传统变量抽样
传统变量抽样是一种统计抽样方法,用于估计:
- 一个账户或一类交易的合计审计价值
- 一个账户或一类交易中的货币错报总金额
传统变量抽样最适合于具有以下特征的财务数据:
|
具有适量到大量的错报 例如,5% 或更多的项被错报。 |
| 高估或低估都可能存在 |
| 可能存在零元项 |
提示
有关 Analytics 中的完整传统变量抽样流程的实践性介绍,请参见传统变量抽样教程。
说明
除了财务数据以外,您还可以将传统变量抽样用于任何具有可变特征的数值数据 — 例如,数量、时间单位或其他度量单位。
工作原理
传统变量抽样使您可以选择并分析一个账户中记录的小型子集。基于该子集的分析结果,您可以估计该账户的总审计价值以及货币错报总金额。
这两个估计值被计算为范围:
- 点估计値是该范围的中点。
- 上限和下限是范围的两个端点。
您还可以选择计算单限值的估计或范围,即具有点推定値并只有一个上限或下限。
您可以将估计范围与该账户的账面价值或者与您认为重要的错报金额进行比较,并且做出与该账户有关的决定。
传统变量抽样支持进行以下种类的报告:
- 该账户的真实审计价值介于 45,577,123.95 和 46,929,384.17(该范围包含账户账面价值 46,400,198.71)之间的概率为 95%。因此,该账户中的金额被适当报告。
- 帐户余额中的错报介于 –813,074.76 和 539,185.46(未超过货币精度 ±928,003.97)之间的概率为 95%。因此,该账户中的金额被适当报告。
传统变量抽样流程概述
注意
不要跳过计算有效样本量的过程。
如果您直接抽取记录样本,并猜测样本量,则很有可能您的分析结果的推断将是无效的,并且您的最终结论存在缺陷。
传统变量抽样流程涉及下列阶段:
- 准备(计划)传统变量样本
- 提取记录样本
- 对抽样数据执行预期审计程序。
- 评估下列方面之一:
- 在将抽样数据的审计价值推断至整个账户后,是否落入所记录的账面价值的可接受范围
- 抽样数据中的观察货币错报水平是否代表了整个账户中的可接受或不可接受错报金额
在各个阶段之间,值被保留下来并被预先填充
Analytics 中的传统变量抽样要求您在三个不同的对话框中输入信息,并且按以下顺序运行关联的命令:
- CVS 准备对话框
- CVS 抽样对话框
- CVS 评估对话框
当您执行此流程时,前一个对话框的信息会被自动预先填充到下一个对话框中。预先填充可节省精力,并且消除了意外输入不正确的值并使样本无效的风险。
但是,自动预填充 CVS 抽样和 CVS 估计对话框的值仅被临时存储,当您关闭 Analytics 项目后会被删除。
重新生成传统变量抽样值
在生产环境中,您通常在不同时间执行传统变量抽样流程的不同阶段。您可以使用下列任一方法重新生成在您关闭 Analytics 时丢失的传统变量抽样值。
第一个方法是最轻松。
- 保存预先填充的命令
CVS 准备和 CVS 抽样阶段的结果包括传统变量抽样流程中使用所需值预先填充的后续命令。将这些预先填充的命令保存在单独的脚本中以供以后使用。
有关详细信息,请参见传统变量抽样教程。
- 在脚本中保存所执行的命令
在执行 CVS 准备和 CVS 抽样阶段之后,从 Analytics 显示区域复制 CVSPREPARE 和 CVSSAMPLE 命令并将其保存在单独的脚本中。您以后可以运行这些脚本以重新生成传统变量抽样值。
此方法的缺点是您抽取了一个冗余的记录样本。
- 从日志中检索已执行的命令
从日志中复制 CVSPREPARE 和 CVSSAMPLE 命令,并且在命令行中重新运行它们以重新生成传统变量抽样值。
此方法的缺点是在日志中找到这些命令的正确实例可能很困难,并且您抽取了一个冗余的记录样本。
更改预填充值
通常,您不应该更改任何预填充的传统变量抽样值。更改预先填充值可能否定抽样流程的统计有效性。
注意
仅当您具有统计知识并且了解所做更改的影响时,才应该更新预填充值。
数值长度限制
在传统变量抽样的准备阶段,会发生多个内部计算。这些计算支持最大长度为 17 位的数字。如果任何计算的结果超过 17 位,则该结果不会被包括在输出中,并且您无法继续执行抽样流程。
请注意,少于 17 位的源数据数字可能生成超过 17 位的内部计算结果。
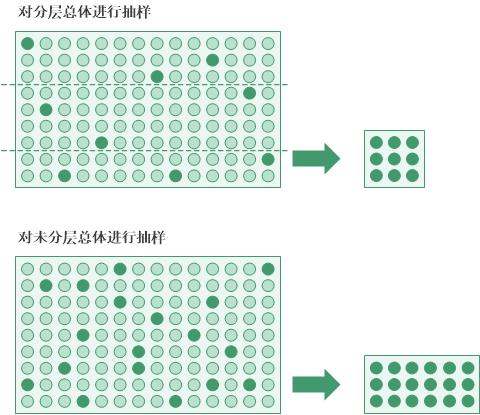
分层
传统变量抽样使您可以在抽取样本之前,选择对总体中的记录进行数值分层。
分层的优点是它通常可以在保持统计有效性的前提下显著减小所需的样本量。减小样本量意味着为达到您的目标所需完成的数据分析工作更少。
工作原理
分层通过将总体划分为多个名为层的子组或等级来完成。理想情况下,每个层中的值都相对同质。
统计算法(内曼方法)设置层之间的边界。该算法适当放置边界,以最大程度地减少每个层内值的差异性,从而降低总体差异的影响。减少差异或“分布范围”可减小所需的样本量。各个层的范围并非一致。
因此,所需的样本量是基于每个层而非整个未分层的总体计算和合计的。对于相同的数据集,分层方法通常会比未分层方法产生小得多的样本量。
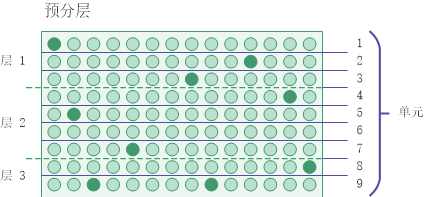
使用单元进行预分层
在分层流程中,您可以指定用来对总体进行预分层的单元数。单元是比层更窄的一致数值分区。
统计算法在分配最佳层边界的计算中使用每个单元中的记录数。单元不会被保留在最终的分层输出中。
指定单元的数量必须至少是指定层数的两倍。
说明
预分层单元和在样本选择的单元方法中使用的单元不是一回事。
好事过头反成坏事
分层是一种管理样本量的强大工具,但是您在指定层数和单元数时应该小心。
开始时,请尝试:
- 4 到 5 个层
- 50 个单元
在某个点之后,增加层数或单元数对样本量几乎没有影响或者没有任何影响。但是,在对大型数据集进行分层时,这些增加可能对样本的设计或 Analytics 的性能产生负面影响。
对于样本设计,当您到达评估阶段时,您需要在每个层中有最低数量的错报,以便可靠地将错报推断至整个总体。如果相对于错报数而言,您具有太多的层,则推断可能出现问题。
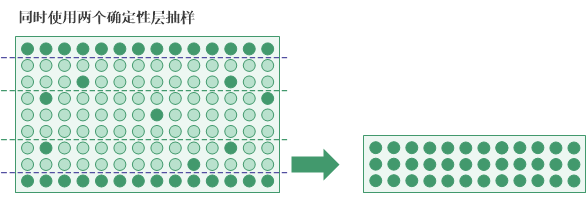
确定性层
定义确定性层是另一个可用的分层选项。您可以定义一个最高确定性层、一个最低确定性层或者两者。
使用确定性层有两个好处:
- 自动包括单独重大的项或高值项会被自动包括在样本中,而没有被随机选择方法排除的风险。
- 减小方差确定性层项被从样本量计算中排除。由于它们所具有的性质,如果在计算中包括高值项,则它们会显著增加总体差异和所需的样本量。
定义确定性层
要定义确定性层,您需要指定一个数值类型的截止值:
- 最高确定性层截止值所有大于或等于该截止值的键域账面价值会被自动选择并包括在样本中。
- 最低确定性层截止值所有小于或等于该截止值的键域账面价值会被自动选择并包括在样本中。
如果总体中存在大的负值,并且您想要自动包括它们,则使用最低确定性层是有用的。
确定性层未捕获的总体部分被使用随机选择方法抽样。
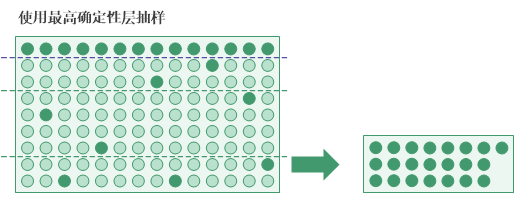
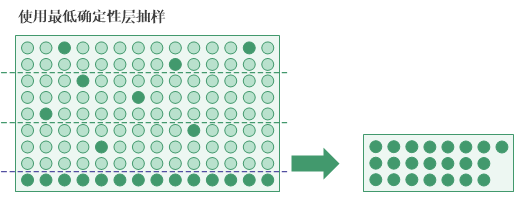
说明
根据数据性质的不同,随着您降低最高确定性层的截止值或者提高最低确定性层的截止值,总体样本量可能增加。
您应该避免过宽地设置截止值。如果您不确定将截止值设置到何处,请咨询抽样专家。
协调最高和最低确定性层
如果您决定在抽取样本时同时使用最高和最低确定性层,您需要考虑最高和最低截止值之间的关系:
- 确定性层不能重叠如果您指定的最高截止值小于最低截止值,则会出错。
- 在截止值之间留出足够的空间如果您指定的截止值彼此太近,则总体的大部分会被自动包括在样本中,从而无法达到抽样的目的。
传统变量抽样如何选择记录
传统变量抽样方法使用以下流程从 Analytics 表中选择样本记录:
- 您指定一个数值域作为抽样的基础。抽样单位是该表中的单个记录。
- 使用随机选择方法,Analytics 从该表中的记录中选择样本。
- 如果您使用分层方法,则会从每个层中随机选择大约相等的记录数。
- 如果您不使用分层,则会从整个总体中随机选择记录。
- 选定的记录被包括在抽样输出表中。
示例
在一个包含 300 个记录、划分为 3 个层的表中,Analytics 可以选择下列记录编号:
| 层 1 | 层 2 | 层 3 |
|---|---|---|
|
|
|
在一个包含 300 个记录的未分层表中,Analytics 可以选择下面显示的记录编号。您可以看到选定的记录编号的分布没有那么均匀。
说明
下面的这些记录编号被分组到三个列中以便进行比较,但这些列不代表层。
|
|
|
无偏样本选择
传统变量抽样是无偏的,它不是基于记录中包含的金额。每条记录将具有相同的选中概率,以包含到样本中。包含 $1000 金额的记录、包含 $250 金额的记录和包含 $1 金额的记录都具有相同的获选机会。
换句话说,任何给定记录的获选概率与它所包含的金额大小没有关系。
如果您想要确保选择包含最大金额的记录,请参见确定性层。