Información de concepto
La agrupación de registros en clústeres agrupa los registros de una tabla según los valores similares en uno o más campos numéricos. Los valores similares son aquellos que son cercanos entre sí en el contexto del conjunto de datos completo. Estos valores similares representan clústeres que, una vez identificados, revelan patrones en los datos.
Nota
Si desea que la agrupación de registros sea una parte habitual de su programa de análisis, le recomendamos que complete el curso Encontrar grupos de datos utilizando el comando CLUSTER en Analytics (ACL 361) (se necesita iniciar sesión).
Diferencia entre la agrupación en clústeres y otros comandos de agrupación de Analytics
La agrupación en clústeres se diferencia de otros comandos de agrupación de Analytics:
- Para la agrupación de registros, no es necesario agrupar por categorías de datos preexistentes, como tipo de transacción o código de categoría de comerciante, ni por estratos predefinidos con límites numéricos estrictos. Por el contrario, la agrupación en clústeres agrupa los datos según los valores numéricos similares dentro de los propios datos; es decir, valores cercanos entre sí.
- La agrupación en clústeres por más de un campo envía resultados que no están anidados (no son jerárquicos).
Elección de los campos para hacer clústeres
La agrupación de datos en clústeres le permite descubrir agrupamientos orgánicos en los datos que, de otra manera, tal vez no sabría que existen. En particular, la agrupación en clústeres en varios campos numéricos (clústeres de varias dimensiones) sería difícil de identificar sin la ayuda del aprendizaje automático. En este sentido, la agrupación en clústeres es exploratoria, y es un ejemplo de aprendizaje automático sin supervisión.
Sin embargo, para que los clústeres que se generan tengan sentido, debe existir una relación significativa entre los campos que seleccione para la agrupación de los datos.
Agrupación en clústeres por un único campo
La agrupación en clústeres por un único campo numérico es relativamente directa. Usted se centra en un conjunto de valores único y la agrupación en clústeres agrupa los valores según la cercanía o proximidad que existe entre ellos. Por ejemplo, puede agrupar en clústeres un campo de importe para determinar dónde se concentran los importes en el rango de valores.
La ventaja de la agrupación en clústeres por sobre un enfoque tradicional como la estratificación es que no es necesario hacer suposiciones por adelantado acerca de dónde pueden encontrarse las concentraciones, ni crear límites numéricos arbitrarios. La agrupación en clústeres descubre dónde se encuentran los límites de una cantidad determinada de clústeres.
Ejemplo de agrupación de datos en un único campo numérico
Usted agrupa en clústeres la tabla Ap_Trans en el campo Invoice Amount (Importe de la factura) para determinar dónde se concentran los importes en el rango de valores. Usted espera que la mayoría de los importes se agrupen en el extremo inferior del rango. La agrupación de los datos en clústeres confirmará si el patrón que usted espera encontrar es el que realmente existe.
Decide agrupar el campo Invoice Amount en cinco clústeres y después resumir los clústeres para determinar cuántos registros hay en cada clúster.
Resultados de la salida
En los resultados de la salida que se muestran a continuación, los primeros cinco registros son generados por el sistema y coinciden con el número deseado de clústeres que usted especificó. En el campo Invoice Amount, los cinco registros muestran el centroide, o punto central, que el algoritmo de agrupación en clústeres calcula para cada uno de los cinco clústeres con los importes de las facturas. Por ejemplo, el centroide del clúster 3 ( C3 ) es 2,969.04. Si desea obtener más información, consulte Cómo funciona el algoritmo de agrupación en clústeres.
Debajo de los campos generados por el sistema, se encuentran los campos de datos de origen agrupados en clústeres, comenzando por el clúster 0. El valor del campo Distance (Distancia) es la distancia desde el importe real de la factura hasta el centroide calculado para ese clúster. Así, por ejemplo, en el registro 6, el importe de la factura de 618.30 menos la distancia de 64.935317 equivale al valor centroide de 553.36.
Nota
Debe restar o sumar el valor de la distancia, según si el valor real es mayor o menor que el valor del centroide.
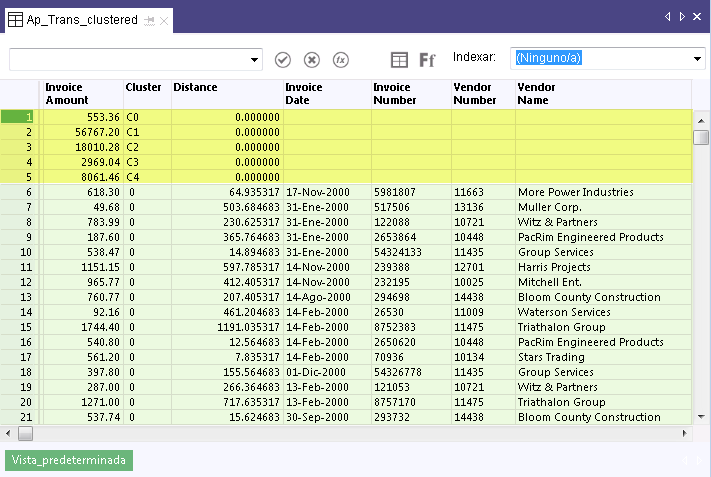
Resumen de los clústeres
Si resume el campo Cluster y ordena la salida resumida por recuento, obtiene los siguientes resultados, que confirman que la distribución de los valores es la que esperaba. En general, los importes de las facturas están fuertemente sesgados a los valores inferiores. (Se agregan los valores centroides a la tabla para facilitar la comparación).
El único valor elevado de un clúster aparece por sí solo como un valor atípico y es probable que se deba investigar.
| Clúster | Recuento | Valor centroide |
|---|---|---|
| 0 | 73 | 553.36 |
| 3 | 16 | 2,969.04 |
| 4 | 8 | 8,061.46 |
| 2 | 4 | 18,010.28 |
| 1 | 1 | 56,767.20 |
Agrupación en clústeres en varios campos
Cuando se hace una agrupación en clústeres de dos o más campos, debe preguntarse cómo podrían relacionarse los campos. Puede usar la agrupación en clústeres para comprobar una hipótesis. Por ejemplo, una compañía podría estar preocupada por la tasa de rotación de empleados, que la gerencia considera está concentrada entre los empleados de menor edad y menor salario.
Podría utilizar la agrupación en clústeres para descubrir si existe una fuerte relación entre lo siguiente:
- tiempo de retención del empleado y edad del empleado (agrupación en clústeres de dos dimensiones)
- tiempo de retención del empleado, edad del empleado y salario (agrupación en clústeres de tres dimensiones)
Nota
Para este análisis, necesita evitar incluir campos que no se relacionen claramente con la hipótesis, como cantidad de días de licencia por enfermedad.
Evaluación de los clústeres de salida
El algoritmo de agrupación en clústers siempre generará una tabla con la cantidad específica de clústeres. Cada registro de la tabla de salida se encontrará en un clúster.
En este punto, necesita evaluar si los clústeres tienen significado o sentido para el análisis. Solo porque el algoritmo agrupe registros en un clúster, no necesariamente significa que la agrupación es significativa. Debe preguntarse si los clústeres forman un patrón significativo. ¿Cuentan una historia?
Consejo
La manera más sencilla de evaluar rápidamente la naturaleza global de los clústeres de la salida consiste en graficar la tabla de salida de clústeres como un diagrama de dispersión con una herramienta de generación de reportes, que asigne un color a cada clúster.
Las siguientes características pueden ayudarlo a evaluar el significado de los clústeres de la salida:
- Coherencia de los clústeres ¿Los valores individuales de un cluster se encuentran relativamente cerca del centroide o el clúster es algo difuso? Cuanto mayor sea la coherencia de un clúster, más fuerte será la relación entre los valores que lo conforman.
- Tamaño del clúster ¿La mayoría de los valores se encuentran en uno o dos clústeres de gran tamaño? Si es así, el conjunto de datos está significativamente sesgado si se lo compara con un conjunto de datos en el cual los valores están distribuidos de forma relativamente pareja entre los diferentes clústeres.
- Valores atípicos Considere los valores que no es posible incluir en ninguno de los clústeres significativos. Estos valores atípicos pueden representar elementos que ameritan un escrutinio adicional. Considere también los "valores atípicos internos"; es decir, los valores que se incluyen en un clúster significativo, pero se encuentran en el extremo del clúster.
Nota
Las características anteriores son todos métodos subjetivos o humanos para evaluar clústeres. Existen varios métodos matemáticos para evaluar clústeres, pero eso excede el alcance de la Ayuda de Analytics.
Cómo funciona el algoritmo de agrupación en clústeres
La agrupación en clústeres de Analytics utiliza el algoritmo de Agrupamiento con K-Means, que es un algoritmo de aprendizaje automático muy conocido. Puede encontrar una descripción detallada de Agrupamiento con K-means en Internet.
A continuación, se incluye un resumen del algoritmo.
El algoritmo de Agrupamiento con K-Means utiliza un proceso de repetición para optimizar los clústeres:
| 1 | Especifique la cantidad de clústeres |
|
|---|---|---|
| 2 | Inicialice los centroides del clúster |
|
| 3 | Asigne cada punto de datos al centroide más cercano |
|
| 4 | Vuelva a calcular los centroides |
|
| 5 | Repita |
|
Elección de la cantidad de clústeres (Valor K)
Determinar la cantidad óptima de clústeres que se deben utilizar al agrupar datos en clústeres puede llevar un poco de tiempo y experimentación. No existe una respuesta exacta para un conjunto de datos determinado.
Recomendaciones para determinar la cantidad óptima de clústeres:
- Familiarícese con los datos Familiarícese con los datos para tener una idea general del perfil de los datos y de cualquier concentración obvia de valores.
- Comience con valores elevados Escoja un número relativamente elevado de clústeres inicialmente: 8 a 10.
- Pruebe con una cantidad diferente de clústeres Realice la agrupación en clústeres varias veces, especificando un valor K diferente cada vez. Una revisión de los resultados de salida puede ayudarlo a determinar si necesita más o menos clústeres.
- Método del codo Utilice el método del codo para identificar con un programa la cantidad óptima de clústeres. La cantidad óptima es el punto en el que se alcanza la mejor coherencia de los clústeres y al mismo tiempo se evitan las devoluciones reducidas de más clústeres que solo mejoran marginalmente la coherencia, pero a expensas de dividir clústeres que ya eran coherentes.
Puede dibujar los resultados del método del codo en un gráfico de líneas para identificar el "codo", o el punto de inflexión, a partir del cual la cantidad de clústeres no mejora de manera significativa la coherencia.
Puede descargar un script de método del codo desde ScriptHub para utilizarlo en Analytics: Elbow method - Sum of Squared Errors (SSE) for K (Método del codo: suma de los cuadrados del error para K) (es necesario iniciar sesión).
¿Puede utilizar la agrupación en clústeres en campos de caracteres o de fechahora?
En general, no se puede usar la agrupación en clústeres en campos de caracteres o de fechahora. El algoritmo de agrupación en clústeres acepta únicamente números y realiza cálculos con los números (distancia euclídea, media).
Datos de caracteres categóricos
Es posible que tenga datos de caracteres categóricos, como ID de ubicación, que son números. O podría usar un campo calculado para asignar categorías de caracteres a un conjunto de códigos numéricos que usted crea. Podría convertir estos datos en tipos de datos numéricos y usarlos para una agrupación en clústeres. Sin embargo, los clústeres que obtenga no serían válidos porque usted estaría haciendo cálculos matemáticos en números que representan algo que no es numérico.
Por ejemplo, si calcula una posición centroide sobre la base del promedio de una lista de ID de ubicación, obtendrá un número sin ningún significado. El cálculo se basa en la suposición no válida de que la distancia matemática entre los números de ubicación equivale a alguna distancia mensurable del mundo real.
Si consideramos la distancia física, no tiene sentido decir que la distancia entre la ubicación 1 y la 9 es el doble que la distancia entre la ubicación 1 y la 5. Las ubicaciones 1 y 9 podrían estar una junto a la otra, y la ubicación 5 podría estar a kilómetros de distancia.
Para un análisis de agrupación en clústeres de ubicaciones y distancias físicas, los datos válidos que se deben usar son las coordenadas geográficas.
Datos categóricos que representan una escala
Puede agrupar en clústeres los datos categóricos que representan una escala; por ejemplo, una calificación de Mal a Excelente, con códigos numéricos correspondientes de 1 a 5. En este caso, el promedio de los códigos numéricos tendrá sentido.
Datos de fechahora
Puede utilizar las funciones de Analytics para convertir datos de fechahora en datos numéricos. Sin embargo, los datos numéricos que obtenga no son continuos y esto es un problema para el análisis por agrupación en clústeres, que asume que los conjuntos de números son continuos.
Por ejemplo, los siguientes tres números, como fechas, solo tienen una diferencia de un día. Sin embargo, como números, existe una separación o distancia considerable entre el primer número y el segundo.
- 20181130
- 20181201
- 20181202
Podría usar valores de fecha de serie en el análisis por agrupación en clústeres. Las fechas de serie son un conjunto continuo de números enteros que representan la cantidad de días que han transcurrido desde el 01 de enero de 1900.
Pasos
Nota
Si las opciones del menú de aprendizaje automático están desactivadas, es probable que el motor de Python no esté instalado. Si desea obtener más información, consulte Instalar ACL para Windows.
Especificar ajustes para el algoritmo de agrupación en clústeres
- Abra la tabla con los datos que desea agrupar en clústeres.
- Desde el menú principal de Analytics, seleccione Aprendizaje automático > Agrupamiento.
- En Cantidad de clústeres (Valor K), especifique la cantidad de clústeres que desea utilizar para agrupar los datos.
- En Cantidad máxima de iteraciones, especifique el límite superior para la cantidad de iteraciones que realiza el algoritmo de agrupación en clústeres.
- En Cantidad de inicializaciones, especifique la cantidad de veces que se debe generar un conjunto inicial de centroides aleatorios.
- Opcional. Seleccione Semilla e introduzca un número.
Especificar un método de preprocesamiento de los datos
Si agrupa por más de un campo clave, debe usar la función de Preprocesamiento para estandarizar la escala de los campos antes de usarlos para la agrupación en clústeres.
Con frecuencia, los diferentes campos numéricos tienen distintas escalas y unidades. Por ejemplo, un campo de salario que contiene dólares por año podría tener valores que van de 20.000 a 100.000, mientras que un campo de edad que contiene los años podría tener valores del 18 al 70. Si agrupa en clústeres los campos de salario y de edad, sin utilizar una escala, los clústeres de salida serán básicamente clústeres del salario, sesgados por el tamaño de las cifras de los salarios en comparación con los cifras de las edades, en lugar de clústeres de salario/edad.
El preprocesamiento ofrece los métodos que se explican a continuación para escalar todos los valores de todos los campos clave del clúster a fin de que tengan un peso equivalente durante el proceso de agrupación en clústeres.
| Opción de preprocesamiento | Descripción |
|---|---|
| Estandarizar |
Los valores del campo clave se centran en una media de cero (0) y se ajustan a escala. Este proceso convierte los valores en un unidad tipificada (puntuación z o puntuación estándar). La puntuación z o unidad tipificada es una medida de la cantidad de desviaciones estándar que separan a un valor sin procesar de la media sin procesar de cada campo. En el campo ajustado a escala, la media está representada por un cero (0) y las puntuaciones z son positivas o negativas; esto depende de si los valores sin procesar a los que representan son mayores o menores que la media sin procesar del campo. Nota Utilice esta opción si los campos clave contienen, en su mayoría, valores que no son iguales a cero ("matrices densas"). Ejemplo del cálculo de la puntuación zEn un campo de edad ajustado a escala, el valor de edad sin procesar de 55 está representado por una puntuación z de 1,038189.
|
| Escalar a la varianza de la unidad |
Los valores del campo clave se ajustan a escala dividiéndolos por su desviación estándar, pero no están centrados en una media de cero (0). Nota Utilice esta opción si uno o más campos clave contienen una gran cantidad de valores cero (0) ("matrices dispersas"). Ejemplo de ajuste a escala sin centradoEn un campo de edad ajustado a escala, el valor de edad sin procesar de 55 está representado por el valor ajustado a escala de 4,406077.
|
| Ninguno | Los valores del campo clave no se centran ni se ajustan a escala. La agrupación en clústeres utiliza los valores sin procesar, sin centrar ni ajustar a escala, al calcular los clústeres. |
Seleccionar campos
- Desde la lista Agrupar por, seleccione uno o más campos clave a fin de usarlos para agrupar los registros de la tabla en clústeres.
Los campos clave deben ser numéricos.
- Opcional. Desde la lista Otros campos, seleccione uno o más campos adicionales para incluirlos en la tabla de salida.
Consejo
Puede presionar Ctrl+clic para seleccionar varios campos no adyacentes, y Mayús+clic para seleccionar varios campos adyacentes.
Finalizar la entrada de comandos
-
Si hay registros en la vista principal que desee excluir del procesamiento, introduzca una condición en el cuadro de texto Si, o haga clic en Si para crear un enunciado IF usando Generador de expresiones.
Nota
La condición Si se evalúa únicamente con los registros que quedan en una tabla después de aplicar las opciones de alcance (Primeros, Siguientes y Mientras).
El enunciado IF considera todos los registros en la vista principal y filtra los que no cumplan la condición especificada.
- En el cuadro de texto En, especifique el nombre de la tabla de salida.
- Opcional. En la ficha Más:
- Para especificar que se procese solo un subconjunto de registros, seleccione una de las opciones del panel Alcance.
- Seleccione Utilizar la tabla de salida si desea que la tabla de salida se abra automáticamente.
- Haga clic en Aceptar.