Informações do conceito
A clusterização agrupa os registros de uma tabela de acordo com valores similares em um ou mais campos-chave numéricos. Valores similares são valores próximos ou semelhantes entre si no contexto de todo o conjunto de dados. Esses valores similares representam clusters que, uma vez identificados, revelam padrões nos dados.
Nota
Se quiser usar regularmente a clusterização no seu programa de análises, recomendamos que você faça o curso da Academia da Diligent Encontrando grupos de dados usando o comando CLUSTER no Analytics (ACL 361) (exige login do cliente).
A diferença entre a clusterização e outros comandos de agrupamento do Analytics
A clusterização é diferente dos outros comandos de agrupamento do Analytics:
- A clusterização não exige agrupamento por valores exatos ou categorias de dados já existentes como tipo de transação ou código de categoria de comerciante, ou por estratos predefinidos com limites numéricos fixos. Em vez disso, a clusterização agrupa os dados de acordo com valores numérico similares dentro dos próprios dados, ou seja, valores próximos ou semelhantes entre si.
- A clusterização baseada em mais de um campo gera resultados que não são aninhados (não hierárquicos).
Escolha dos campos usados para a clusterização
A clusterização de dados permite descobrir agrupamentos orgânicos nos dados que de outra forma você desconhecia. Mais especificamente, os clusters baseados em vários campos numéricos (clusters multidimensionais) seriam de difícil identificação sem o auxílio do aprendizado de máquina. Nesse sentido, a clusterização é exploratória e um exemplo de aprendizado de máquina não supervisionado.
No entanto, para que os clusters gerados sejam significativos, deve existir uma relação significativa entre os campos escolhidos para a clusterização.
Clusterizar com base em um único campo
A clusterização com base em um único campo numérico é relativamente simples. Você se concentra em um único conjunto de valores e a clusterização agrupa os valores de acordo com a proximidade ou semelhança dos valores. Por exemplo, você pode clusterizar um campo de quantidade para descobrir onde as quantidades estão concentradas no intervalo de valores.
A vantagem da clusterização sobre uma abordagem tradicional, como estratificação, é que você não precisa supor previamente onde as concentrações podem existir, nem criar limites numéricos arbitrários. A clusterização descobre onde estão os limites de qualquer número de clusters específico.
Exemplo de clusterização com base em um único campo numérico
Você clusteriza a tabela Trans_Cp pelo campo Valor da fatura para descobrir onde as quantidades estão concentradas no intervalo de valores. Sua expectativa é que a maioria das quantidades estarão clusterizadas na parte inferior do intervalo. A clusterização confirmará se sua expectativa está correta.
Você decide agrupar o campo Valor da fatura em cinco clusters e sumarizá-los para descobrir quantos registros existem em cada cluster.
Os resultados de saída
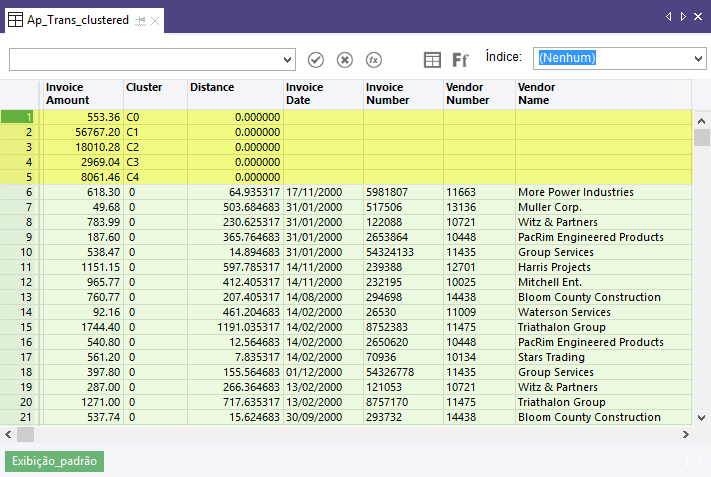
Nos resultados de saída mostrados abaixo, os cinco primeiros registros são gerados pelo sistema e são equivalentes ao número desejado de clusters especificado. No campo Valor da fatura, os cinco registros mostram o centroide, ou ponto central, calculado pelo algoritmo de clusterização para cada um dos cinco clusters de valores de fatura. Por exemplo, o centroide do cluster 3 (C3) é 2.969,04. Para obter mais informações, consulte Como funciona o algoritmo de clusterização.
Por trás dos campos gerados pelo sistema, estão os campos de dados de origem agrupados em clusters a partir do cluster 0. O valor no campo Distância é a distância entre o valor real da fatura e o valor de centroide calculado para esse cluster. Por exemplo, no registro 6, o valor da fatura de 618,30 menos a distância de 64,935317 equivale ao valor de centroide de 553,36.
Nota
Você subtrai ou adiciona o valor da distância dependendo de o valor real ser maior ou menor que o do centroide.
Sumarização dos clusters
Se você sumarizar o campo Cluster e ordenar a saída sumarizada por contagem, obterá os seguintes resultados, que confirmam que a distribuição dos valores é a esperada. No geral, os valores da fatura estão fortemente distorcidos para valores menores. (Valores dos centroides adicionados à tabela para facilitar a comparação.)
O único grande valor em um cluster aparenta ser um valor discrepante e provavelmente merece uma investigação.
| Cluster | Contagem | Valor do centroide |
|---|---|---|
| 0 | 73 | 553,36 |
| 3 | 16 | 2.969,04 |
| 4 | 8 | 8.061,46 |
| 2 | 4 | 18.010,28 |
| 1 | 1 | 56.767,20 |
Clusterizar com base em vários campos
Quando você clusteriza com base em dois ou mais campos, precisa se perguntar como os campos podem estar relacionados. Você pode usar a clusterização para testar uma hipótese. Por exemplo, uma empresa pode estar preocupada com a taxa de rotatividade dos funcionários que, segundo a gerência, está concentrada em funcionários jovens com menor salário.
Você pode usar a clusterização para descobrir se há uma relação forte entre:
- duração da retenção de funcionários e idade dos funcionários (clusterização bidimensional)
- duração da retenção de funcionários, idade dos funcionários e salário (clusterização tridimensional)
Nota
Para essa análise, você precisa evitar a inclusão de qualquer campo que não esteja claramente relacionado à hipótese, como o número de dias em licença médica.
Avaliação de clusters de saída
O algoritmo de clusterização geral sempre uma tabela com o número especificado de clusters. Cada registro na tabela de saída estará em um cluster.
Nesse ponto, você precisa avaliar se os clusters têm significado analítico. O agrupamento de registros em um cluster pelo algoritmo não significa necessariamente que o agrupamento tem significado. Você precisa se perguntar se os clusters formam um padrão significativo. Eles têm uma história para contar?
Dica
O uso de uma ferramenta de relatórios para gerar um gráfico de dispersão com base na tabela de saída de clusters, com cada cluster representado com uma cor diferente, é a forma mais fácil de avaliar rapidamente a natureza geral dos clusters de saída.
As seguintes características podem ajudar a avaliar o significado dos clusters de saída:
- Coerência do cluster Os valores individuais em um cluster estão todos relativamente próximos ao centroide ou o cluster é algo difuso? Quanto mais coerente for um cluster, mais forte será a relação entre os valores que compõem o cluster.
- Tamanho do cluster A maioria dos valores está contida em um ou dois clusters grandes? Se isso for verdade, o conjunto de dados está consideravelmente distorcido em comparação a um conjunto de dados em que os valores estão distribuídos de forma razoavelmente uniforme entre os clusters.
- Valores discrepantes Considere os valores que resistem à inclusão em qualquer um dos clusters significativos. Esses valores discrepantes podem representar itens que merecem uma investigação adicional. Considere também os "valores discrepantes internos", ou seja, os valores incluídos em um cluster significativo, mas em sua extremidade externa.
Nota
Todas as características acima são métodos humanos ou subjetivos de avaliação de clusters. Existem vários métodos matemáticos de avaliação de clusters, mas eles estão além do escopo da ajuda do Analytics.
Como funciona o algoritmo de clusterização
A clusterização no Analytics usa o algoritmo de clusterização K-means, que é um algoritmo popular de aprendizado de máquina. Você pode encontrar descrições detalhadas de clusterização K-means na Internet.
Veja a seguir um resumo do algoritmo.
O algoritmo de clusterização K-means usa um processo interativo para otimizar clusters:
| Sequência | Ação | Detalhes |
|---|---|---|
| 1 | Especifique o número de clusters |
|
| 2 | Inicialize os centróides do cluster |
|
| 3 | Atribua cada ponto de dados ao centróide mais próximo |
|
| 4 | Recalcule os centróides |
|
| 5 | Itere |
|
Escolha do número de clusters (valor de K)
A determinação do número ideal de clusters para a clusterização de dados pode exigir alguns testes e experimentos. Não existe uma resposta exata para qualquer conjunto de dados específico.
Orientações para determinação do número ideal de clusters:
- Conheça os dados Familiarize-se previamente com o conjunto de dados para ter uma ideia geral do perfil dos dados e de quaisquer concentrações de valores óbvias.
- Comece com valores altos Inicialmente, escolha um número relativamente alto de clusters, de 8 a 10.
- Experimente um número diferente de clusters Execute a clusterização várias vezes, especificando um valor de K diferente a cada vez. Uma análise dos resultados de saída pode ajudar a considerar se você precisa de mais ou menos clusters.
- Método do cotovelo Use o método do cotovelo para identificar programaticamente o número ideal de clusters. O número ideal é o ponto em que você alcança a melhor coerência de clusters e evita os retornos decrescentes de clusters adicionais que melhoram apenas marginalmente a coerência às custas da divisão de clusters já coerentes.
Você pode plotar os resultados do método do cotovelo em um gráfico de linhas para identificar o "cotovelo", ou o ponto de inflexão, em que o aumento do número de clusters não aprimora significativamente sua coerência.
Um script do método do cotovelo que você pode usar no Analytics está disponível para download no ScriptHub: Método do cotovelo - Soma de erros quadráticos (SSE) para K (login de cliente obrigatório).
Posso clusterizar com base em campos de caracteres ou datahora?
De forma geral, não é possível clusterizar por campos de caracteres ou datahora. O algoritmo de clusterização aceita apenas números e executa os cálculos com os números (distância euclidiana, média).
Dados de caracteres categóricos
Você pode ter dados de caracteres categóricos, como IDs de locais, no formato de números. Ou você pode usar um campo calculado para mapear categorias de caracteres a um conjunto de códigos numéricos que você criou. Esses dados podem ser convertidos para o tipo de dados numérico e usados para clusterização. No entanto, os clusters resultantes não seriam válidos, pois você estaria realizando cálculos matemáticos em números que representam algo não numérico.
Por exemplo, o cálculo de uma posição de centróide com base na média de uma lista de IDs de localização resulta em um número sem significado. O cálculo é baseado na suposição inválida de que a distância matemática entre dois números de localização equivale a alguma distância mensurável do mundo real.
Se considerarmos a distância física, não faz sentido afirmar que a distância entre as localizações 1 e 9 é o dobro da distância entre as localizações 1 e 5. As localizações 1 e 9 podem estar uma ao lado da outra e a localização 5 pode estar a quilômetros de distância.
Para uma análise de cluster envolvendo localização e distância física, os dados válidos que deveriam ser usados são coordenadas geográficas.
Dados categóricos que representam uma escala
Você pode clusterizar por dados categóricos que representam uma escala. Por exemplo, uma escala de avaliação de Ruim a Excelente, com códigos numéricos correspondentes de 1 a 5. Nesse caso, uma média dos códigos numéricos faz sentido.
Dados de datahora
Você pode usar funções do Analytics para converter dados datahora em dados numéricos. No entanto, os dados numéricos resultantes não são contínuos, o que é um problema para análises de cluster, que assumem conjuntos de números contínuos.
Por exemplo, os três números a seguir, como datas, têm todos um dia de diferença entre si. No entanto, como números, há uma lacuna, ou distância, considerável entre o primeiro e o segundo números.
- 20181130
- 20181201
- 20181202
Você pode usar valores de data serial nas análises de cluster. As datas seriais são um conjunto de inteiros contínuos que representam o número de dias decorridos desde 1º de janeiro de 1900.
Etapas
Nota
Se as opções do menu de aprendizado de máquina estiverem desativadas, é provável que o mecanismo do Python não esteja instalado. Para obter mais informações, consulte Instalar o ACL para Windows.
Especificar configurações para o algoritmo de clusterização
-
Abra a tabela com a dados que deseja clusterizar.
-
No menu principal do Analytics, selecione Aprendizado de máquina > Cluster.
-
Em Número de clusters (valor de K), especifique o número de clusters a usar para agrupar os dados.
-
Em Número máximo de iterações, especifique um limite superior para o número de iterações executadas pelo algoritmo de clusterização.
-
Em Número de inicializações, especifique quantas vezes um conjunto inicial de centróides aleatórios será gerado.
-
Opcional. Selecione Origem e insira um número.
Especificar um método de pré-processamento de dados
Se você clusterizar por mais de um campo-chave, deverá usar o recurso Pré-processamento para padronizar a escala dos campos antes de usá-los para clusterização.
A escala e as unidades dos diversos campos numéricos podem variar. Por exemplo, um campo de salário que contém dólares por ano pode variar entre 20.000 e 100.000 e um campo de idade em anos pode variar entre 18 e 70. Se você clusterizar usando os campos salário e idade, sem considerar a escala, os clusters de saída serão essencialmente clusters de salários, distorcidos pelo tamanho dos números de salário em comparação aos números de idade, em vez de clusters salário/idade.
O pré-processamento oferece os métodos explicados abaixo para considerar a escala de todos os valores em todos os campos-chave do cluster para que sejam ponderados igualmente durante o processo de clusterização.
| Opção de pré-processamento | Descrição |
|---|---|
| Padronizar |
Os valores de campos-chave são centrados na média de 0 (zero) e sua escala é ajustada, um processo que converte os valores para seu equivalente em pontuação z (pontuação padrão). A pontuação z é uma medida do número de desvios padrão que separam um valor bruto da média bruta de cada campo. No campo com escala ajustada, a média é representada por 0 (zero), e as pontuações z são positivas ou negativas, dependendo de os valores brutos que representam serem maiores ou menores que a média bruta do campo. Nota Use esta opção se os campos-chave tiverem principalmente valores diferentes de zero ("matrizes densas"). Exemplo do cálculo de uma pontuação zEm um campo de idade com escala ajustada, o valor bruto da idade de 55 é representado pela pontuação z de 1,038189.
|
| Variação da escala para a unidade |
A escala dos valores do campo-chave é ajustada dividindo-os pelo seu desvio padrão, mas eles não estão centrados na média de 0 (zero). Nota Use esta opção se um ou mais campos-chave contêm um grande número de valores 0 (zero) ("matrizes esparsas"). Exemplo de ajuste de escala sem centralizaçãoEm um campo de idade com escala ajustada, o valor bruto da idade de 55 é representado pelo valor com escala ajustada de 4,406077.
|
| Nenhum | Os valores dos campos-chave não são centrados e sua escala não é ajustada. A clusterização usa os valores brutos, sem centralização e ajuste de escala, para calcular os clusters. |
Selecionar campos
- Na lista Clusterizar por, selecione um ou mais campos-chave para usar na clusterização dos registros na tabela.
Os campos-chave devem ser numéricos.
- Opcional. Na lista Outros campos, selecione um ou mais campos adicionais a incluir na tabela de saída.
Dica
Você pode usar Shift+clique para selecionar vários cabeçalhos de colunas adjacentes e Ctrl+clique para selecionar vários cabeçalhos de colunas adjacentes.
Finalizar entradas de comando
-
Se existirem registros na exibição atual que você desejar excluir do processamento, insira uma condição na caixa de texto Se ou clique em Se para criar uma instrução IF usando o Construtor de expressões.
Nota
A condição Se é avaliada apenas em relação aos registros restantes em uma tabela depois da aplicação das opções de escopo (Primeiros, Próximos, Enquanto).
A instrução IF considera todos os registros na exibição e filtra aqueles que não atendem à condição especificada.
- Na caixa de texto Para, especifique o nome da tabela de saída.
Nota
Os nomes de tabela do Analytics são limitados a 64 caracteres alfanuméricos, sem contar a extensão .FIL. O nome pode incluir o caractere de sublinhado ( _ ) mas nenhum outro caractere especial e nenhum espaço. O nome não pode começar com um número.
- Opcional. Na guia Mais:
- Para especificar o processamento de apenas um subconjunto de registros, selecione uma das opções no painel Escopo.
- Selecione Usar tabela de saída se você quiser que a tabela de saída seja aberta automaticamente.
- Clique em OK.