Analytics の自動機械学習を使用して、ラベルがないデータに関連付けられたクラスまたは数値を予測します。関心があるクラスまたは数値がデータに存在しない場合、データはラベルがありません。たとえば、機械学習を使用して、融資の債務不履行または将来の住宅価格を予測できます。
| 予測問題 | 予測タイプ | 説明 |
|---|---|---|
| 融資の債務不履行 | 分類 |
年齢、職業、信用評価などの申請者情報に基づいて、融資を実行した場合に債務不履行になる申請者を予測します。 つまり、申請者がクラス Default = Yes または Default = No に該当するかどうかということです。 |
| 将来の住宅価格 | 再帰 | 年齢、平方メートル、郵便番号、間取り、浴室・トイレの数などの特長に基づいて、将来の住宅の販売価格を予測します。 |
自動機械学習
Analytics の機械学習は「自動」です。2 つの関連するコマンドである学習と予測は、予測モデルの学習と、予測モデルをラベルがないデータセットに適用することに関連するすべての演算作業を実行します。Analytics の自動化によって、専門的なデータ科学技術を必要とせずに、自社データに対する機械学習を実行できます。
学習および予測ワークフロー
学習および予測ワークフローは 2 つの関連するプロセス、および 2 つの関連するデータセットから成ります。
- 学習プロセスは学習データセット(ラベル付き)を使用します
- 予測プロセスは新しいデータセット(ラベルなし)を使用します
学習 プロセス
学習プロセスが先に実行され、ラベル付きフィールド(対象フィールド)を含む学習データセットを使用します。
ラベル付きフィールドには、学習データセットの各レコードに関連付けられる、既知のクラス、既知の数値が含まれます。たとえば、借り手が融資で債務不履行になったかどうか(Y/N)、や住宅の販売価格です。
機械学習アルゴリズムを使用して、学習プロセスが予測モデルを生成します。学習プロセスは、実行している予測タスクに最適なモデルを検出するために、さまざまな異なるモデル順列を生成します。
予測 プロセス
予測プロセスは 2 番目に実行されます。学習プロセスによって生成される予測モデルが、学習データセットのデータに似ているデータを含む新しいラベルがないデータセットに適用されます。
融資の債務不履行情報や住宅販売価格などのラベル値は、将来のイベントであるため、新しいデータセットに存在します。
予測モデルを使用して、予測プロセスは、新しいデータセットの各ラベルがないレコードに関連付けられたクラスまたは数値を予測します。
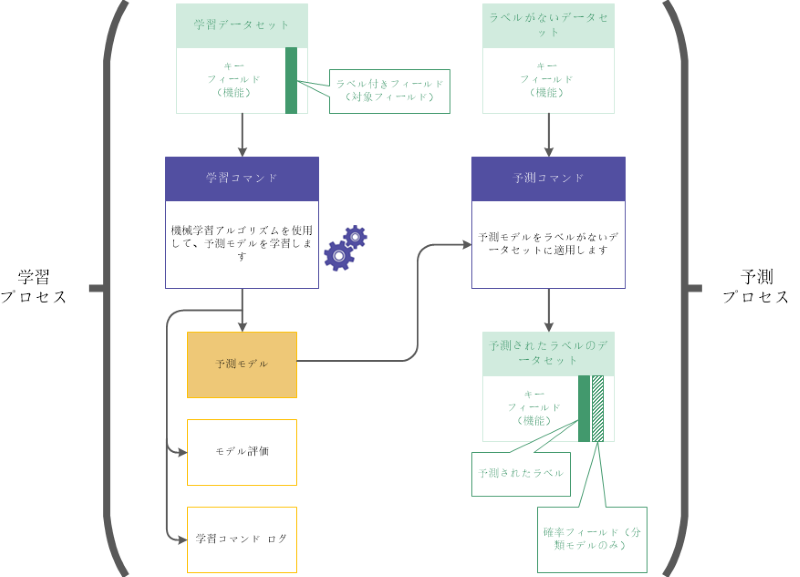
学習および予測ワークフローの詳細
| 順番検査 | プロセス | 説明 | データセットの例 |
|---|---|---|---|
| 1 |
トレーニング (学習コマンド) |
|
|
| 2 |
予測 (予測コマンド) |
|
|
処理時間
機械学習で必要な演算は時間がかかり、プロセッサーの負荷が高くなります。多数のフィールドを含む大きいデータセットを使用して予測モデルを学習するには数時間かかることがあり、通常は夜間に実行するタスクです。
学習プロセスに日付時刻キー フィールドを含めると、各日付時刻フィールドを使用して自動的に 10 個の合成特徴量を抽出するため、特にプロセッサーの負荷が高くなります。日付時刻合成特徴量は予測データの範囲を大幅に拡大できますが、関連性が考えられる場合にのみ日付時刻フィールドを含めてください。
ヒント
Analytics の機械学習に慣れる場合は、小さいデータセットを使用し、処理時間を管理可能に保つと、結果が比較的速く表示されます。
学習データセットのサイズを削減するためのストラテジー
さまざまなストラテジーを使用して、結果の予測モデルの精度に大幅な影響を与えずに、学習データセットのサイズ、関連付けられた処理時間を減らすことができます。
- 予測精度に影響せずに学習プロセスからフィールドを除外する関連のないフィールドと冗長なフィールドを除外します。
- 予測精度に影響しない場合には、学習プロセスからフィールドを除外します。ただし、日付時刻フィールドが関連していないことを想定するには注意してください。詳細については、日付時刻キー フィールドを参照してください。
- 学習データセットを抽出し、学習プロセスの入力として、抽出されたデータを使用します。考えられるサンプリング アプローチ:
- 大半のクラスをサンプリングしてデータ クラスのサイズのバランスを保ち、平均的な少数のクラス サイズを近似する
- 学習データセット全体のランダム サンプリング
- 機能に基づく階層化サンプリング
- クラスターに基づく階層化サンプリング
日付時刻キー フィールド
予測モデルを学習するときには、1 つ以上の日付時刻フィールドをキー フィールドとして使用できます。一般的に、日付時刻フィールドに存在する一意の値が多すぎると、フィールドは学習プロセスで適切なカテゴリのソースまたは特定可能な特徴量になりません。未加工の日付時刻データは、該当する対象フィールドに関連していないように見える場合もあります。
しかし、分類されると、日付時刻データが関連性をもつように見える場合があります。たとえば、調査しているイベントが特定の曜日または特定の時間に発生しているというパターンが見られる場合があります。
学習プロセスはは、未加工の日付時刻データを分類することで、各日付時刻フィールドから多数の合成特徴量を自動的に抽出します。これらの合成特徴量は、予測モデルを生成するアルゴリズムに含まれます。
日付時刻フィールドから抽出された合成特徴量
日付、時刻、日付時刻フィールドから自動的に抽出される合成特徴量の一覧は次のとおりです。
| 合成特徴量の説明 | 特徴量の種類 | 合成特徴量名 |
|---|---|---|
| 曜日 | 数値(1 ~ 7) | フィールド名_DOW |
| 月 | 数値(1 ~ 12) | フィールド名_MONTH |
| 四半期 | 数値(1 ~ 4) | フィールド名_QTR |
| 月初からの日数 | 数値(1 ~ 31) | フィールド名_DAY |
| 年初からの日数 | 数値(1 ~ 366) | フィールド名_DOY |
| 秒 | 数値(00 ~ 59) | フィールド名_SECOND |
| 時間 | 数値(1 ~ 24) | フィールド名_HOUR |
| 1 日の開始からの秒数 | 数値(1 ~ 86400) | フィールド名_SOD |
| 日の四分位 |
カテゴリー:
|
フィールド名_QOD |
| 日の八分位 |
カテゴリー:
|
フィールド名_OOD |
予測モデルの学習
メモ
学習プロセスで使用されるデータセットのサポートされる最大サイズは 1 GB です。
機械学習メニュー オプションが無効な場合は、Python エンジンがインストールされていない可能性があります。詳細については、ACL for Windows をインストールするを参照してください。
手順
学習プロセスの基本設定を指定する
- 学習データセットがある Analytics テーブルを開きます。
- Analytics メインメニューで、[機械学習 > 学習]を選択します。
- 学習プロセスに割り当てられた時間を指定します。
オプション 詳細 最適なモデルを検索する時間 予測モデルの生成とテスト、およびウィニングモデルの選択にかかる合計時間(分)。
モデルごとに、最大評価時間の 10 倍の検索時間を指定します。
モデル評価の最大時間 モデル評価ごとの最大実行時間(分)。
100 MB の学習データごとに 45 分を割り当てます。
メモ
学習プロセスの合計実行時間は、検索時間と最大モデル評価時間を最大で 2 倍した値の合計です。
これらの提案された時間割り当ては、処理時間と多様なモデル タイプの評価を可能にすることの間で、合理的なバランスを取っています。
- 使用する予測タイプを指定する:
- 分類 分類アルゴリズムを使用して、モデルを学習します
レコードが属するクラスまたはカテゴリを予測する場合は分類を使用します。
- 回帰 回帰アルゴリズムを使用して、モデルを学習します
ラベルがないデータセットのレコードに関連付けられた数値を予測する場合は回帰を使用します。
分類と回帰で使用される特定のアルゴリズムについては、学習アルゴリズムを参照してください。
- 分類 分類アルゴリズムを使用して、モデルを学習します
- [モデル スコアラー]ドロップダウンリストで、学習プロセス中に生成されたモデルのスコアを決定するときに使用するメトリクスを選択します。
生成されたモデルのうち、このメトリクスの最善値を有するモデルが保持され、そうでないモデルは破棄されます。
使用している予測タイプによって、異なるサブセットのメトリクスを使用できます。
予測タイプ 使用可能なメトリクス 分類 ログ損失 | AUC | 正確度 | F1 | 適合率 | 再現率 再帰 平均二乗誤差 | 平均絶対誤差 | R2 メモ
分類メトリクス AUC は、バイナリ データ(Yes/No、True/False などの 2 つのクラス)が含まれるターゲット フィールドで使用されるときにのみ有効です。
フィールドの選択
- [学習対象]リストで、モデルを学習するときに入力として使用する 1 つ以上のキー フィールドを選択します。
キー フィールドは、ラベルがないデータセットで対象フィールド値を予測する基礎となる機能です。キー フィールドは、文字、数値、日付時刻、または論理型を使用できます。合成特徴量は日付時刻キー フィールドから自動的に抽出されます。
メモ
文字フィールドは「分類的」である必要があります。つまり、カテゴリまたはクラスを特定し、一意の値の最大数以下でなければなりません。
最大値は[最大カテゴリ]オプション([ツール > オプション > コマンド)で指定されます。
ヒント
隣接する複数のフィールドを選択するには、Shift キー + クリックを、隣接していない複数のフィールドを選択するには、Ctrl キー + クリックを利用できます。
- [対象フィールド]リストから、対象フィールドを選択します。
対象フィールドは、入力キー フィールドに基づいて予測するようにモデルが学習されているフィールドです。
分類と回帰はさまざまな対象フィールド データ型で機能します。
- 分類 文字または論理対象フィールド
- 回帰 数値対象フィールド
モデルファイルと出力 Analytics テーブルの名前の指定
- [モデル名]テキストボックスで、学習プロセスで出力されたモデル ファイル出力の名前を指定します。
モデル ファイルには、学習データセットに最適なモデルが含まれます。モデル ファイルを予測プロセスに入力し、新しい未確認のデータセットに関する予測を生成します。
- [保存先]テキストボックスで、学習プロセスで出力されたモデル評価テーブル出力の名前を指定します。
モデル評価テーブルには、以下の 2 つの異なるタイプの情報が格納されています。
- スコアラー/メトリクス。これらは、学習プロセスによって生成されたモデル ファイルの予測パフォーマンスの定量的な推定、分類メトリクスまたは回帰メトリクスを意味します。
- 重要性/係数(降順):モデルによって生成された予測に対する各機能(予測印子)の寄与度を示す値。
メモ
Analytics のテーブル名は、最長で 64 文字の英数字(拡張子 .FIL を含まない)に制限されます。名前にはアンダースコア文字(_)を使用できますが、他の特殊文字やスペースは使用できません。名前の先頭を数字にすることはできません。
-
現在のビューの中に処理から除外したいレコードがある場合は、[If]テキスト ボックスに条件を指定します。直接入力するか、または[If]ボタンをクリックし、式ビルダーを利用して IF ステートメントを作成します。
メモ
If 条件は、任意の範囲オプション(先頭、次へ、While)が適用された後に、テーブルに残るレコードに対してのみ評価されます。
IF ステートメントは、ビュー内のすべてのレコードを判断し、指定された条件を満たさないレコードを除外します。
学習データセットのサブセットのみが使用されることを指定する(任意)
[詳細]タブで、[範囲]パネルのオプションのいずれかを選択します。
| 適用範囲オプション | 詳細 |
|---|---|
| すべて | (デフォルト) テーブル内のすべてのレコードを処理することを指定します。 |
| 先頭 |
テキストボックスに数を入力します。テーブル内の先頭レコードから処理が開始され、指定した件数のレコードのみが処理対象とされます。 |
| 次へ |
このオプションを選択してテキスト ボックスに数を入力すると、テーブル ビュー内で現在選択されているレコードから処理が開始され、指定した件数のレコードのみが処理対象とされます。 テキストボックスに数を入力します。テーブル ビュー内の現在選択したレコードから処理が開始され、指定した件数のレコードのみが処理対象とされます。行内のデータではなく、ビュー内の左端列で実際のレコード番号が選択されている必要があります。 |
| While |
WHILE ステートメントを使用して、特定の条件または条件のセットに基づいてテーブル内のレコードの処理を制限します。 [While] テキストボックスに条件を入力するか、または [While] ボタンをクリックし、式ビルダーを利用して WHILE ステートメントを作成します。 WHILE ステートメントでは、指定した条件が true と評価される間のみ、ビュー内のレコードを処理することができます。条件が false と評価されるとすぐに処理が終了し、それ以上レコードは判断されません。 While オプションは、"すべて"、"先頭"、または "次" オプションと組み合わせて使用することができます。1 つの制限に達するとすぐに、レコードの処理が停止します。 |
学習プロセスの詳細設定を指定する
- [詳細]タブ[交差検証分割数]を指定します。
既定の数値の 5 を使用するか、別の数値を指定します。有効な数値は 2 ~ 10 です。
分割は学習データセットの下位分割であり、モデル評価と最適化中に、交差検証プロセスで使用されます。
一般的に、モデルの学習時に、5 ~ 10 分割を使用すると、適切な結果が得られます。
ヒント
分割数が増えると、モデルの予測性能の推定値が改善されることがありますが、全体的な実行時間も長くなります。
- 省略可能。[シード]を選択し、数値を入力します。
Analytics の乱数ジェネレーターを初期化するために使用するシード値。
シードを省略した場合は、シード値がランダムに選択されます。
明示的にシード値を指定し、将来に学習プロセスを同じデータセットで複製したい場合は、それを記録します。
- 省略可能。線形モデルのみを学習し、スコアを決定するには、[線形モデルのみを評価する]を選択します。
このオプションを未選択にする場合、分類または再帰に関連するすべてのモデル タイプが評価されます。
メモ
データ セットが大きくなると、一般的に、線形モデルのみが含まれている場合に、学習プロセスがより短い時間で完了します。
線形モデルのみを含めると、出力の係数が保証されます。
- 省略可能。学習プロセスからこれらの下位プロセスを除外するには、[機能選択と前処理を無効にする]を選択します。
機能選択は、予測モデルを最適化する際に最も有用な学習データセットで、自動化されたフィールドの選択です。自動化された選択は予測性能を改善することがありますが、モデル最適化に関連するデータ量が減ります。
データ前処理は、学習データセットでの調整や標準化などの変換を実行し、学習アルゴリズムにより適したものにします。
注意
理由がある場合に限り、機能選択とデータ前処理を無効にしてください。
- [OK]をクリックします。
学習プロセスが開始し、指定した入力設定と経過した処理時間を示すダイアログボックスが表示されます。
予測モデルをラベルがないデータセットに適用する
メモ
機械学習メニュー オプションが無効な場合は、Python エンジンがインストールされていない可能性があります。詳細については、ACL for Windows をインストールするを参照してください。
手順
- ラベルがないデータセットがある Analytics テーブルを開きます。
- Analytics メインメニューで、[機械学習 > 予測]を選択します。
- [モデル]をクリックし、[ファイルを選択]ダイアログボックスで、前の学習プロセスによって生成されたモデル ファイルを選択し、[開く]をクリックします。
モデル ファイルのファイル拡張子は *.model です。
メモ
モデル ファイルは、ラベルのないデータセットと同じフィールドまたはほぼ同じフィールドのデータセットで学習されている必要があります。
バージョン 14.1 の Analytics で学習されたモデル ファイルは使用できません。バージョン 14.1 のモデル ファイルは、それ以降のバージョンの Analytics と互換性がありません。予測プロセスと使用するには、新しい予測モデルを学習してください。
- [保存先]テキストボックスで、予測プロセスで出力された Analytics テーブル出力の名前を指定します。
この出力テーブルには、学習プロセス中に指定したキー フィールドと、予測プロセスで生成された、以下の 1 つまたは 2 つのフィールドが含まれます。
- 予測 ラベルがないデータセットの各レコードに関連付けられた予測されたクラスまたは数値。
- 確率(分類のみ)予測されたクラスが正しい確率
メモ
Analytics のテーブル名は、最長で 64 文字の英数字(拡張子 .FIL を含まない)に制限されます。名前にはアンダースコア文字(_)を使用できますが、他の特殊文字やスペースは使用できません。名前の先頭を数字にすることはできません。
-
現在のビューの中に処理から除外したいレコードがある場合は、[If]テキスト ボックスに条件を指定します。直接入力するか、または[If]ボタンをクリックし、式ビルダーを利用して IF ステートメントを作成します。
メモ
If 条件は、任意の範囲オプション(先頭、次へ、While)が適用された後に、テーブルに残るレコードに対してのみ評価されます。
IF ステートメントは、ビュー内のすべてのレコードを判断し、指定された条件を満たさないレコードを除外します。
- 省略可能。ラベルがないデータセットのサブセットのみを処理するには、[詳細]タブで、[範囲]パネルのオプションのいずれかを選択します。
- [OK]をクリックします。
学習アルゴリズム
3 つの学習コマンド オプションは、予測モデルを学習するために使用される機械学習アルゴリズムを指示します。
| オプション | 学習ダイアログボックス タブ |
|---|---|
| 分類または再帰 | [メイン]タブ |
| 線形モデルのみを評価 | [詳細]タブ |
| 機能選択と前処理を無効にする | [詳細]タブ |
次のセクションでは、使用されるアルゴリズムを制御するオプションを要約します。
アルゴリズム名は、Analytics ユーザー インターフェイスに表示されません。学習コマンドによって最終的に選択されたモデルを生成するために使用されるアルゴリズムの生がログに表示されます。
メモ
アルゴリズムの詳細については、scikit-learn ドキュメントを参照してください。scikit-learn は、Analytics が使用する Python 用の機械学習ライブラリです。
