使用 Analytics 中的自动化机器学习预测与未标记数据相关联的种类或数值类型值。如果您感兴趣的种类或数值类型值在数据中不存在,、则数据是未标记的。例如,您可以使用机器学习来预测贷款违约或将来的房屋价格:
| 预测问题 | 预测类型 | 描述 |
|---|---|---|
| 贷款违约 | 分类 |
基于年龄、工作类别、信用评分等申请人信息,预测哪些申请人在获得贷款后会违约。 换句话说,申请人将落入“违约 = 是”这一种类还是落入“违约 = 否”这一种类? |
| 将来的房屋价格 | 回归 | 基于房龄、面积、邮政编码、卧室和浴室的数量等特征预测房屋的将来售价。 |
自动化机器学习
Analytics 中的机器学习是“自动化的”,这是因为两个相关命令 – 培训和预测 – 执行与培训和评估预测模型以及将该预测模型应用于未标记数据集相关联的所有计算工作。Analytics 提供的自动化功能使您可以让机器学习对公司数据进行处理,而无需您具备专用数据科学能力。
培训和预测工作流
培训和预测工作流由两个相关的流程以及两个相关的数据集组成:
- 培训流程使用一个培训数据集(标记的)
- 预测流程使用一个新数据集(未标记的)
培训 流程
首先使用一个包括标记域(也叫做目标域)的培训数据集执行培训流程。
标记域包含与培训数据集中的每个记录相关联的已知种类或已知数值类型值。例如,借款人是否就贷款发生违约 (Y/N) 或房屋的售价。
使用机器学习算法,培训流程生成一个预测模型。该培训流程生成一些不同的模型组合方式,以便发现最适合于您所执行的预测任务的模型。
预测 流程
预测流程被随后执行。它将培训流程的生成预测模型应用于一个新的未标记数据集,该数据集包含与培训数据集中的数据类似的数据。
新的数据集中不存在诸如贷款违约信息或房屋售价之类的标记值,因为这些是将来的事件。
使用预测模型,预测流程预测与新数据集中的每个未标记记录相关联的种类或数值类型值。
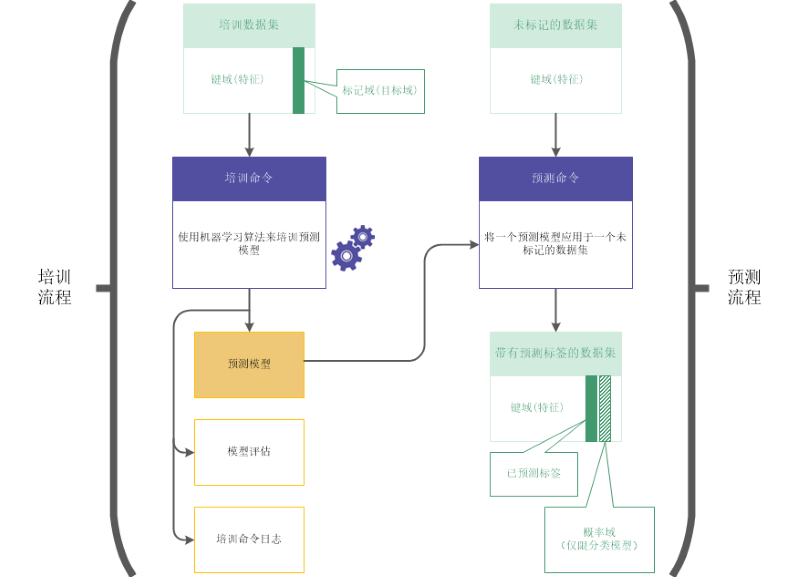
培训和预测工作流详细介绍
| 序列 | 进程 | 描述 | 数据集示例 |
|---|---|---|---|
| 1 |
培训 (培训命令) |
|
|
| 2 |
预测 (预测命令) |
|
|
处理时间
机器学习所需的计算很费时间,并且是处理器密集型的。使用包含许多域的大型数据集培训预测模型可能花费数小时,并且通常是一项您可能整晚运行的任务。
在培训流程中包括日期时间键域特别消耗处理器资源,因为每个日期时间域都被用于自动导出 10 个综合性特征。日期时间综合性特征可以显著扩展预测数据的范围,但是您仅应在您认为日期时间域可能相关时才应该包括它们。
提示
如果您刚刚开始熟悉 Analytics 中的机器学习,请使用小型数据集,以便您可以使处理时间保持可控状态,并且相对快速地看到结果。
减小培训数据集大小的策略
您可以使用不同的策略减小培训数据集的大小,缩短关联的处理时间,而不会显著影响生成的预测模型的准确性。
- 从培训流程中排除对预测准确性没有作用的域。排除无关的域和冗余的域。
- 如果日期时间域对预测准确性没有作用,请从培训流程中排除这些域。尽管如此,请慎重假定日期时间域不相关。有关详细信息,请参见日期时间键域。
- 对培训数据集进行抽样,并且使用抽样数据作为培训流程的输入。可能的抽样方法包括:
- 通过将大种类抽样至近似的平均小种类,平衡数据种类的大小
- 对整个培训数据集进行随机抽样
- 基于特征进行分层抽样
- 基于聚类进行分层抽样
日期时间键域
培训预测模型时,您可以使用一个或多个日期时间域作为键域。通常,日期时间域中存在过多的唯一值,以至于该域不能充当培训流程的合适类别源或者可识别特征。原始日期时间数据还可能显得与您的目标兴趣域无关。
但是,一旦被归类,日期时间数据可能具有相关性。例如,您所检查的事件可能在一周中的某些日子或者一天中的某些时间发生。
培训流程通过对原始日期时间数据进行分类,自动从每个日期时间域中导出一些综合性特征。这些综合性特征随后被包括在生成预测模型的算法中。
从日期时间域中导出的综合性特征
下面列出了从日期、时间或日期时间域中导出的综合性特征。
| 综合性特征描述 | 特征类型 | 综合性特征名称 |
|---|---|---|
| 周几 | 数值(1 到 7) | 域名称_DOW |
| 月份 | 数值(1 到 12) | 域名称_MONTH |
| 季度 | 数值(1 到 4) | 域名称_QTR |
| 自该月份开始以来的天数 | 数值(1 到 31) | 域名称_DAY |
| 自该年度开始以来的天数 | 数值(1 到 366) | 域名称_DOY |
| 秒数 | 数值(00 到 59) | 域名称_SECOND |
| 时 | 数值(1 到 24) | 域名称_HOUR |
| 自该日开始以来的秒数 | 数值(1 到 86400) | 域名称_SOD |
| 日四分位 |
类别:
|
域名称_QOD |
| 日八分位 |
类别:
|
域名称_OOD |
培训预测模型
步骤
指定培训流程的基本设置
- 打开包含培训数据集的 Analytics 表。
- 从 Analytics 主菜单中选择机器学习 > 培训。
- 指定分配给培训流程的时间:
选项 详细信息 用于搜索最佳模型的时间 生成和测试预测模型以及选择获胜模型所花费的总时间(分钟)。
指定一个起码为每个模型的最大评估时间的 10 倍的搜索时间。
模型评估最大时间 每个模型评估的最大运行时间(分钟)。
请为每 100 MB 的培训数据分配 45 分钟。
说明
培训流程的总运行时间为搜索时间加上最多两倍的最大模型评估时间。
建议的时间分配策略可在处理时间和允许对多种模型类型进行评估之间建立合理的平衡。
- 指定要使用的预测类型:
- 分类 使用分类算法培训模型
如果您想要预测一个未标记数据集中的记录属于哪个种类或类别,请使用分类。
- 回归使用回归算法培训模型
如果您想要预测与未标记数据集中的记录相关联的数值类型值,请使用回归。
有关用于分类和回归的具体算法的信息,请参见培训算法。
- 分类 使用分类算法培训模型
- 在模型评价指标下拉列表中,选择要在对培训流程中生成的模型进行评价时使用的评价指标。
生成的模型中,包含此度量最佳值的模型被保留,其余的则被放弃。
根据所使用的预测类型,可使用不同的评价指标子集:
预测类型 可用指标 分类 记录损失 | AUC | 准确性 | F1 | 精确性 | 回忆 回归 均方误差 | 平均绝对误差 | R2 说明
分类标准 AUC 仅当与包含二进制数据 — 即两个种类,如是/否或者真/假的目标域时才有效。
选择域
- 从培训依据列表中,选择一个或多个要在培训该模型时用作输入的键域。
键域是未标记的数据集中构成目标域值预测基础的特征。键域可以是字符、数值、日期时间或者逻辑类型。综合性特征被从日期时间键域中自动导出。
说明
字符域必须是“类别的”。也就是说,它们必须标识类别或者种类,并且不能超过最大的唯一值个数。
该最大数量由最大类别数选项(工具 > 选项 > 命令)指定。
提示
您可以使用 Ctrl+单击选择多个不相邻的域,使用 Shift+单击选择多个相邻的域。
- 从目标域列表中选择目标域。
目标域是要培训该模型基于输入键域进行预测的域。
分类和回归适合于不同的目标域数据类型:
- 分类一个字符或逻辑目标域
- 回归一个数值目标域
命名该模型文件和输出 Analytics 表
- 在模型名称文本框中,指定该培训流程所输出的模型文件的名称。
该模型文件包含最适合于培训数据集的模型。您将把该模型文件输入到预测流程以生成有关未被发现的新数据集的预测。
- 在到文本框中,指定该培训流程所输出的模型评估表的名称。
模型评估表包含两种不同类型的信息:
- 评价指标/度量对于分类或回归度量,为培训流程输出的模型文件的预测性能的定量估计
- 重要性/系数按降序排列,值指示每个特征(预测器)对模型预测的贡献程度
说明
Analytics 表名称限制为 64 个字母数字字符,且不包括 .FIL 扩展名。该名称可以包括下划线字符 ( _ ),但不能包括其他特殊字符或任何空格。该名称不能以数字开头。
-
如果当前视图中有想要从处理中排除的记录,请在如果文本框中输入一个条件,或单击如果使用表达式生成器创建 IF 声明。
说明
在应用任何范围选项(前、后、当)之后,仅针对表中的剩余记录评估如果条件。
IF 声明中考虑到了视图中的所有记录,滤除那些不满足指定条件的记录。
指定只使用该培训数据集的一个子集(可选)
在更多选项卡上,选择范围面板中的选项之一:
| 范围选项 | 详情 |
|---|---|
| 全部 | (默认)指定处理表中的所有记录。 |
| 前 |
在文本框中输入一个数字。从表中的第一个记录开始处理,并且仅包括指定数量的记录。 |
| 下一页 |
选择该选项并在文本框中输入一个数字,则会从表视图中当前选择的记录开始处理,并且仅包括指定数量的记录。 在文本框中输入一个数字。从表视图中当前选择的记录开始处理,并且仅包括指定数量的记录。必须选中视图最左边的列中的实际记录数量,而不是行中的数据。 |
| While |
使用 WHILE 语句,根据特定条件或条件组来限制对表中记录的处理。 在 While 文本框中输入一个条件,或者单击 While 使用表达式生成器创建一个 WHILE 语句。 只有当指定条件值为真时,WHILE 声明才允许对视图中的记录进行处理。当条件变为假时,处理立即终止,不再考虑剩余的记录。 可将当选项与全部、前或后选项结合使用。在达到一个限制后,请立即记下处理步骤。 |
指定该培训流程的高级设置
- 在更多选项卡上,指定交叉验证折叠数。
保留默认数字 5,或者指定一个不同的数字。有效的数字为从 2 到 10。
折叠是培训数据集的子集,并且在模型评估和优化过程中被用在交叉验证流程中。
通常,在培训模型时使用 5 到 10 个折叠可产生良好的结果。
提示
增加折叠数可以生成更好的模型预测性能估计,但是也会增加总运行时间。
- 可选。选择种子,然后输入一个数字。
种子值被用来在 Analytics 中初始化随机数生成器。
如果您不选择种子,则 Analytics 会随机选择种子值。
如果您想要在将来使用相同数据集重复该培训流程,请明确指定一个种子值并且记下来。
- 可选。如果您想要仅对线性模型进行培训和评分,请选择仅评估线性模型。
如果您使此选项保持未选定状态,则会评估与分类或回归相关的所有模型类型。
说明
使用较大的数据集,如果您只包括线性模型,则该培训流程通常会更快地完成。
仅包括线性模型可保证输出中的系数。
- 可选。如果您想要从培训流程中排除这些子流程,请选择禁用特征选择和预处理。
特征选择即自动选择培训数据集中在优化预测模型方面最有用的域。自动选择可以提高预测性能,并且减少在模型优化中涉及的数据量。
数据预处理对培训数据集执行缩放和标准化等变换,以使其更适合于培训算法。
警告
您应该只禁用特征选择和数据预处理(如果您有理由这样做)。
- 单击确定。
培训流程将启动,并且出现一个对话框,其中显示您指定的输入设置,以及所经过的处理时间。
将一个预测模型应用于一个未标记的数据集
说明
如果机器学习菜单选项被禁用,则 Python 引擎很可能未安装。有关详细信息,请参见安装 ACL for Windows。
步骤
- 打开包含未标记数据集的 Analytics 表。
- 从 Analytics 主菜单中选择机器学习 > 预测。
- 单击模型,然后在选择文件对话框中,选择一个由以前的培训流程输出的模型文件,然后单击打开。
模型文件具有 *.model 文件扩展名。
说明
培训该模型文件时所使用的数据集必须包含与未标记的数据集相同或基本上相同的域。
您不能使用在 Analytics 的版本 14.1 中培训的模型文件。版本 14.1 模型文件不与后续版本的 Analytics 兼容。培训一个要用于该预测流程的新预测模型。
- 在到文本框中,指定该预测流程所输出的 Analytics 表的名称。
输出表包含您在培训流程中指定的键域,以及一个或两个由预测流程生成的域:
- 已预测 与未标记的数据集中的每个记录相关联的已预测种类或数值类型值
- 概率(仅分类)预测类准确的概率
说明
Analytics 表名称限制为 64 个字母数字字符,且不包括 .FIL 扩展名。该名称可以包括下划线字符 ( _ ),但不能包括其他特殊字符或任何空格。该名称不能以数字开头。
-
如果当前视图中有想要从处理中排除的记录,请在如果文本框中输入一个条件,或单击如果使用表达式生成器创建 IF 声明。
说明
在应用任何范围选项(前、后、当)之后,仅针对表中的剩余记录评估如果条件。
IF 声明中考虑到了视图中的所有记录,滤除那些不满足指定条件的记录。
- 可选。要仅处理未标记数据集的一个子集,请在更多选项卡上,选择范围面板中的选项之一。
- 单击确定。
培训算法
三个培训命令选项指定将哪些机器学习算法用于培训预测模型:
| 选项 | 培训对话框选项卡 |
|---|---|
| 分类或者回归 | 主要选项卡 |
| 仅评估线性模型 | 更多选项卡 |
| 禁用特征选择和预处理 | 更多选项卡 |
下列各节总结了这些选项如何控制使用哪些算法。
这些算法的名称不出现在 Analytics 用户界面中。用于生成培训命令最终选择的模型的算法的名称出现在日志中。
说明
有关各种算法的详细信息,请参阅 scikit-learn 文档。Scikit-learn 是 Analytics 使用的 Python 机器学习库。
分类算法
![]() 已使用的算法
已使用的算法
![]() 未使用的算法
未使用的算法
| 算法名称 | 总是被包括 | 仅评估线性模型 | 禁用特征选择和预处理 | ||
|---|---|---|---|---|---|
| 未选定的选项(默认) | 选定的选项 | 未选定的选项(默认) | 选定的选项 | ||
| 算法类型: 分类器 | |||||
| 逻辑回归 |
|
||||
| 线性支持向量机 |
|
||||
| 随机森林 |
|
|
|||
| 极度随机树 |
|
|
|||
| 梯度增压机 |
|
|
|||
| 算法类型:特征预处理器 | |||||
| 一个热编码 – 类别特征 |
|
||||
| 快速独立组件分析 |
|
|
|||
| 特征集聚 |
|
|
|||
| 主要成分分析 – 奇异值分解 |
|
|
|||
| 二次多项式特征 |
|
|
|||
| 二值化器 |
|
|
|||
| 鲁棒缩放器 |
|
|
|||
| 标准缩放器 |
|
|
|||
| 最大绝对缩放器 |
|
|
|||
| 最小最大缩放器 |
|
|
|||
| 规范化器 |
|
|
|||
| Nystroem 核近似 |
|
|
|||
| RBF 核近似 |
|
|
|||
| 零计数器 |
|
|
|||
| 算法类型:特征选择器 | |||||
| 家族模样误差率 |
|
|
|||
| 最高分百分位数 |
|
|
|||
| 差异阈值 |
|
|
|||
| 递归特征消除 |
|
|
|||
| 重要性权重 |
|
|
|||
回归算法
![]() 已使用的算法
已使用的算法
![]() 未使用的算法
未使用的算法
| 算法名称 | 总是被包括 | 仅评估线性模型 | 禁用特征选择和预处理 | ||
|---|---|---|---|---|---|
| 未选定的选项(默认) | 选定的选项 | 未选定的选项(默认) | 选定的选项 | ||
| 算法类型:回归器 | |||||
| 弹性网 |
|
||||
| Lasso |
|
||||
| Ridge |
|
||||
| 线性支持向量机 |
|
||||
| 随机森林 |
|
|
|||
| 极度随机树 |
|
|
|||
| 梯度增压机 |
|
|
|||
| 算法类型:特征预处理器 | |||||
| 一个热编码 – 类别特征 |
|
||||
| 快速独立组件分析 |
|
|
|||
| 特征集聚 |
|
|
|||
| 主要成分分析 – 奇异值分解 |
|
|
|||
| 二次多项式特征 |
|
|
|||
| 二值化器 |
|
|
|||
| 鲁棒缩放器 |
|
|
|||
| 标准缩放器 |
|
|
|||
| 最大绝对缩放器 |
|
|
|||
| 最小最大缩放器 |
|
|
|||
| 规范化器 |
|
|
|||
| Nystroem 核近似 |
|
|
|||
| RBF 核近似 |
|
|
|||
| 零计数器 |
|
|
|||
| 算法类型:特征选择器 | |||||
| 家族模样误差率 |
|
|
|||
| 最高分百分位数 |
|
|
|||
| 差异阈值 |
|
|
|||
| 重要性权重 |
|
|
|||