How fuzzy duplicates are grouped
When processing data, the fuzzy duplicates operation moves sequentially down the test field. The operation compares the first value in the field with every subsequent value, then it compares the second value in the field with every subsequent value, and so on, looping through the field until all the values have been compared with every subsequent value. It does not compare values with previous values.
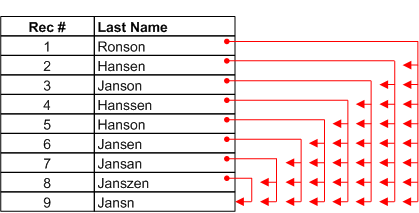
With each comparison, the operation determines whether the two compared values are fuzzy duplicates based on the difference settings you specified. (For information about the difference settings, see How the difference settings work.) If the two values are fuzzy duplicates, they are placed together in a group. Redundant matches are suppressed (explained later in this topic). The results of a fuzzy duplicates operation can contain multiple groups.
Group owner and group members
The first fuzzy duplicate in a group is the controlling value or ‘the owner’ of the group based solely on the fact that among the group members it appears first in the field you are testing. A test field containing the same data but sorted differently would produce different group owners, and differently constituted groups.
The group is identified using the record number of the group owner. The example below shows the results of testing a Last Name field. “Janson” forms a group (based on the difference settings), and “Janson” is record number 3 in the original table, so the group becomes Group 3.
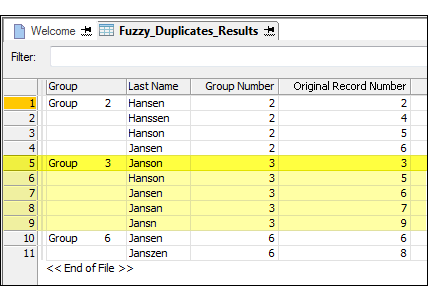
The group owner is not necessarily the correct value
The group owner is not necessarily the ‘correct’ or canonical value. It is simply the value from which the degree of difference you have specified is measured or calculated in the process of group formation. All the members of a group are within the specified degree of difference of the group owner. The members may or may not be within the specified degree of difference of one another.
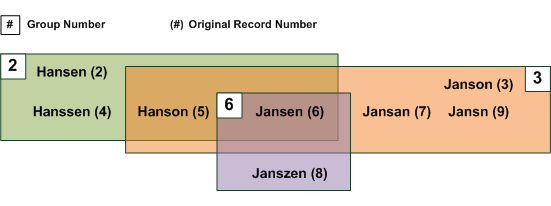
The diagram below provides a visual representation of the results in the output table above. The Difference Threshold is 1, which means that group members can differ from the group owner by a maximum of one (1) character. Note that some of the fuzzy duplicates appear in more than one group.
Exhaustive versus non-exhaustive results
To prevent results from becoming unmanageably large, the fuzzy duplicates feature is designed to produce groups that are non-exhaustive. Non-exhaustive means that individual fuzzy duplicate groups may not contain all the fuzzy duplicates in a test field that are within the specified degree of difference of the group owner. However, if a group owner is a fuzzy duplicate of another value in the test field, the two values will appear together in a group somewhere in the results, but not necessarily in the group associated with the group owner. So groups may be non-exhaustive, but the results, in total, are exhaustive.
If producing a single, exhaustive list of fuzzy duplicates for a specific value in the test field is important to your analysis, you can use the ISFUZZYDUP( ) function for this purpose. For more information, see Fuzzy duplicate helper functions.
Group formation in detail
The fuzzy duplicates feature creates non-exhaustive groups by excluding values from a group if they have appeared with the group owner in a previous group. This approach to group formation reduces the number of redundant fuzzy duplicate pairings, and helps control the overall size of the results.
The rules governing group formation are explained below, with associated examples.
| Rule | Explanation |
|---|---|
| The owner-member relation is non-reciprocal |
Because the fuzzy duplicates operation moves sequentially down the test field, group owners are associated with only those fuzzy duplicates that appear below them in the field, not with any that appear above them. In many cases, a group owner is a member of one or more groups that appear above it. However, the reverse is not true. The owners of the groups above are not members of the subsequent group. Once a value becomes a group owner it never appears in a subsequent group. In the example above, the Group 6 owner, “Jansen”, is a member of two previous groups, but the owners of those groups (“Hansen” and “Janson”), even though they are fuzzy duplicates of “Jansen”, are not members of Group 6. |
| If two values are members of a previous group, they will not be put together in a subsequent group if one of the values is the owner of the subsequent group |
In the example above, “Jansen”, “Jansan”, and “Jansn” are all members of Group 3. When “Jansen” becomes the Group 6 owner, “Jansan” and “Jansn” are not placed in the group, even though they are both fuzzy duplicates that appear below “Jansen” in the test field. |
| If two values are members of a previous group, they can appear together in a subsequent group if neither of the values is the owner of the subsequent group |
In the example above, “Hanson” and “Jansen” appear together in both Group 2 and Group 3. In this instance, appearance together in more than one group can occur because the degree of difference is being measured from the respective group owners, not from each other. |
|
Note On occasion, there can be exceptions to the second and third rules. During execution, the fuzzy duplicates operation stores temporary values. If the space allotted to these temporary values is filled, the result can be some group owners with one or more group members that are redundant. (The owner and the member have appeared together in a previous group.) The smaller the specified maximum size for fuzzy duplicate groups, the more likely it is that this redundancy can occur. |
|
Fuzzy Duplicates data processing and group formation
The table below shows the record-by-record processing of the example above.
| Input data | Data processed in descending sequence | Output results | |||
|---|---|---|---|---|---|
| Rec # | Last name | Fuzzy duplicates found | Group # | Group owner | Group members (exclude any that have appeared with the group owner in a previous group) |
|
1 |
Ronson |
|
|
|
|
|
2 |
Hansen |
Hanssen, Hanson, Jansen |
2 |
Hansen |
Hanssen, Hanson, Jansen |
|
3 |
Janson |
Hanson, Jansen, Jansan, Jansn |
3 |
Janson |
Hanson, Jansen, Jansan, Jansn |
|
4 |
Hanssen |
|
|
|
|
|
5 |
Hanson |
|
|
|
|
|
6 |
Jansen |
Jansan, Janszen, Jansn |
6 |
Jansen |
Janszen |
|
7 |
Jansan |
Jansn |
|
|
|
|
8 |
Janszen |
|
|
|
|
|
9 |
Jansn |
|
|
|
|
|
(Difference settings: Difference Threshold = 1, Difference Percentage = 99) |
|||||
Including exact duplicates in results
When processing data, the fuzzy duplicates operation always includes exact duplicates but it filters them out of the results unless you select Include Exact Duplicates in the Fuzzy Duplicates dialog box.
Exact duplicates are subject to the same group formation rules as fuzzy duplicates. They are excluded from a group if they have appeared with the group owner in a previous group. If the group owner and the excluded value are exact duplicates, it may appear that the excluded value should be in the owner’s group. However, the exclusion is consistent with the group formation rules because the two values have been in a previous group together.
The table below shows the processing of exact duplicates.
- “Ronson (3)” does not form a group with “Ronson (4)” because the two values are already together in Group 1.
- “Jansen (9)” is excluded from the group formed by “Jansen (8)” because the two values are already together in Group 2 and Group 5.
| Input data | Data processed in descending sequence | Output results | |||
|---|---|---|---|---|---|
| Rec # | Last name | Fuzzy duplicates and exact duplicates found | Group # | Group owner | Group members (exclude any that have appeared with the group owner in a previous group) |
|
1 |
Ronson |
Ronson (3), Ronson (4) |
1 |
Ronson |
Ronson (3), Ronson (4) |
|
2 |
Hansen |
Hanssen, Hanson, Jansen (8), Jansen (9) |
2 |
Hansen |
Hanssen, Hanson, Jansen (8), Jansen (9) |
|
3 |
Ronson |
Ronson (4) |
|
|
|
|
4 |
Ronson |
|
|
|
|
|
5 |
Janson |
Hanson, Jansen (8), Jansen (9), Jansan, Jansn |
5 |
Janson |
Hanson, Jansen (8), Jansen (9), Jansan, Jansn |
|
6 |
Hanssen |
|
|
|
|
|
7 |
Hanson |
|
|
|
|
|
8 |
Jansen |
Jansen (9), Jansan, Janszen, Jansn |
8 |
Jansen |
Janszen |
|
9 |
Jansen |
Jansan, Janszen, Jansn |
9 |
Jansen |
Janszen |
|
10 |
Jansan |
Jansn |
|
|
|
|
11 |
Janszen |
|
|
|
|
|
12 |
Jansn |
|
|
|
|
| (Difference settings: Difference Threshold = 1, Difference Percentage = 99, Include Exact Duplicates = Y) | |||||