba Galvanize" と同等になります。
フィールドの区切り文字 ファイルのフィールドを区切る文字であり、以下のものがあります。 - カンマ
- TAB
- セミコロン
- その他 – フィールドの区切り文字として使用する文字を指定することができます。
テキスト修飾子 フィールドに含まれる値を特定するテキスト記号であり、以下のものがあります。 - 二重引用符
- 引用符
- なし – テキスト修飾子が使用されないことを示します
- その他 – テキスト修飾子として使用する文字を指定できます。
キャリッジ リターンの削除およびライン フィードの削除 キャリッジ リターン(CR)やライン フィード(LF)文字の配置が誤ってインポートされたデータをクレンジングします。 CR/LF の配置が正しくないと、レコード内の改行が正しくなくなる可能性があります。 有効化されると、このオプションは CR/LF 文字をスペースで置き換えます。 テキスト修飾子のペアの中に発生する CR/LF 文字のみが置き換えられます。
Windows ファイルの場合、[キャリッジ リターンの削除]と[ライン フィードの削除]の両方を選択します。
[テキスト修飾子]が "なし" である場合は、これら 2 つのオプションは無効になっています。
すべての文字タイプ(「すべて文字型」の意) インポートされたすべてのフィールドに文字データ型を割り当てます。 ヒント
インポートされたすべてのフィールドに文字データ型を割り当てると、区切り文字付きテキスト ファイルのインポート処理が容易になります。
Analytics にインポートされたデータのフィールドには、数値や日付時刻などのさまざまなデータ型を割り当て、書式の詳細を指定することができます。
[すべての文字]オプションは、実際に文字データ型を使用する必要がある場合に、Analytics によって数値のデータ型が自動的に割り当てられた、識別子のフィールドを持つテーブルをインポートする際に有用となります。
NULL の置換 誤って配置されて NUL 文字がインポートされたデータをクレンジングします。 NUL 文字の配置が正しくないと、レコード内でギャップが生じ、フィールドの分割が正しくなくなる可能性があります。 有効化されると、このオプションは NUL 文字をスペースで置き換えます。
Analytics データ ファイルの保存
[データ ファイルを別名で保存]ダイアログ ボックスで、Analytics データ ファイルの名前を入力して[保存]をクリックします。
Analytics によってデータ ファイル名があらかじめ設定されている場合は、その設定されている名前を受け入れることも、あるいは変更することもできます。
Analytics によって開かれたデフォルトのロケーションを使用しない場合は、異なるフォルダーに移動して、データ ファイルを保存することもできます。
Analytics フィールド プロパティの編集
[フィールド プロパティの編集]ページで、Analytics によって、以下に一覧されたプロパティへと割り当てられた設定をレビューし、必要な更新を行い、[次へ]をクリックします。
メモ
列に関連付けられたプロパティを確認するには、プレビュー テーブルで列見出しを選択します。
| プロパティ | 説明 |
|---|---|
| このフィールドを無視する | 結果として得られるテーブル レイアウトからフィールドを除外します。 このフィールドのデータは、インポートは行われますが、定義されないため、新しい Analytics テーブルには表示されません。 必要に応じ、あとで定義して、テーブルに追加することができます。 |
| 名前 | テーブル レイアウトのフィールド名。 Analytics で割り当てた名前をそのまま使用するか、別の名前を入力します。 |
| 列見出し | デフォルトの Analytics ビューにおけるフィールドの列見出し。 列見出しを指定しない場合は、[名前]の値が使用されます。 |
|
メモ [区切り文字付きファイルのプロパティ]ページで[すべての文字]を選択した場合、以下のオプションは適用されず、無効になります。 |
|
| 型 | 作成される Analytics テーブルのフィールドに割り当てられるデータ型。 Analytics によって割り当てられたデータ型を保持するか、ドロップダウン リストから適切なデータ型を選択することができます。 Analytics でサポートされているデータ型の詳細については、Analytics のデータ型を参照してください。 |
| 値 | フィールドの最初の値を表示する読み取り専用プロパティ。 この値は、行う編集に基づき動的に更新します。 |
| 10 進型(Decimal) | 数値フィールドのみ。 ソース データの小数点以下桁数。 メモ [小数位]テキスト ボックスは、数値のデータ型を選択すると自動的に表示されます。 |
| 入力形式 | 日付時刻フィールドのみ。 ソース データの日付時刻値の書式。 指定する書式はソース データの書式と正確に一致する必要があります。 日付と時刻の書式の詳細については、ソース データに含まれる日付および時刻データの書式を参照してください。 |
インポートの最終処理
- [最終]ページで、新しい Analytics テーブルの設定を確認したら、[完了]をクリックします。
変更する場合は、[戻る]をクリックし、ウィザードの適切なページへと進みます。
- プロジェクトに追加中のテーブル名を入力するか、デフォルトの名前を保持し、そこで、[OK]をクリックします。
新しい Analytics テーブルは、インポートされたファイルからのデータと一緒に作成されます。
複数の区切り文字付きテキスト ファイルのインポート
1 回の操作で複数の区切り文字付きテキスト ファイルをインポートします。 各区切り文字付きファイルは、Analytics プロジェクトにインポートされると、独立した Analytics テーブルになります。
インポート処理時にファイル レベルのプロパティのみを手動で定義することができます。 フィールド レベルのプロパティは、Analytics により自動的に定義されるため、インポート時に手動で定義することはできません。
データを Analytics にインポート後、データ定義を[テーブル レイアウト]ダイアログ ボックスで必要に応じて調整することができます。
メモ
インポートするファイルのすべての最初の行の内容は、一貫している必要があります。 最初の行は、すべてのファイルにおいて、フィールド名またはデータのいずれかにする必要があります。 1 つのインポート処理で 2 つの内容を混在させないでください。
ファイルの最初の行の内容が一貫していない場合は、2 つの異なるインポート処理を行ってください。
複数の区切り文字付きファイルの検索と選択
- [インポート > ファイル] を選択します。
- [定義するファイルの選択]ダイアログ ボックスで、区切り文字付きテキスト ファイルを探して選択し、[開く]をクリックします。
以下のファイル拡張子を持つ区切り文字付きテキスト ファイルがサポートされています。.txt、.csv、.del、.dat
隣り合う複数のファイルを選択する場合は Shift キーを押しながらクリックし、隣り合っていない複数のファイルを選択する場合は Ctrl キーを押しながらクリックします。
最初のインポート準備を行う
- [区切り文字付きファイルのプロパティ]ページで、インポートするファイルを選択します。
デフォルトで選択されているファイルをそのまま使用することも、インポートしたくない任意のファイルを選択解除することもできます。 すべてのファイルを選択解除するか選択する場合は、最初のチェック ボックスをオンにします。
- Analytics によって割り当てられた設定を確認し、必要な更新を行って、[次へ]をクリックします。
設定 説明 テーブル名 Analytics プロジェクト内のテーブルの名前。
Analytics によって割り当てられた名前を保持します。または、テーブル名をダブルクリックし、別の名前を入力して Enter キーを押します。
メモ
このテーブル名は、データをインポートする際に作成された新しいテーブル レイアウトと新しいソース データ ファイルの両方に適用されます。
既存のテーブルを上書きする Analytics プロジェクト内の同名の既存テーブルが上書きされます。
詳細については、上書きの動作を参照してください。
出力パス 新しい Analytics データ ファイル(.fil)を保存するフォルダーを指定します。
[出力パス]を空白のままにした場合には、 Analytics データ ファイルは Analytics プロジェクトが格納されているフォルダーに保存されます。
- "既存のファイルまたはテーブル名が検出されました" というエラーメッセージが表示されたら、[OK]をクリックし、以下のいずれかまたは両方を行います。
- 既存のテーブル レイアウトまたは同名の関連するデータ ファイルを上書きしても構わない場合は、[既存のテーブルを上書きする]をオンにします。
- 既存の任意のテーブル レイアウトまたは関連するデータ ファイルが上書きされないように、インポートするテーブルの名前を[テーブル名]の設定で必要に応じて変更します。
-
[確認]ダイアログ ボックスにおいて、続行する場合は[はい]、戻ってファイルの選択を変更する場合は[いいえ]をクリックします。
区切り文字付きファイルのプロパティの指定
メモ
指定したプロパティは、インポートするすべてのファイルに適用されます。 ファイルの構造が一貫していない場合は、一部のファイルのプロパティが不正になるため、インポートで問題が発生します。
- [区切り文字付きファイルのプロパティ]ページで、Analytics によって、以下に一覧されたプロパティへと割り当てられた設定をレビューし、必要な更新を行い、[次へ]をクリックします。
プロパティ 説明 開始する行 ファイルの読み取りを開始する行番号。
この設定により、ファイルの前半にある、インポートしたくない情報が含まれる行をスキップできます。 たとえば、各ファイルの先頭 3 行にヘッダー情報が含まれている場合、4 行目からデータの読み取りを開始するには、「4」と入力します。
フィールド幅 プレビュー テーブルの選択された列見出しに、結果として得られるテーブル レイアウトのフィールド長を指定します。 文字で長さを指定します。
Analytics で割り当てられた長さを保持するか、別の長さを入力することができます。
メモ
最大フィールド長は 32,767 文字(非 Unicode エディションの場合)または 16,383 文字(Unicode エディションの場合)です。 上限までのフィールド長全体が Analytics にインポートされますが、テーブル ビューに表示されるのは最初の 256 文字だけです。 残りのデータも存在していて分析できますが、ビューには表示されません。 データ全体を表示するには、[テーブル レイアウト]ダイアログ ボックスを開きます。
ヒント
更新されたソース データから結果として得られる Analytics テーブルを定期的に更新する、またはインポート コマンドを再利用する予定である場合は、Analytics によって割り当てられたものより長いフィールド長を入力します。
ソース データの更新された値が現在のいずれかの値より長い場合は、それより長いフィールド長によって余分のスペースが与えられます。 利用可能なフィールド長を超える値は切り詰められます。
先頭の行をフィールド名として使用する 各ファイルの 1 行目の値は、生成されるテーブル レイアウトのフィールド名として使用されます。
メモ
この設定を使用する場合、フィールド名として使用される行は、行番号が[開始する行]で指定される行です。
この設定は、インポートするすべてのファイルにグローバルに適用されます。
連続した修飾子は 1 文字として扱う 重複する修飾文字が無視されます。
たとえば、"ACL Services Ltd. dba Galvanize""(2 つの二重引用符で終わっています)は、このオプションがオンの場合には、"ACL Services Ltd. dba Galvanize" と同等になります。
フィールドの区切り文字 ファイルのフィールドを区切る文字であり、以下のものがあります。
- カンマ
- TAB
- セミコロン
- その他 – フィールドの区切り文字として使用する文字を指定することができます。
テキスト修飾子 フィールドに含まれる値を特定するテキスト記号であり、以下のものがあります。
- 二重引用符
- 引用符
- なし – テキスト修飾子が使用されないことを示します
- その他 – テキスト修飾子として使用する文字を指定できます。
キャリッジ リターンの削除およびライン フィードの削除 キャリッジ リターン(CR)やライン フィード(LF)文字の配置が誤ってインポートされたデータをクレンジングします。
CR/LF の配置が正しくないと、レコード内の改行が正しくなくなる可能性があります。 有効化されると、このオプションは CR/LF 文字をスペースで置き換えます。 テキスト修飾子のペアの中に発生する CR/LF 文字のみが置き換えられます。
Windows ファイルの場合、[キャリッジ リターンの削除]と[ライン フィードの削除]の両方を選択します。
[テキスト修飾子]が "なし" である場合は、これら 2 つのオプションは無効になっています。
すべての文字タイプ(「すべて文字型」の意) インポートされたすべてのフィールドに文字データ型を割り当てます。
ヒント
インポートされたすべてのフィールドに文字データ型を割り当てると、区切り文字付きテキスト ファイルのインポート処理が容易になります。
Analytics にインポートされたデータのフィールドには、数値や日付時刻などのさまざまなデータ型を割り当て、書式の詳細を指定することができます。
[すべての文字]オプションは、実際に文字データ型を使用する必要がある場合に、Analytics によって数値のデータ型が自動的に割り当てられた、識別子のフィールドを持つテーブルをインポートする際に有用となります。
NULL の置換 誤って配置されて NUL 文字がインポートされたデータをクレンジングします。
NUL 文字の配置が正しくないと、レコード内でギャップが生じ、フィールドの分割が正しくなくなる可能性があります。 有効化されると、このオプションは NUL 文字をスペースで置き換えます。
インポートの最終処理
[最終]ページで、新しい Analytics テーブルの設定を確認したら、[完了]をクリックします。
変更する場合は、[戻る]をクリックし、ウィザードの適切なページへと進みます。
新しい Analytics テーブルは、インポートされたファイルからのデータを使って作成されます。