概念信息
聚类操作可基于一个或多个数值键域中的类似值对表中的记录进行分组。类似值是整个数据集的上下文中相互接近的值。这些类似值代表聚类,一旦将其识别出来,可以揭示数据中的模式。
说明
如果您想要使聚类成为您的分析项目的常规部分,建议您学习 Galvanize 学校课程在 Analytics 中使用 CLUSTER 命令发现数据组 (ACL 361)(要求客户登录)。
聚类与其他 Analytics 分组命令有何不同
聚类与其他 Analytics 分组命令有下列不同之处:
- 聚类不要求对预先存在的数据类别(如交易类型或贸易商类别代码)或者具有硬性数值边界的预定义层进行分组。相反,聚类基于数据本身内的类似数值类型值即彼此接近的值对数据进行分组。
- 基于一个以上的域进行聚类会输出未嵌套(不分层)的结果。
选择要作为聚类依据的域
数据聚类使您可以发现数据中的、采用其他方法可能不知道存在的有机分组。特别需要指出的是,如果不借助于机器学习,则难以识别基于多个数值域的聚类(多维聚类)。在这个意义上,聚类是探索性的,并且是一个无人监督机器学习的范例。
但是,要使输出聚类有意义,您选择进行聚类的域之间必须存在有意义的关系。
将单个域作为聚类依据
将单个数值域作为聚类依据相当简单。您专注于单个值集,并且聚类操作基于值之间的接近度或近似度对这些值进行分组。例如,您可以对金额域进行聚类,以便弄清楚这些金额在整个值范围中的何处集中。
与分层等传统方法相比,聚类的优点是您无须事先就哪里可能存在集中进行任何假设,也无须创建主观性的数值边界。对于任何给定的聚类个数,聚类操作都可以发现边界位于何处。
依据单个数值域进行聚类的示例
您依据 Invoice Amount 域对 Ap_Trans 表进行聚类,以发现金额集中于值范围的何处。您的预期是大多数金额聚集于该范围的低端。聚类操作可以确认您预期的模式是否符合事实。
您决定将 Invoice Amount 域分组为五个聚类,然后对这些聚类进行汇总,以发现每个聚类中有多少个记录。
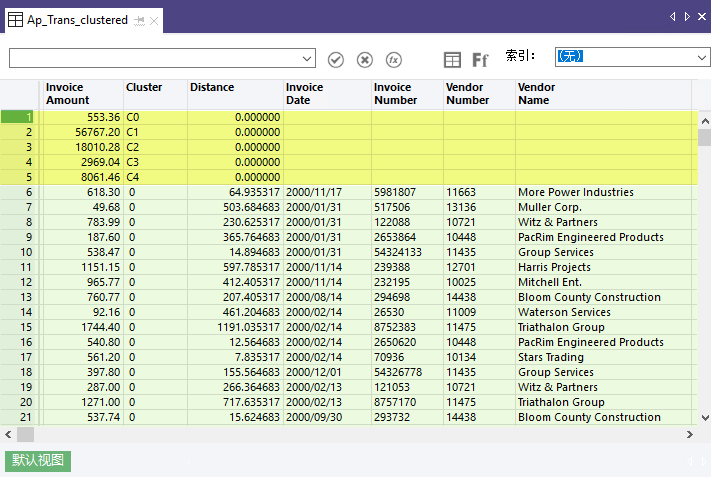
输出结果
在如下所示的输出结果中,前五个记录是系统生成的,并且与您指定的所需聚类数相当。在 Invoice Amount 域中,前五个记录显示聚类算法为五个发票金额聚类中的每一个计算的质心或中心。例如,聚类 3 ( C3 ) 的质心为 2969.04。有关详细信息,请参见聚类算法如何工作。
在系统生成的域之下是被分组到聚类中的源数据域(从聚类 0 开始)。Distance 域中的值从实际发票金额到该聚类的计算质心值的距离。因此,以记录 6 为例,发票金额 618.30 减去距离 64.935317 等于质心值 553.36。
说明
您根据实际值是大于还是小于该质心值来减去或者增加距离值。
汇总聚类
如果您汇总 Cluster 域,然后按计数汇总输出,则会得到下列结果,从而确认值的分布情况符合您的预期。总体上,发票金额向低值严重倾斜。(质心值被添加到表中以方便比较。)
单独位于聚类中的单个大值似乎为异常值,很可能应该予以调查。
| 聚类 | 计数 | 质心值 |
|---|---|---|
| 0 | 73 | 553.36 |
| 3 | 16 | 2,969.04 |
| 4 | 8 | 8,061.46 |
| 2 | 4 | 18,010.28 |
| 1 | 1 | 56,767.20 |
将多个域作为聚类依据
当您将两个或更多个域作为聚类依据时,您需要问您自己这些域之间存在什么样的关系。您可以使用聚类来测试假设。例如,一家公司可能关注员工变动率,而管理层认为员工变动主要发生在比较年轻的低薪员工中间。
您可以使用聚类来发现下列因素之间是否存在密切的关系:
- 员工留任时间长度和员工年龄(二维聚类)
- 员工留任时间长度、员工年龄和薪资(三维聚类)
说明
对于此分析,您需要避免包括任何与该假设不存在明显关联的域,如请病假的天数。
评估输出聚类
聚类算法总是输出一个包含指定数量的聚类的表。输出表中的每个记录都将在某个聚类中。
此时,您需要评估这些聚类是否具有分析重要性或意义。算法对某个聚类中的记录进行分组并不必然意味着该分组具有重要性。您需要问一下自己这些聚类是否构成显著模式。它们是否揭示了某种事实?
提示
通过在报告工具中将聚类输出表绘制为散点图,并且为每个聚类分配一种不同的颜色,可以最轻松地快速评估输出聚类的总体性质。
下列特征可帮助您评估输出聚类的意义:
- 聚类紧凑性聚类中的单个值全都相当接近于质心还是有点分散?聚类越紧凑,构成该聚类的值之间的关系越密切。
- 聚类大小是否大多数值都被包含在一两个大型聚类中?如果是,则与其值相对均匀分布在多个聚类中的数据集相比,该数据集严重扭曲。
- 异常值考虑无法被包含在任一重大聚类中的值。这些异常值可能代表值得进一步审查的条目。还要考虑“内部异常值”,即被包括在重大聚类中但位于该聚类边界的值。
说明
上述特征都是聚类评估的主观方法。存在各种聚类评估数学方法,但它们超出了 Analytics 帮助的范围。
聚类算法如何工作
Analytics 中的聚类使用 K 均值聚类算法,这是一种流行的机器学习算法。您可以在互联网上找到详细的 K 均值聚类介绍。
下面给出了该算法的摘要。
K 均值聚类算法使用一个迭代流程来优化聚类:
| 1 | 指定聚类个数 |
|
|---|---|---|
| 2 | 初始化聚类形心 |
|
| 3 | 将每个数据点分配给最近的形心 |
|
| 4 | 重新计算形心 |
|
| 5 | 迭代 |
|
选择聚类个数 (K 值)
要确定在对数据进行聚类时使用的最佳聚类个数,可能需要进行一些测试和试验。对于任何给定的数据集,没有一个准确的答案。
确定最佳聚类个数的准则:
- 熟悉数据 预先熟悉数据集,以大致了解数据的分布情况和值的集中程度。
- 首先选择一个较高值 首先选择一个相对较高的聚类个数 – 8 到 10。
- 尝试不同的聚类个数 多次执行聚类,每次都指定一个不同的 K 值。对输出结果进行审核可以帮助您判断是需要更多还是更少的聚类。
- 肘部法则使用肘部法则,以编程方式识别最佳聚类个数。最佳数字是这样一个点,在此处,您可以获得最佳聚类紧凑性,同时又避免了以增加额外的聚类并拆分已经紧凑的聚类为代价,却只能略微提高紧凑性,从而使得回报过少的情况。
您可以在线状图中绘制肘部法则的结果,以直观地识别“肘部”即拐点,在这里,增加聚类个数不会显著提高其紧凑性。
您可以从 ScriptHub 下载可在 Analytics 中使用的肘部法则脚本:肘部法则 - K 误差平方和 (SSE)(要求客户登录)。
我可以将字符域或日期时间域作为聚类依据吗?
一般情况下,您不能将字符域或日期时间域作为聚类依据。聚类算法只接受数字,并且它使用数字(欧氏距离、均值)执行计算。
类别字符数据
您可能拥有数字形式的类别字符数据,如位置 ID。或者,您可以使用计算域将字符类别映射到您创建的一组数值代码。您可以将此数据转换为数值数据类型并使用它进行聚类。但是,生成的聚类将是无效的,因为您是基于代表某种非数值性内容的数字执行数学计算。
例如,基于一个位置 ID 列表的平均值计算形心位置会得到一个无意义的数字。该计算基于一个无效的假设,即位置编号之间的数学距离相当于某种现实的可量度的距离。
如果我们考虑物理距离,那么说位置 1 和位置 9 之间的距离是位置 1 和位置 5 之间距离的两倍是没有道理的。位置 1 和 9 可能相互毗邻,而位置 5 则可能在几英里以外。
对于涉及位置和物理距离的聚类分析,要使用的有效数据是地理坐标。
代表尺度的类别数据
您可能以代表尺度的类别数据作为聚类依据,例如,从低劣到优秀的评级尺度(相应的数值代码为从 1 到 5)。在此情况下,数值代码的平均值是有意义的。
日期时间数据
您可以使用 Analytics 函数将日期时间数据转换为数值数据。但是,生成的数值数据不是连续的,从而给聚类分析带来问题,后者假定数字集是连续的。
例如,下面的三个表示日期的数字均相差一天。但是,作为数字,第一个数字和第二个数字之间存在相当大的间隙或者距离。
- 20181130
- 20181201
- 20181202
您可以在聚类分析中使用序列化日期值。序列化日期是一组连续的整数,表示自 1900 年 1 月 1 日以来已经逝去的天数。
步骤
说明
如果机器学习菜单选项被禁用,则 Python 引擎很可能未安装。有关详细信息,请参见安装 ACL for Windows。
为聚类算法指定设置
- 打开包含您想要聚类的数据的表。
- 从 Analytics 主菜单中选择机器学习 > 聚类。
- 在聚类个数 (K 值)中,指定要用来对数据进行分组的聚类个数。
- 在最大迭代数中,为该聚类算法所执行的迭代数指定一个上限。
- 在初始化数量中,指定生成随机形心的初始集的次数。
- 可选。选择种子,然后输入一个数字。
指定数据预处理方法
如果您按一个以上的键域进行聚类,则在使用它们进行聚类之前,应该使用预处理功能标准化这些域的规模。
不同数值域的规模和单位经常各不相同。例如,包含每年美元数的薪水域可能介于 20000 和 100000 之间,而包含年数的年龄域可能介于 18 和 70 之间。如果您使用薪水域和年龄域在没有按比例缩放的情况下进行聚类,则输出聚类将在本质上是薪水聚类(由于薪水数字相对于年龄数字而言过于庞大而被扭曲),而不是薪水/年龄聚类。
预处理提供下面介绍的方法,以将所有聚类键域中的所有值按比例缩放,以使它们在聚类处理过程中具有同等权重。
| 预处理选项 | 描述 |
|---|---|
| 标准化 |
键域值被以均值零 (0) 为中心集中化并且被按比例缩放,即将这些值转换为其 z 分数等效值(标准分数)。 z 分数是对将每个域的原始值与原始均值分开的标准偏差数的衡量。在按比例缩放的域中,均值由零 (0) 表示,z 分数或正或负,具体取决于它们代表的原始值是大于还是小于该域的原始均值。 说明 如果键域主要包含非零值(“密集矩阵”),请使用此选项。 z 分数计算示例在按比例缩放的年龄域中,原始年龄值 55 由 z 分数 1.038189 表示。
|
| 缩放到单位方差 |
键域值被通过除以其标准偏差来按比例缩放,但它们未被以均值零 (0) 为中心集中化。 说明 如果一个或多个键域包含大量零 (0) 值(“稀疏矩阵”),请使用此选项。 按比例缩放而不集中化的示例在按比例缩放的年龄域中,原始年龄值 55 由按比例缩放的值 4.406077 表示。
|
| 无 | 键域值未被集中化或者按比例缩放。聚类操作在计算聚类时使用未集中化且未按比例缩放的原始值。 |
选择域
- 从聚类依据列表中,选择一个或多个要用来对该表中的记录进行聚类的键域。
键域必须是数值域。
- 可选。从其他域列表中,选择一个或多个要包括在输出表中的其他域。
提示
您可以使用 Ctrl+单击选择多个不相邻的域,使用 Shift+单击选择多个相邻的域。
最终确定命令输入
-
如果当前视图中有想要从处理中排除的记录,请在如果文本框中输入一个条件,或单击如果使用表达式生成器创建 IF 声明。
说明
在应用任何范围选项(前、后、当)之后,仅针对表中的剩余记录评估如果条件。
IF 声明中考虑到了视图中的所有记录,滤除那些不满足指定条件的记录。
- 在到文本框中,指定输出表的名称。
- 可选。在更多选项卡上:
- 要指定只处理记录的一个子集,请选择范围面板中的选项之一。
- 如果您希望输出表自动打开,请选择使用输出表。
- 单击确定。