Utilisez la fonction Machine Learning automatisée dans Analytics pour prédire des classes ou des valeurs numériques associées à des données sans libellé. Les données ne sont pas libellées si les classes ou les valeurs numériques qui vous intéressent n'existent pas dans les données. Par exemple, vous pourriez utiliser le Machine Learning pour prédire des défauts concernant les prêts ou prédire les prix futurs des maisons :
| Problème de prédiction | Type de prédiction | Description |
|---|---|---|
| Défauts concernant les prêts | Classification |
D'après les informations relatives aux demandeurs, comme l'âge, la catégorie d'emploi, la cote de crédit, etc., prédisez quels demandeurs seront en défaut s'ils obtiennent un prêt. En d'autres termes, les demandeurs feront-ils partie de la classe Défaut = Oui ou Défaut = Non ? |
| Prix futurs des maisons | Régression | En fonction de caractéristiques comme l'âge, la superficie, le code postal, le nombre de chambres à coucher et de salles de bains, etc., prédisez le prix de vente futur des maisons. |
Machine Learning automatisé
Dans Analytics, le Machine Learning est « automatisé » car deux commandes liées - Entraîner et Prédire - effectuent tout le travail de calcul associé à l'entraînement de l'apprentissage et de l'évaluation d'un modèle prédictif et à l'application du modèle prédictif à un jeu de données sans libellé. L'automatisation offerte par Analytics, par le biais de la fonction Machine Learning, permet de travailler sur des données de l'entreprise sans nécessiter de disposer de capacités scientifiques de gestion des données spécialisées.
Le flux d'activités d'entraînement et de prédiction
Le flux d'activités d'entraînement et de prédiction se compose de deux processus liés, et de deux jeux de données associés :
- Le Processus d'entraînement utilise un jeu de données d'entraînement (labellisé)
- Le Processus de prédiction utilise un nouveau jeu de données (non labellisé)
Processus d'entraînement de l'apprentissage
Le processus d'entraînement est d'abord exécuté, à l'aide d'un jeu de données labellisé qui comprend un champ labellisé (appelé également champ cible).
Le champ labellisé contient la classe connue, ou la valeur numérique connue, associée à chaque enregistrement du jeu de données d'entraînement. Par exemple, ou un emprunteur défini par défaut sur un prêt (O/N), ou le prix de vente d'une maison.
Grâce aux algorithmes de la fonction Machine Learning, le processus d’entraînement génère un modèle de prédiction. Le processus d'entraînement génère différents changements de modèles afin de trouver le modèle convenant le mieux aux tâches de prédiction que vous effectuez.
Processus de prédiction
Le processus de prédiction est ensuite exécuté. Il applique le modèle de prédiction généré par le processus d'entraînement à un nouveau jeu de données non labellisé, contenant des données identiques aux données du jeu de données d’entraînement.
Les valeurs labellisées comme par exemple les informations définies par défaut d'un prêt ou le prix de vente d'une maison n'existent pas dans le nouveau jeu de données, puisque ce sont des évènements futurs.
Grâce au modèle de prédiction, le processus de prédiction prévoit une classe ou une valeur numérique associée à chaque enregistrement non labellisé du nouveau jeu de données.
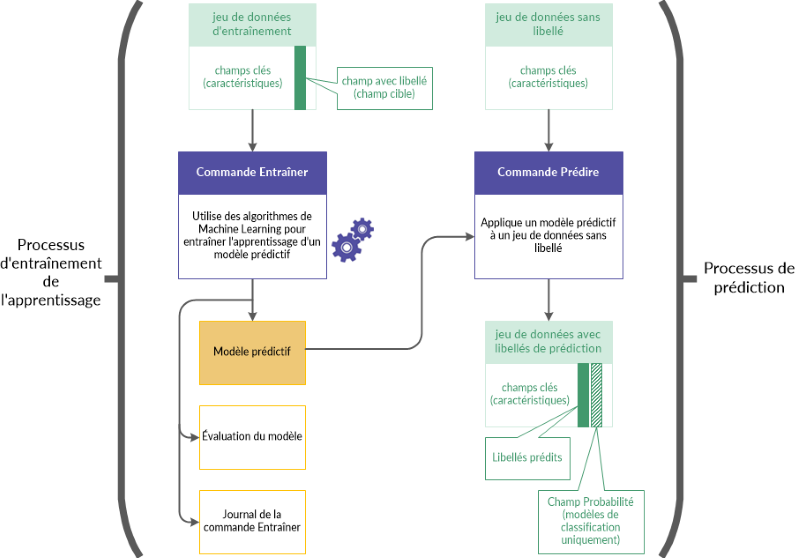
Le flux d'activités d'entraînement et de prédiction en détail
| Processus | Description | Exemples de jeu de données | |
|---|---|---|---|
| 1 |
Apprentissage (commande TRAIN) |
|
|
| 2 |
Prédiction (commande PREDICT) |
|
|
Durée de traitement
Le calcul requis par le Machine Learning prend du temps et utilise le processeur de manière intensive. L'entraînement de l'apprentissage d'un modèle prédictif à l'aide d'un vaste jeu de données comportant de nombreux champs peut prendre des heures ; il s'agit généralement d'une tâche que vous pouvez exécuter pendant la nuit.
L'inclusion des champs clés DateHeure dans le processus d'entraînement de l'apprentissage est particulièrement consommatrice de ressources processeur, car chacun de ces champs est utilisé pour dériver automatiquement 10 fonctionnalités synthétiques. Les fonctionnalités synthétiques DateHeure peuvent augmenter considérablement l'étendue des données prédictives, mais il est préférable d'inclure les champs DateHeure uniquement si vous pensez qu'ils peuvent être pertinents.
Astuce
Si vous venez de vous familiariser avec le Machine Learning dans Analytics, utilisez des jeux de données peu volumineux pour que les temps de traitement soient gérables et pour que vous puissiez voir les résultats assez rapidement.
Stratégies de réduction de la taille du jeu de données d'entraînement de l'apprentissage
Vous pouvez utiliser différentes stratégies pour réduire la taille du jeu de données d'entraînement de l'apprentissage et le temps de traitement associé, sans affecter de manière significative l'exactitude du modèle prédictif généré.
- Exclure du processus d'entraînement de l'apprentissage les champs qui ne contribuent pas à l'exactitude prédictive. Exclure les champs non pertinents et les champs redondants.
- Exclure du processus d'entraînement de l'apprentissage les champs qui ne contribuent pas à l'exactitude prédictive. Toutefois, soyez prudent si vous assumez que les champs DateHeure ne sont pas pertinents. Pour plus d'informations, consultez la section Champs clés DateHeure.
- Échantillonnez le jeu de données d'entraînement de l'apprentissage et utilisez les données échantillonnées comme données d'entrée pour le processus d'entraînement de l'apprentissage. Parmi les méthodes d'échantillonnage possibles, mentionnons les suivantes :
- équilibrer la taille des classes de données en échantillonnant les classes majoritaires de manière à obtenir une taille approximative de la taille moyenne des classes minoritaires
- échantillonnage aléatoire du jeu de données d'entraînement de l'apprentissage
- échantillonnage stratifié basé sur les caractéristiques
- échantillonnage stratifié basé sur la mise en clusters
Champs clés DateHeure
Vous pouvez créer un ou plusieurs champs DateHeure comme champs clés lors de l'entraînement d'un modèle prédictif. En règle générale, trop de valeurs uniques sont présentes dans un champ DateHeure pour qu'il soit une source adéquate de catégories ou de fonctionnalités identifiables pour le processus d'entraînement. De même, les données DateHeure brutes peuvent sembler sans rapport avec le champ cible qui vous intéresse.
Cependant, une fois classées en catégories, les données DateHeure peuvent être pertinentes. Par exemple, les évènements que vous examinez peuvent survenir habituellement certains jours de la semaine ou à certaines heures de la journée.
Le processus d'entraînement dérive automatiquement un certain nombre de fonctionnalités synthétiques de chaque champ DateHeure en classant les données DateHeure brutes dans des catégories. Ces fonctionnalités synthétiques sont alors incluses dans l'algorithme qui génère un modèle prédictif.
Fonctionnalités synthétiques dérivées de champs DateHeure
Les fonctionnalités synthétiques automatiquement dérivées des champs Date, Heure ou DateHeure sont répertoriées ci-dessous.
| Description de fonctionnalité synthétique | Type de fonctionnalité | Nom de fonctionnalité synthétique |
|---|---|---|
| Jour de la semaine | Numérique (1 à 7) | fieldname_DOW |
| Mois | Numérique (1 à 12) | fieldname_MONTH |
| Trimestre | Numérique (1 à 4) | fieldname_QTR |
| Nombre de jours depuis le début du mois | Numérique (1 à 31) | fieldname_DAY |
| Nombre de jours depuis le début de l'année | Numérique (1 à 366) | fieldname_DOY |
| Secondes | Numérique (00 à 59) | fieldname_SECOND |
| Heure de la journée | Numérique (1 à 24) | fieldname_HOUR |
| Nombre de secondes depuis le début de la journée | Numérique (1 à 86400) | fieldname_SOD |
| Quartile de la journée |
Catégorique :
|
fieldname_QOD |
| Octile de la journée |
Catégorique :
|
fieldname_OOD |
Entraînement de l'apprentissage d'un modèle prédictif
Remarque
La taille maximale prise en charge pour le jeu de données utilisé avec le processus d'entraînement de l'apprentissage est de 1 Go.
Si les options du menu Machine Learning sont désactivées, c'est probablement parce que le moteur Python n'est pas installé. Pour plus d'informations, consultez la section Installer ACL pour Windows.
Étapes
Spécifier les paramètres de base relatifs au processus d'entraînement de l'apprentissage
- Ouvrez la table Analytics avec le jeu de données d'entraînement de l'apprentissage.
- Dans le menu principal Analytics, sélectionnez Machine Learning > Entraîner.
- Précisez le temps alloué au processus d'entraînement de l'apprentissage :
Temps de recherche d'un modèle optimal Temps total en minutes à consacrer à la génération et au test de modèles prédictifs ainsi qu'à la sélection d'un modèle gagnant.
Indiquez un temps de recherche égal au moins à 10 fois votre temps d'évaluation maximal par modèle.
Temps maximal par évaluation de modèle Temps d'exécution maximal en minutes par évaluation de modèle.
Allouez 45 minutes pour 100 Mo de données d'entraînement de l'apprentissage.
Remarque
La durée d'exécution totale du processus d'entraînement de l'apprentissage correspond au temps de recherche plus jusqu'à deux fois la durée maximale d'évaluation du modèle.
Ces durées suggérées établissent un équilibre raisonnable entre le temps de traitement et la possibilité d'évaluer une variété de types de modèles.
- Spécifiez le type de prédiction à utiliser :
- Classification utiliser des algorithmes de classification pour entraîner un modèle
Utilisez la classification si vous souhaitez prédire à quelle classe ou catégorie appartiennent les enregistrements d'un jeu de données sans libellé.
- Régression utiliser des algorithmes de régression pour entraîner un modèle
Utilisez la régression si vous souhaitez prédire les valeurs numériques associées aux enregistrements d'un jeu de données sans libellé.
Pour obtenir des informations sur les algorithmes spécifiques utilisés avec la classification et la régression, consultez la rubrique Algorithmes d'entraînement.
- Classification utiliser des algorithmes de classification pour entraîner un modèle
- Dans la liste déroulante Indicateur de performance du modèle, sélectionnez la mesure à utiliser pour noter les modèles générés pendant le processus d'entraînement de l'apprentissage.
Le modèle généré ayant la meilleure valeur pour cette mesure est conservé, et les autres modèles sont abandonnés.
Un sous-ensemble différent de mesures est disponible selon le type de prédiction que vous utilisez :
Classification Log loss | AUC | Exactitude | F1 | Précision | Rappel Régression Erreur quadratique moyenne | Erreur absolue moyenne | R2 Remarque
La mesure de classification AUC est seulement valide lorsqu'elle est utilisée avec un champ cible qui contient des données binaires, c'est-à-dire deux classes telles que Oui/Non ou Vrai/Faux.
Sélectionner les champs
- Dans la liste Entraîner sur, sélectionnez un ou plusieurs champs clés à utiliser comme entrée pour l'entraînement du modèle.
Les champs clés sont les caractéristiques qui servent de base à la prédiction des valeurs des champs cibles dans un jeu de données sans libellé. Les champs clés peuvent être de type caractère, numérique ou logique. Les fonctionnalités synthétiques sont automatiquement dérivées des champs clés DateHeure.
Remarque
Les champs de type caractère doivent être « catégoriques ». Cela signifie qu'ils doivent identifier des catégories ou des classes et ils ne peuvent pas dépasser un nombre maximal de valeurs uniques.
Ce maximum est spécifié par l'option Valeurs max des catégories (Outils > Options > Commande).
Astuce
Vous pouvez utiliser la combinaison Ctrl+clic pour sélectionner plusieurs champs non adjacents, et Maj+clic pour sélectionner plusieurs champs adjacents.
- Dans la liste Champ cible, sélectionnez le champ cible.
Le champ cible correspond au champ que le modèle est en train d'apprendre à prédire en se basant sur les champs clés d'entrée.
La classification et la régression fonctionnent avec différents types de données de champs cibles :
- classification champ cible de type caractère ou logique
- régression champ cible numérique
Nommer le fichier de modèle et la table ACL de sortie
- Dans la zone de texte Nom du modèle, spécifiez le nom du fichier de modèle généré par le processus d'entraînement de l'apprentissage.
Le fichier de modèle contient le modèle le mieux adapté au jeu de données d'entraînement de l'apprentissage. Vous saisirez le fichier de modèle dans le processus de prédiction pour générer des prédictions sur un nouveau jeu de données inédit.
- Dans la zone de texte À, indiquez le nom de la table d'évaluation du modèle sortie par le processus d'entraînement de l'apprentissage.
La table d'évaluation du modèle contient deux types d'informations différentes :
- Indicateur de performance/Mesure pour les mesures de classification ou de régression, estimations quantitatives des performances prédictives du fichier de modèle sorti par le processus d'entraînement
- Importance/Coefficient dans l'ordre décroissant : valeurs indiquant dans quelle mesure chaque caractéristique (prédicteur) contribue aux prédictions effectuées par le modèle
-
Si vous souhaitez exclure du traitement certains enregistrements de la vue en cours, saisissez une condition dans la zone de texte Si, ou cliquez sur Si pour créer une instruction IF à l'aide du Générateur d'expression.
Remarque
La condition Si est évaluée uniquement par rapport aux enregistrements restant dans une table après application des options relevant du champ d'application (Premiers, Suivants, Tant que).
L'instruction IF prend en compte tous les enregistrements de la vue et exclue ceux qui ne correspondent pas à la condition spécifiée.
Spécifier que seul un sous-ensemble du jeu de données d'entraînement de l'apprentissage est utilisé (facultatif)
Dans l'onglet Plus, sélectionnez l'une des options du panneau Étendue :
| Tous (par défaut) | Tous les enregistrements de la table sont traités. |
| Premiers | Sélectionnez cette option et saisissez un nombre dans la zone de texte pour démarrer le traitement au premier enregistrement de la table et inclure uniquement le nombre d'enregistrements indiqué. |
| Suivants |
Sélectionnez cette option et saisissez un nombre dans la zone de texte pour démarrer le traitement à l'enregistrement actuellement sélectionné de la vue de la table et inclure uniquement le nombre d'enregistrements indiqué. Vous devez sélectionner le nombre d'enregistrements réel dans la colonne la plus à gauche et non pas les données dans la ligne. |
| Instruction WHILE |
Sélectionnez cette option pour utiliser une instruction WHILE et ainsi limiter le traitement des enregistrements de la table selon des critères. |
Spécifier les paramètres avancés pour le processus d'entraînement de l'apprentissage
- Dans l'onglet Plus, indiquez le Nombre de replis de la validation croisée.
Laissez le nombre par défaut de 5 ou indiquez un nombre différent. Les nombres valides sont compris entre 2 et 10.
Les replis correspondent aux sous-divisions du jeu de données d'entraînement de l'apprentissage ; ils sont utilisés dans un processus de validation croisée pendant l'évaluation et l'optimisation d'un modèle.
Généralement, l'utilisation de 5 à 10 replis donne de bons résultats lors de l'entraînement d'apprentissage d'un modèle.
Astuce
L'augmentation du nombre de replis peut produire une meilleure estimation des performances prédictives d'un modèle, mais elle augmente également la durée d'exécution globale.
- Facultatif. Sélectionnez Valeur de départ, puis saisissez un nombre.
Valeur de départ utilisée pour lancer le générateur de nombres aléatoires dans Analytics.
Si vous ne sélectionnez pas Valeur de départ, Analytics sélectionne aléatoirement la valeur de départ.
Spécifiez explicitement une valeur de départ et enregistrez-la si vous souhaitez reproduire le processus d'entraînement de l'apprentissage avec le même jeu de données à l'avenir.
- Facultatif. Si vous souhaitez entraîner et noter uniquement des modèles linéaires, sélectionnez Seulement évaluer les modèles linéaires.
Si vous ne sélectionnez pas cette option, tous les types de modèles pertinents pour la classification ou la régression sont évalués.
Remarque
Avec des jeux de données plus volumineux, le processus d'entraînement de l'apprentissage s'achève plus rapidement si vous incluez uniquement des modèles linéaires.
Le fait de n'inclure que des modèles linéaires garantit des constantes dans la sortie.
- Facultatif. Sélectionnez Désactiver la sélection de fonctionnalité et le prétraitement si vous souhaitez exclure ces sous-processus du processus d'entraînement de l'apprentissage.
La sélection des caractéristiques est la sélection automatisée des champs du jeu de données de l'entraînement qui sont les plus utiles pour optimiser le modèle prédictif. La sélection automatisée peut améliorer les performances prédictives et réduire la quantité de données nécessaires à l'optimisation des modèles.
Le prétraitement des données effectue des transformations telles que la mise à l'échelle et la normalisation du jeu de données d'entraînement afin de le rendre mieux adapté aux algorithmes d'apprentissage.
Attention
Vous ne devez désactiver la sélection de caractéristiques et le prétraitement des données que si vous avez une raison de le faire
- Cliquez sur OK.
Le processus d'entraînement de l'apprentissage est lancé et une boîte de dialogue apparaît en affichant les paramètres de saisie que vous avez spécifiés et la durée de traitement écoulée.
Application d'un modèle prédictif à un jeu de données sans libellé
Remarque
Si les options du menu Machine Learning sont désactivées, c'est probablement parce que le moteur Python n'est pas installé. Pour plus d'informations, consultez la section Installer ACL pour Windows.
Étapes
- Ouvrez la table Analytics avec le jeu de données sans libellé.
- Dans le menu principal Analytics, sélectionnez Machine Learning > Prédire.
- Cliquez sur Modèle, dans la boîte de dialogue Sélectionner le fichier, sélectionnez un fichier de modèle produit par un processus d'entraînement de l'apprentissage précédent, puis cliquez sur Ouvrir.
Les fichiers de modèle ont une extension de fichier *.model.
Remarque
Le fichier de modèle doit avoir été entraîné sur un jeu de données contenant les mêmes champs que le jeu de données sans libellé (ou contenant en grande partie les mêmes champs).
Vous ne pouvez pas utiliser un fichier de modèle entraîné dans la version 14.1 d'Analytics. Les fichiers de modèles de la version 14.1 ne sont pas compatibles avec les versions suivantes d'Analytics. Entraînez un nouveau modèle prédictif à utiliser avec le processus de prédiction.
- Dans la zone de texte Vers, indiquez le nom de la table Analytics sortie par le processus de prédiction.
La table de sortie contient les champs clés que vous avez spécifiés pendant le processus d'entraînement de l'apprentissage ainsi qu'un ou deux champs générés par le processus de prédiction :
- Prédit classes ou valeurs numériques prédites associées à chaque enregistrement dans le jeu de données sans libellé
- Probabilité (classification uniquement) probabilité qu'une classe ou valeur numérique prédite est exacte
-
Si vous souhaitez exclure du traitement certains enregistrements de la vue en cours, saisissez une condition dans la zone de texte Si, ou cliquez sur Si pour créer une instruction IF à l'aide du Générateur d'expression.
Remarque
La condition Si est évaluée uniquement par rapport aux enregistrements restant dans une table après application des options relevant du champ d'application (Premiers, Suivants, Tant que).
L'instruction IF prend en compte tous les enregistrements de la vue et exclue ceux qui ne correspondent pas à la condition spécifiée.
- Facultatif. Pour traiter uniquement un sous-ensemble du jeu de données sans libellé, dans l'onglet Plus, sélectionnez l'une des options du panneau Étendue .
- Cliquez sur OK.
Algorithmes d'entraînement
Trois options de commande d'entraînement dictent quels algorithmes de Machine Learning sont utilisés pour l'entraînement de l'apprentissage d'un modèle prédictif :
| Option | Onglet de la boîte de dialogue Entraîner |
|---|---|
| Classification ou Régression | Onglet Principal |
| Seulement évaluer les modèles linéaires | Onglet Plus |
| Désactiver la sélection de fonctionnalité et le prétraitement | Onglet Plus |
Les sections qui suivent résument comment les options contrôlent les algorithmes utilisés.
Les noms des algorithmes n'apparaissent pas dans l'interface utilisateur d'Analytics. Le nom de l'algorithme utilisé pour générer le modèle finalement sélectionné par la commande Entrainer s'affiche dans le fichier journal.
Algorithmes de classification
![]() Algorithme utilisé
Algorithme utilisé ![]() Algorithme non utilisé
Algorithme non utilisé
| Nom de l'algorithme | Toujours inclus | Seulement évaluer les modèles linéaires | Désactiver la sélection de fonctionnalité et le prétraitement | ||
|---|---|---|---|---|---|
| Option non sélectionnée (par défaut) | Option sélectionnée | Option non sélectionnée (par défaut) | Option sélectionnée | ||
| Type d'algorithme : classificateur | |||||
| Logistic Regression (régression logistique) |
|
||||
| Linear Support Vector Machine (machine à vecteurs de support linéaire) |
|
||||
| Random Forest (forêt aléatoire) |
|
|
|||
| Extremely Randomized Trees (arbres extrêmement aléatoires) |
|
|
|||
| Gradient Boosting Machine |
|
|
|||
| Type d'algorithme : préprocesseur de fonctionnalités | |||||
| One Hot Encoding (encodage à chaud de caractéristiques catégoriques) |
|
||||
| Fast Independant Component Analysis (Fast-ICA analyse en composantes indépendantes) |
|
|
|||
| Feature Agglomeration (agglomération des fonctions) |
|
|
|||
| Principal Component Analysis – Singular Value Decomposition (analyse en composantes principales – décomposition en valeurs singulières, SVD) |
|
|
|||
| Second Degree Polynomial Features (fonctions polynômes du second degré) |
|
|
|||
| Binarizer (binariseur) |
|
|
|||
| Robust Scaler |
|
|
|||
| Standard Scaler |
|
|
|||
| Maximum Absolute Scaler (scaler de maximum absolu) |
|
|
|||
| Min Max Scaler (scaler min max) |
|
|
|||
| Normalizer (normalisateur) |
|
|
|||
| Nystroem Kernel Approximation (approximation de noyaux Nystroem) |
|
|
|||
| RBF Kernel Approximation (approximation de noyaux RBF) |
|
|
|||
| Zero Counter (compteur zéro) |
|
|
|||
| Type d'algorithme : sélecteur de fonctionnalités | |||||
| Family-wise Error Rate (FWER) |
|
|
|||
| Percentile des scores les plus élevés |
|
|
|||
| Variance Threshold (seuil de variance) |
|
|
|||
| Recursive Feature Elimination (élimination de la fonction récursive) |
|
|
|||
| Importance Weights (pondérations d'importance) |
|
|
|||
Algorithmes de régression
![]() Algorithme utilisé
Algorithme utilisé ![]() Algorithme non utilisé
Algorithme non utilisé
| Nom de l'algorithme | Toujours inclus | Seulement évaluer les modèles linéaires | Désactiver la sélection de fonctionnalité et le prétraitement | ||
|---|---|---|---|---|---|
| Option non sélectionnée (par défaut) | Option sélectionnée | Option non sélectionnée (par défaut) | Option sélectionnée | ||
| Type d'algorithme : régresseur | |||||
| Elastic Net (régularisation mixte L1-L2) |
|
||||
| Lasso |
|
||||
| Ridge |
|
||||
| Linear Support Vector Machine (machine à vecteurs de support linéaire) |
|
||||
| Random Forest (forêt aléatoire) |
|
|
|||
| Extremely Randomized Trees (arbres extrêmement aléatoires) |
|
|
|||
| Gradient Boosting Machine |
|
|
|||
| Type d'algorithme : préprocesseur de fonctionnalités | |||||
| One Hot Encoding (encodage à chaud de caractéristiques catégoriques) |
|
||||
| Fast Independant Component Analysis (Fast-ICA analyse en composantes indépendantes) |
|
|
|||
| Feature Agglomeration (agglomération des fonctions) |
|
|
|||
| Principal Component Analysis – Singular Value Decomposition (analyse en composantes principales – décomposition en valeurs singulières, SVD) |
|
|
|||
| Second Degree Polynomial Features (fonctions polynômes du second degré) |
|
|
|||
| Binarizer (binariseur) |
|
|
|||
| Robust Scaler |
|
|
|||
| Standard Scaler |
|
|
|||
| Maximum Absolute Scaler (scaler de maximum absolu) |
|
|
|||
| Min Max Scaler (scaler min max) |
|
|
|||
| Normalizer (normalisateur) |
|
|
|||
| Nystroem Kernel Approximation (approximation de noyaux Nystroem) |
|
|
|||
| RBF Kernel Approximation (approximation de noyaux RBF) |
|
|
|||
| Zero Counter (compteur zéro) |
|
|
|||
| Type d'algorithme : sélecteur de fonctionnalités | |||||
| Family-wise Error Rate (FWER) |
|
|
|||
| Percentile des scores les plus élevés |
|
|
|||
| Variance Threshold (seuil de variance) |
|
|
|||
| Importance Weights (pondérations d'importance) |
|
|
|||