Concept Information
La mise en cluster regroupe les enregistrements dans une table selon des valeurs similaires dans un ou plusieurs champs clés numériques. Des valeurs similaires sont des valeurs qui sont proches ou proches les unes des autres dans le contexte de l'ensemble du jeu de données. Ces valeurs similaires représentent des clusters qui, une fois identifiés, révèlent des tendances dans les données.
Remarque
Si vous souhaitez faire de la mise en cluster un élément régulier de votre programme d'analyse, nous vous recommandons de suivre le cours de DiligentAcademy Rechercher des groupes de données à l'aide de la commande CLUSTER dans Analytics (ACL 361) (connexion du client requise).DiligentAcademy
En quoi la mise en cluster diffère-t-elle des autres commandes de regroupement Analytics ?
La mise en cluster diffère des autres commandes de regroupement Analytics dû aux éléments suivants :
- La mise en cluster ne nécessite pas de regroupement sur des catégories de données préexistantes telles que le type de transaction ou le code de catégorie commerçant, ou sur des strates prédéfinies ayant des limites numériques strictes. Au lieu de cela, la mise en cluster regroupe des données basées sur des valeurs numériques similaires à l'intérieur des données elles-mêmes, c'est-à-dire des valeurs proches les unes des autres.
- La mise en cluster basée sur plusieurs champs produit des résultats qui ne sont pas imbriqués (non hiérarchiques).
Choix des champs sur lesquels porte la mise en cluster
La mise en cluster des données vous permet de découvrir des regroupements organiques dans des données dont vous ne connaitriez peut-être pas l'existence sinon. En particulier, les clusters basés sur plusieurs champs numériques (clusters multidimensionnels) seraient difficiles à identifier sans l'aide du machine learning. En ce sens, la mise en clusters est exploratoire et constitue un exemple de machine learning non supervisé.
Toutefois, pour que les clusters de sortie soient significatifs, il doit exister une relation significative entre les champs que vous sélectionnez pour la mise en cluster.
Cluster sur un seul champ
La mise en cluster sur un seul champ numérique est relativement simple. Vous vous concentrez sur un ensemble unique de valeurs et la mise en cluster regroupe les valeurs en fonction de la proximité entre chacune des valeurs. Par exemple, vous pouvez mettre en cluster un champ Montant pour savoir où les montants sont concentrés sur la plage de valeurs.
L'avantage de la mise en cluster par rapport à une approche traditionnelle comme la stratification, c'est que vous n'avez pas à faire d'hypothèses, à l'avance, sur l'endroit où les concentrations peuvent exister ni à créer des limites numériques arbitraires. La mise en cluster permet de découvrir où se situent les limites d'un nombre donné de clusters.
Exemple de mise en cluster sur un seul champ numérique
Vous mettez en cluster la table Trans_Cf sur le champ Montant de la facture pour savoir où les montants sont concentrés sur la plage de valeurs. Vous vous attendez à ce que la plupart des montants soient mis en cluster dans la partie inférieure de la plage. La mise en cluster confirmera si le schéma attendu est effectivement le cas.
Vous décidez de regrouper le champ Montant de la facture en cinq clusters, puis de sous-totaliser les groupes pour découvrir combien d'enregistrements se trouvent dans chaque groupe.
Résultats de sortie
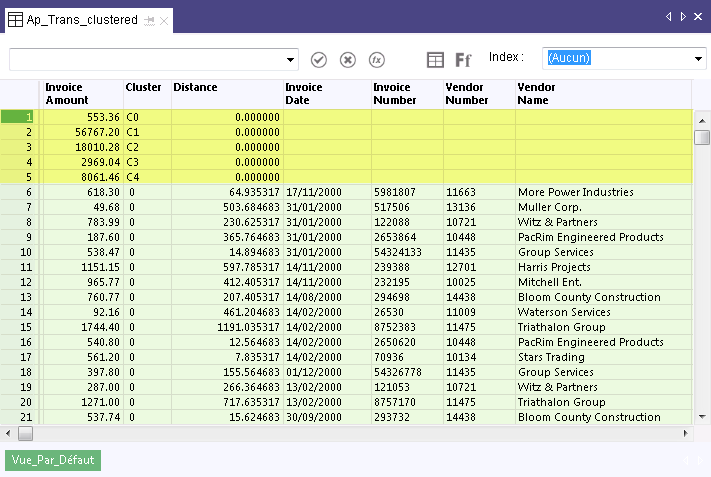
Dans les résultats de sortie présentés ci-dessous, les cinq premiers enregistrements sont générés par le système et correspondent au nombre de groupes que vous avez spécifié. Dans le champ Montant de la facture, les cinq enregistrements indiquent le centroïde, ou point central, que l'algorithme de mise en cluster calcule pour chacun des cinq groupes de montants de facture. Par exemple, le centroïde du groupe 3 ( C3 ) est de 2 969,04. Pour plus d'informations, consultez la section Fonctionnement de l'algorithme de mise en cluster.
Sous les champs générés par le système se trouvent les champs de données sources regroupés en clusters, à partir du cluster 0. La valeur dans le champ Distance correspond à la distance entre le montant réel de la facture et la valeur calculée du centroïde pour ce cluster. Ainsi, par exemple, dans l'enregistrement 6, le montant de la facture de 618,30 moins la distance de 64,935317 est égal à la valeur du centroïde de 553,36.
Remarque
Vous soustrayez ou ajoutez la valeur de la distance selon que la valeur réelle est supérieure ou inférieure à la valeur du centroïde.
Sous-total des clusters
Si vous sous-totalisez le champ Cluster, et que vous triez les résultats résumés par nombre, vous obtenez les résultats suivants, qui confirment que la distribution des valeurs est celle que vous attendiez. Dans l'ensemble, les montants des factures sont fortement biaisés vers des valeurs inférieures. (Valeurs des centroïdes ajoutées au tableau pour faciliter la comparaison)
La seule valeur importante dans un cluster semble être une valeur aberrante et devrait probablement être étudiée.
| Cluster | Compte | Valeur du centroïde |
|---|---|---|
| 0 | 73 | 553.36 |
| 3 | 16 | 2,969.04 |
| 4 | 8 | 8,061.46 |
| 2 | 4 | 18,010.28 |
| 1 | 1 | 56,767.20 |
Cluster sur plusieurs champs
Lorsque vous mettez en clusters sur deux champs ou plus, vous devez vous demander comment les champs peuvent être reliés. Vous pourriez utiliser la mise en cluster pour tester une hypothèse. Par exemple, une entreprise s'inquiète peut-être de son taux de rotation du personnel qui, selon la direction, est concentré parmi les employés plus jeunes et moins bien rémunérés.
Vous pourriez utiliser la mise en cluster pour découvrir s'il existe une relation forte entre ces éléments :
- la durée de rétention des employés et l'âge des employés (cluster bidimensionnel)
- la durée de rétention des employés, l'âge et le salaire des employés (cluster tridimensionnel)
Remarque
Pour cette analyse, vous devez éviter d'inclure des champs qui ne se rapportent pas clairement à l'hypothèse, comme le nombre de jours d'arrêt maladie pris.
Évaluation des clusters de sortie
L'algorithme de mise en cluster produira toujours un tableau avec le nombre spécifié de clusters. Chaque enregistrement de la table de sortie se trouvera dans un cluster.
À ce stade, vous devez évaluer si l'un ou l'autre de ces clusters a une importance ou une signification analytique. Ce n'est pas parce que l'algorithme regroupe les enregistrements dans un cluster que le regroupement est significatif. Vous devez vous demander si les clusters forment un modèle significatif. Racontent-ils une histoire ?
Astuce
La représentation graphique de la table de sortie du cluster sous la forme d'un graphique en nuage de points dans un outil de génération de rapports, avec une couleur différente pour chaque cluster, est le moyen le plus simple d'évaluer rapidement la nature globale des clusters de sortie.
Les caractéristiques suivantes peuvent vous aider à évaluer l'importance des groupes de sortie :
- Cohérence des clusters Les valeurs individuelles d'un cluster sont-elles toutes relativement proches du centroïde ou le cluster est-il quelque peu diffus ? Plus un cluster est cohérent, plus la relation entre les valeurs qui le composent est forte.
- Taille des clusters La majorité des valeurs sont-elles contenues dans une ou deux grands clusters ? Si c'est le cas, le jeu de données est significativement biaisé, par opposition à un jeu de données dont les valeurs sont réparties de manière relativement égale entre plusieurs clusters.
- Valeurs aberrantes Considérez les valeurs qui résistent à l'inclusion dans l'un des clusters importants. Ces valeurs aberrantes peuvent représenter des éléments qui méritent un examen plus approfondi. Tenez également compte des « valeurs aberrantes internes », c'est-à-dire des valeurs qui sont incluses dans un cluster important, mais à l'extrémité extérieure de ce cluster.
Remarque
Toutes les caractéristiques ci-dessus sont des méthodes humaines ou subjectives d'évaluation des clusters. Il existe diverses méthodes mathématiques d'évaluation des clusters, mais elles dépassent le cadre de l'Aide Analytics.
Fonctionnement de l'algorithme de mise en cluster
Dans Analytics, la mise en cluster utilise l'algorithme de partitionnement de k-moyennes, qui est un algorithme de machine learning répandu. Vous pouvez trouver des descriptions détaillées du partitionnement en k-moyennes sur Internet.
Un résumé de l'algorithme est présenté ci-dessous.
L'algorithme de partitionnement en k-moyennes utilise un processus itératif pour optimiser les clusters :
| Séquence | Action | Détails |
|---|---|---|
| 1 | Précisez le nombre de clusters |
|
| 2 | Initialiser les centroïdes du cluster |
|
| 3 | Affecter chaque point de données au centroïde le plus proche |
|
| 4 | Recalculer les centroïdes |
|
| 5 | Itérer |
|
Choix du nombre de clusters (valeur K)
Déterminer le nombre optimal de clusters à utiliser lors de la mise en cluster des données peut nécessiter des tests et des expériences pratiques. Pour un jeu de données donné, il n'y a pas de réponse exacte.
Instructions à suivre pour déterminer le nombre optimal de clusters :
- Familiarisez-vous avec les données Familiarisez-vous avec le jeu de données au préalable pour avoir une idée générale du profil des données et de toutes les concentrations évidentes de valeurs.
- Au départ, voyez grand Au départ, choisissez un nombre relativement élevé de clusters, de 8 à 10.
- Essayez un nombre différent de clusters Effectuez la mise en cluster plusieurs fois, en spécifiant une valeur K différente à chaque fois. Un examen des résultats de sortie peut vous aider à déterminer si vous avez besoin de plus ou de moins de clusters.
- Méthode Elbow Utilisez la méthode Elbow pour identifier de manière programmatique le nombre optimal de clusters. Le nombre optimal est le point auquel vous obtenez la meilleure cohérence de cluster tout en évitant les rendements décroissants de clusters supplémentaires qui n'améliorent que marginalement la cohérence au détriment de la division de clusters déjà cohérents.
Vous pouvez tracer les résultats de la méthode Elbow sur une courbe pour identifier visuellement « le coude », ou le point d'inflexion, où l'augmentation du nombre de clusters n'améliore pas significativement leur cohérence.
Un script de la méthode Elbow que vous pouvez utiliser dans Analytics est disponible en téléchargement sur ScriptHub : Méthode Elbow - Somme des carrés des erreurs (SSE) pour K (connexion client requise).
Puis-je effectuer un cluster sur des champs de caractères ou DateHeure ?
En règle générale, vous ne pouvez pas former de cluster sur des champs caractère ou DateHeure. L'algorithme de mise en cluster n'accepte que les nombres, et il effectue des calculs avec les nombres (distance euclidienne, moyenne).
Données de type caractère catégoriques
Vous pouvez disposer de données de caractères catégoriques, telles que les ID d'emplacement, sous la forme de chiffres. Vous pouvez aussi utiliser un champ calculé pour mapper les catégories de caractères à un ensemble de codes numériques que vous créez. Vous pouvez convertir ces données en type de données numériques et les utiliser pour la mise en cluster. Cependant, les clusters créés ne seraient pas valides parce que vous feriez des calculs mathématiques sur des nombres qui sont représentatifs de quelque chose de non numérique.
Par exemple, le calcul d'une position centroïdale basée sur la moyenne d'une liste d'ID d'emplacement donne un nombre vide de sens. Le calcul est basé sur l'hypothèse non valide que la distance mathématique entre les numéros d'emplacement équivaut à une distance mesurable dans le monde réel.
Si l'on considère la distance physique, dire que la distance entre le point 1 et le point 9 est deux fois plus grande que la distance entre le point 1 et le point 5 n'a aucun sens. Les emplacements 1 et 9 pourraient être l'un à côté de l'autre, et l'emplacement 5 pourrait être à des kilomètres de distance.
Dans le cas d'une analyse en cluster portant sur l'emplacement et la distance physique, les données valides à utiliser seraient les coordonnées géographiques.
Données catégoriques qui représentent une échelle
Vous pourriez mettre en cluster des données catégoriques qui représentent une échelle - par exemple, une échelle d'évaluation allant de Faible à Excellent, dont les codes numériques correspondants iraient de 1 à 5. Dans ce cas, une moyenne des codes numériques a du sens.
Données DateHeure
Vous pouvez utiliser les fonctions Analytics pour convertir les données DateHeure en données numériques. Toutefois, les données numériques qui en résultent ne sont pas continues, ce qui pose des problèmes pour l'analyse en cluster, qui suppose des ensembles continus de nombres.
Par exemple, les trois nombres suivants, en tant que dates, sont tous espacés d'un jour. Cependant, en tant que nombres, il y a un écart considérable, ou distance, entre le premier et le deuxième chiffre.
- 20181130
- 20181201
- 20181202
Vous pouvez utiliser les valeurs de dates sérielles dans l'analyse de cluster. Les dates sérielles sont un ensemble continu d'entiers représentant le nombre de jours qui se sont écoulés depuis le 1er janvier 1900.
Étapes
Remarque
Si les options du menu machine learning sont désactivées, c'est probablement parce que le moteur Python n'est pas installé. Pour plus d'informations, consultez la section Installer ACL pour Windows.
Spécifier les paramètres de l'algorithme de mise en cluster
-
Ouvrez la table contenant les données que vous souhaitez mettre en cluster.
-
Dans le menu principal Analytics, sélectionnez Machine learning > Cluster.Analytics
-
Dans Nombre de clusters (valeur K), spécifiez le nombre de clusters à utiliser pour regrouper les données.
-
Dans Nombre maximum d'itérations, spécifiez une limite supérieure pour le nombre d'itérations effectuées par l'algorithme de mise en cluster.
-
Dans Nombre d'initialisations, spécifiez le nombre de fois que vous souhaitez générer un ensemble initial de centroïdes aléatoires.
-
Facultatif. Sélectionnez Valeur de départ, puis saisissez un nombre.
Spécifier une méthode de prétraitement des données
Si vous regroupez plusieurs champs clés, vous devez utiliser la fonction Prétraitement pour normaliser l'échelle des champs avant de les utiliser pour la mise en cluster.
L'échelle et les unités des différents champs numériques varient souvent. Par exemple, un champ salaire contenant des dollars par an pourrait aller de 20 000 à 100 000, tandis qu'un champ âge contenant des années pourrait aller de 18 à 70. Si vous mettez en cluster à l’aide des champs salaire et âge, sans mise à l'échelle, les groupes de résultats seront essentiellement des groupes de salaires, faussés par la taille des chiffres des salaires par rapport aux chiffres des âges, plutôt que des groupes de salaires/âges.
Le prétraitement fournit les méthodes expliquées ci-dessous pour mettre à l'échelle toutes les valeurs dans tous les champs clés du cluster afin qu'elles soient pondérées de manière égale pendant le processus de mise en cluster.
| Option de pré-traitement | Description |
|---|---|
| Standardiser |
Les valeurs des champs clés sont centrées sur une moyenne de zéro (0) et mises à l'échelle, processus qui convertit les valeurs en leur équivalent en variable centrée réduite (score standard). La variable centrée réduite est une mesure du nombre d'écarts-types qui séparent une valeur brute de la moyenne brute pour chaque champ. Dans le champ à l'échelle, la moyenne est représentée par zéro (0) et les variables centrées réduites sont positives ou négatives selon que les valeurs brutes qu'elles représentent sont supérieures ou inférieures à la moyenne brute du champ. Remarque Utilisez cette option si les champs clés contiennent principalement des valeurs non nulles (« matrices denses »). Exemple de calcul d'une variable centrée réduiteDans un champ âge mis à l’échelle, la valeur brute de 55 est représentée par la variable centrée réduite de 1,038189.
|
| Mettre à l'échelle de l'écart en unité |
Les valeurs des champs clés sont mises à l'échelle en étant divisées par leur écart-type, mais elles ne sont pas centrées sur une moyenne de zéro (0). Remarque Utilisez cette option si un ou plusieurs champs clés contiennent un grand nombre de valeurs zéro (0) (« matrices éparses »). Exemple de mise à l'échelle sans centrageDans un champ âge mis à l’échelle, la valeur brute de 55 est représentée par la valeur mise à l'échelle de 4,406077.
|
| Aucun | Les valeurs des champs clés ne sont pas centrées ou mises à l'échelle. La mise en cluster utilise les valeurs brutes, non centrées et non mises à l’échelle, pour le calcul des clusters. |
Sélectionner les champs
- Dans la liste Cluster sur, sélectionnez un ou plusieurs champs clés à utiliser pour mettre en cluster les enregistrements dans la table.
Les champs clés doivent être de type numérique
- Facultatif. Dans la liste Autres champs, sélectionnez un ou plusieurs champs à inclure dans la table de sortie.
Astuce
Vous pouvez appuyer sur Ctrl tout en cliquant pour sélectionner plusieurs champs non adjacents et sur Maj tout en cliquant pour sélectionner plusieurs champs adjacents.
Finaliser les entrées des commandes
-
Si vous souhaitez exclure du traitement certains enregistrements de la vue en cours, saisissez une condition dans la zone de texte Si, ou cliquez sur Si pour créer une instruction IF à l'aide du Générateur d'expression.
Remarque
La condition Si est évaluée uniquement par rapport aux enregistrements restant dans une table après application des options relevant du champ d'application (Premiers, Suivants, Tant que).
L'instruction IF prend en compte tous les enregistrements de la vue et exclue ceux qui ne correspondent pas à la condition spécifiée.
- Dans la zone de texte À, indiquez le nom de la table de sortie.
Remarque
La longueur des noms des tables Analytics est limitée à 64 caractères alphanumériques, sans l’extension .FIL. Le nom peut inclure le caractère de soulignement ( _ ), mais aucun autre caractère spécial ni espace. Le nom ne peut pas commencer par un chiffre.
- Facultatif. Sur l'onglet Plus :
- Pour indiquer que seul un sous-ensemble d'enregistrements est traité, sélectionnez une des options dans le panneau Étendue.
- Sélectionnez Utiliser la table de sortie pour que la table de sortie s'ouvre automatiquement.
- Cliquez sur OK.