コンセプト情報
クラスターは、1 つ以上の数値キー フィールドの類似した値に基づいて、テーブルのレコードをグループ化します。類似した値は、データセット全体のコンテキストで相互に近い値です。これらの類似した値は、特定されると、データのパターンを明らかにするクラスターを表します。
メモ
分析プログラムでクラスターを定期的に実行する場合は、Diligent Academy コースの「Analytics で CLUSTER コマンドを使用してデータグループを検索する (ACL 361)」を受講することをお勧めします (お客様のログインが必要です)。
他の Analytics グループ化コマンドとクラスターの違い
クラスターは他の Analytics グループ化コマンドとは異なります。
- クラスターでは、取引タイプや加盟店カテゴリ コードといった既存のデータ カテゴリや、数値の境界がハードコーディングされた定義済みの層でグループ化する必要がありません。代わりに、クラスターはデータ内の類似した数値(つまり、相互に近い値)に基づいてデータをグループ化します。
- 複数のフィールドに基づくクラスターは、ネストされない(非階層)結果を出力します。
クラスター対象のフィールドの選択
クラスターにより、存在することを知らないデータの有機的なグループを検出することができます。特に、機械学習を利用せずに、複数の数値フィールドに基づくクラスター(多次元クラスター)を特定することは困難です。この意味で、クラスターは説明的であり、監視されない機械学習の例です。
ただし、出力クラスターの有意性を保証するには、クラスターで選択するフィールド間に有意な関係が存在する必要があります。
単一フィールドのクラスター
単一フィールドでのクラスターは比較的簡単です。単一の値のセットに集中し、クラスターは値間の近さ(近似)に基づいて値をグループ化します。たとえば、金額フィールドをクラスター化し、値の範囲で金額が集中する場所を見つけることができます。
階層化などの従来のアプローチに対するクラスターの利点は、前もって、集中が存在する可能性がある場所を想定したり、任意の数値境界を作成したりする必要がないことです。クラスターは、特定のクラスター数の境界がある場所を検出します。
単一の数値フィールドでのクラスターの例
Ap_Trans テーブルを Invoice Amount でクラスター化し、値の範囲で金額が集中する場所を見つけることができます。想定される結果は、金額のほとんどが範囲の下限でクラスター化されることです。クラスターは、想定されたパターン通りになるかどうかを確認します。
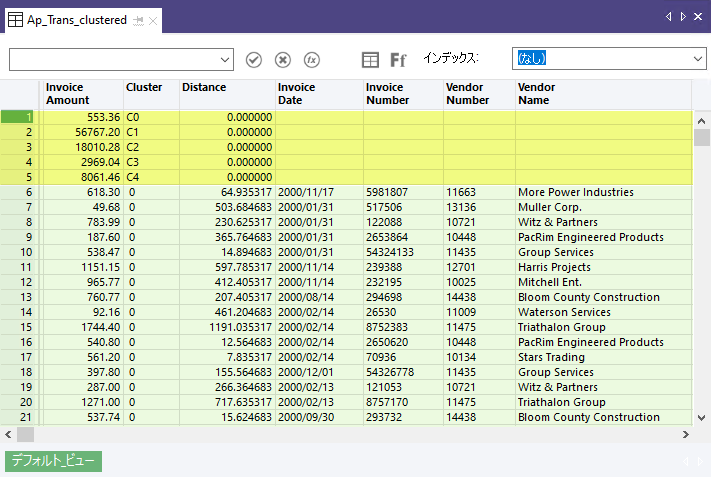
Invoice Amount フィールドを 5 つのクラスターにグループ化することを決め、クラスターを要約して、各クラスターのレコード数を検出します。
出力結果
次の出力結果では、最初の 5 つのレコードがシステムで生成され、指定した任意のクラスター数と同じになります。Invoice Amount フィールドでは、5 つのレコードが中心を示します。これは、請求金額の 5 つのクラスターそれぞれに対してクラスター アルゴリズムが計算する中心点です。たとえば、クラスター 3(C3)の中心は 2,969.04 です。詳細については、クラスター アルゴリズムの仕組みを参照してください。
システムで生成されたフィールドの下では、ソースデータ フィールドがクラスターにグループ化されます。これはクラスター 0 から始まります。Distance フィールドの値は、実際の請求金額から、そのクラスターの計算された中心値までの距離です。このため、たとえば、レコード 6 では、請求金額 618.30 から距離 64.935317 を差し引くと、中心値 553.36 と等しくなります。
メモ
実際の値が中心値より大きいか小さいかによって、距離値を加算または減算します。
クラスターの要約
Cluster フィールドを要約し、要約された出力をカウントで並べ替えると、次の結果が出力され、値の分布が想定通りであることを確認します。全体的に、請求金額が低い値に向かって大きく歪みます。(比較しやすいように中心値がテーブルに追加されています。)
クラスターの単一の大きい値は単独で異常値のように出現し、一般的に調査が必要です。
| クラスター | カウント | 中心値 |
|---|---|---|
| 0 | 73 | 553.36 |
| 3 | 16 | 2,969.04 |
| 4 | 8 | 8,061.46 |
| 2 | 4 | 18,010.28 |
| 1 | 1 | 56,767.20 |
複数のフィールドのクラスター
2 つ以上のフィールドでクラスター化するときには、フィールドを関連付ける方法を確認する必要があります。クラスターを使用して、仮定をテストできます。たとえば、会社が従業員の退職率に関心があるとします。管理者は、より若い給与が低い従業員に集中していると考えています。
クラスターを使用して、次の間に強い関係があるかどうかを検出できます。
- 勤続期間と従業員の年齢(2 次元クラスター)
- 勤続期間、従業員の年齢、給与(3 次元クラスター)
メモ
この分析では、取得された傷病休暇日数など、仮定とは明確に関係しないフィールドを含めないようにする必要があります。
出力クラスターの評価
クラスター アルゴリズムは、常に、指定されたクラスター数のテーブルを出力します。出力テーブルのすべてのレコードはクラスターにあります。
この時点では、クラスターに分析上の有意性または意味があるかどうかを評価する必要があります。アルゴリズムがクラスターのレコードをグループ化するからといって、必ずしも、グループ化が有意であるわけではありません。クラスターが有意なパターンを形成しているかどうかを確認する必要があります。クラスターがストーリーを伝えているかどうか
ヒント
クラスター出力テーブルをレポート ツールの散布図としてグラフ化し、各クラスターに別の色を割り当てると、出力クラスターの全体的な特性をすばやく、簡単に評価できます。
次の特性は、出力されたクラスターの有意性を評価する際に役立ちます。
- クラスターの一貫性 クラスターの個別の値すべてが比較的中心に近い位置にあるか、クラスターが分散しているか。クラスターの一貫性が高いほど、クラスターを構成する値の関係が強くなります。
- クラスターのサイズ 1 つまたは 2 つの大きいクラスターにほとんどの値が含まれているか。この場合、値が多数のクラスター間で比較的均等に分散しているデータセットに比べ、データセットが大きく偏っています。
- 異常値 重要なクラスターのいずれにも含まれない値を検討します。このような異常値は、追加で精査する必要がある項目を示している可能性があります。また、「内部異常値」を検討します。つまり、重要なクラスターに含まれていて、クラスターの外側の端にある値です。
メモ
上記の特性はすべて、クラスター評価でも、人間が行う主観的な方法です。クラスター評価ではさまざまな機械的な方法が存在しますが、そのような方法は本 Analytics ヘルプの対象範囲外です。
クラスター アルゴリズムの仕組み
Analytics のクラスターは、k 平均法アルゴリズムを使用します。これは、一般的な機械学習アルゴリズムです。k 平均法の詳細については、インターネットの説明をご覧ください。
アルゴリズムの概要は以下のとおりです。
k 平均法アルゴリズムは、反復プロセスを使用して、クラスターを最適化します。
| 順番検査 | アクション | 詳細 |
|---|---|---|
| 1 | クラスター数の指定 |
|
| 2 | クラスター中心の初期化 |
|
| 3 | 各データ点を最も近い中心に割り当てる |
|
| 4 | 中心の再計算 |
|
| 5 | 反復 |
|
クラスター数(K 値)の選択
データのクラスター化で使用する最適なクラスター数を決定するには、テストと実験が必要になることがあります。特定のデータセットに対する、正確な答えはありません。
最適なクラスター数を決定するためのガイドライン
- データを理解する 前もってデータセットを理解し、データのプロファイル、および値の明確な集中について概要を把握します。
- 最初は高めにする 最初は 8 ~ 10 の比較的多いクラスター数を選択します。
- 別のクラスター数を試す 複数回クラスターを実行し、毎回別の K 値を指定します。出力結果をレビューすると、クラスターを増やすのか減らすのかを判断できます。
- エルボー法 エルボー法を使用すると、クラスターの最適な数をプログラミングで特定します。最適な数とは、クラスターの一貫性が最も高く、追加クラスターの収穫逓減(既に一貫しているクラスターを分割しても限界的にしか一貫性を実現できないこと)を回避する点です。
エルボー法の結果を折れ線グラフでプロットし、「エルボー」または変曲点を視覚的に特定します。ここでは、クラスター数を増やしても一貫性は大きく改善されません。
Analytics で使用可能なエルボー法のスクリプトは ScriptHub からダウンロードできます。エルボー法 - K の残差平方和(SSE)(お客様のログインが必要です)
文字または日付時刻フィールドでクラスター化できますか。
一般的に、文字または日付時刻フィールドでクラスター化できません。クラスター アルゴリズムは数値だけを許可し、数値で計算を実行します(ユークリッド距離、中央値)
カテゴリ文字データ
ロケーション ID などのカテゴリ文字データが数値の形式になっていることがあります。あるいは、演算フィールドを使用して、文字カテゴリを作成する数値コードのセットにマッピングできます。このデータを数値データ型に変換し、クラスターで使用できます。ただし、結果のクラスターは有効になりません。数値ではない対象を表す数値に対して数学的演算を実行するためです。
たとえば、ロケーション ID のリストの平均に基づいて中心位置を計算すると、意味のない数値になります。計算は、ロケーション番号間の数学的な距離が何らかの実際の世界の測定可能な距離と等しいという無効な想定に基づいています。
物理的な距離を考慮する場合、ロケーション 1 とロケーション 9 の間の距離がロケーション 1 とロケーション 5 の間の距離の 2 倍であるということは無意味です。ロケーション 1 と 9 は隣で、ロケーション 5 が数マイル離れている可能性があります。
ロケーションや物理的な距離に関するクラスター分析では、使用する有効なデータは地理座標です。
スケールを表すカテゴリ データ
スケールを表すカテゴリ データでクラスターできます。たとえば、不可から優までの評価スケールと、対応する 1 ~ 5 のコードです。この場合、数値コードの平均には意味があります。
日付時刻データ
Analytics 関数を使用して、日付時刻データを数値データに変換できます。ただし、結果の数値データは連続していません。これは、数値の連続セットを想定するクラスター分析では問題となります。
たとえば、次の 3 つの数値は、日付としては、1 日違いです。ただし、数値としては、最初と 2 番目の数値にかなりのギャップまたは距離があります。
- 20181130
- 20181201
- 20181202
クラスター分析では、シリアル日付値を使用できます。シリアル日付は、1900 年 1 月 1 日からの経過日数を表す、整数の連続セットです。
手順
メモ
機械学習メニュー オプションが無効な場合は、Python エンジンがインストールされていない可能性があります。詳細については、ACL for Windows をインストールするを参照してください。
クラスター アルゴリズムの設定の指定
-
クラスター化するデータがあるテーブルを開きます。
-
Analytics メインメニューで、[機械学習 > クラスター]を選択します。
-
[クラスター数(k 値)]で、データをグループ化するために使用するクラスター数を指定します。
-
[最大繰り返し数]で、クラスター アルゴリズムで実行される反復数の上限を指定します。
-
[初期化数]で、ランダム中心の初期セットを生成する回数を指定します。
-
省略可能。[シード]を選択し、数値を入力します。
データ処理方法の指定
複数のキー フィールドでクラスター化する場合は、クラスターで使用する前に、前処理機能を使用して、フィールドのスケールを標準化してください。
一般的に、異なる数値フィールドのスケールと単位は異なります。たとえば、年間のドル金額を含む給料フィールドの範囲は 20,000 ~ 100,000 で、年を含む年齢フィールドの範囲は 18 ~ 70 であるという可能性があります。給料フィールドと年齢フィールドを使用してクラスター化し、調整を行わない場合、出力されたクラスターは、給料/年齢クラスターではなく、基本的に給料クラスターとなります。その場合、年齢数と比較して、給料の数値のサイズにクラスターが偏ります。
前処理を実行すると、次の方法によって、すべてのクラスターのキー フィールドのすべての値を調整するため、クラスター処理中に均等に重み付けすることができます。
| 前処理オプション | 説明 |
|---|---|
| 標準化 |
キー フィールド値の中央を平均ゼロ(0)にし、調整します。これは、値を z 得点相当(標準得点)に変換するプロセスです。 z 得点は、未加工の値を各フィールドの未加工の平均値から分離する標準偏差数の測定です。調整されたフィールドでは、平均値がゼロ(0)で表されます。表される未加工の値がフィールドの未加工の平均値より大きいか小さいかによって、z 得点が正または負になります。 メモ キー フィールドにほとんどゼロ以外の値が含まれている場合はこのオプションを使用します(密行列)。 z 得点の計算の例調整された年齢フィールドでは、元の年齢値 55 は、z 得点では 1.038189 になります。
|
| 単位分散になるようにスケール |
標準偏差で除算してキー フィールド値を調整しますが、中央を平均ゼロ(0)にしません。 メモ 1 つ以上のキー フィールドに多数のゼロ(0)値が含まれる場合にはこのオプションを使用します(疎行列)。 中心化せずに調整する例調整された年齢フィールドでは、元の年齢値 55 は、調整された値 4.406077 になります。
|
| なし | キー フィールドは中心化も調整もされません。クラスターを計算するときに、クラスターは中心化も調整もされない、元の値を使用します。 |
フィールドの選択
- [対象クラスター]リストから、テーブルのレコードをクラスター化するために使用する 1 つ以上のキー フィールドを選択します。
キー フィールドは数値である必要があります。
- 省略可能。[他のフィールド]リストで、出力テーブルに含める 1 つ以上の追加フィールドを選択します。
ヒント
隣接する複数のフィールドを選択するには、Shift キー + クリックを、隣接していない複数のフィールドを選択するには、Ctrl キー + クリックを利用できます。
コマンド入力の確定
-
現在のビューの中に処理から除外したいレコードがある場合は、[If]テキスト ボックスに条件を指定します。直接入力するか、または[If]ボタンをクリックし、式ビルダーを利用して IF ステートメントを作成します。
メモ
If 条件は、任意の範囲オプション(先頭、次へ、While)が適用された後に、テーブルに残るレコードに対してのみ評価されます。
IF ステートメントは、ビュー内のすべてのレコードを判断し、指定された条件を満たさないレコードを除外します。
- [保存先]テキスト ボックスに、出力テーブルの名前を指定します。
メモ
Analytics のテーブル名は、最長で 64 文字の英数字(拡張子 .FIL を含まない)に制限されます。名前にはアンダースコア文字(_)を使用できますが、他の特殊文字やスペースは使用できません。名前の先頭を数字にすることはできません。
- 省略可能。[詳細]タブ
- レコードのサブセットのみが処理されることを指定するには、[範囲]パネルでオプションのいずれかを選択します。
- 出力テーブルを自動的に開くようにするには、[出力テーブルの使用]をオンにします。
- [OK]をクリックします。