如何对模糊重复分组
处理数据时,模糊重复操作将在测试域中按顺序向下移动。该操作会将域中的第一个值与每个后续值对比,然后对比域中的第二个值与每个后续值,依此类推,在域中循环直到所有值均与其每个后续值进行了比较。它不会将值与前面的值进行比较。
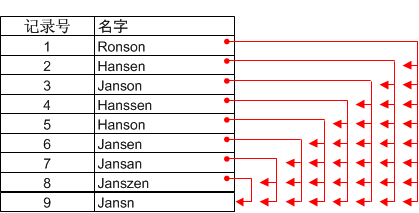
每次对比时,该操作会根据您指定的差异设置确定两个比较的值是否属于模糊重复。(要了解差异设置的信息,请参考 差异设置工作原理。)如果两个值是模糊重复,会被一起放到一个组中。禁止多余的匹配(本主题后面进行说明)。模糊重复操作的结果可能包含多个组。
组所有者和组成员
组中的第一个模糊重复为控制值或组“所有者”,其唯一的事实依据就是该值在测试的域中属于第一个出现的组成员。如果测试域包含相同数据但排序不同,则会生成不同的组所有者以及不同构成的组。
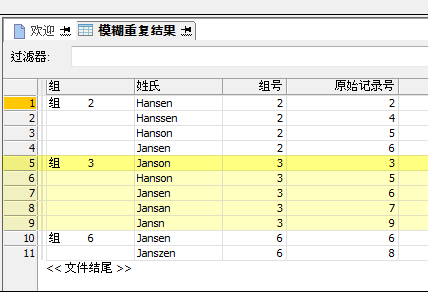
组使用组所有者的记录编号进行标识。下面的示例显示了测试 Last Name 域的结果。“Janson”构成一个组(基于差异设置),而“Janson”为原表中的记录编号 3,所以该组成为组 3。
组所有者未必是正确值
组所有者不一定是“正确”或标准值。在组构成过程中,只是基于所指定的差异程度简单地衡量或计算值。所有组成员均位于组所有者的指定差异程度范围内。成员可能位于其他成员的指定差异程度范围内,也可能没有在该范围内。
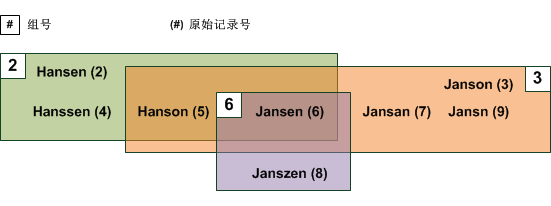
下图提供上述输出表中结果的可视化表示形式。差异阈值为 1,表示组成员与组所有者的最大差异为一个 (1) 字符。请注意,有些模糊重复可能出现在多个组中。
详尽与非详尽的结果
为了防止结果大小变得不可控,模糊重复功能被设计为生成非详尽的组。非详尽表示各个模糊重复组可能不包含测试域中组所有者指定差异程度范围内的所有模糊重复。不过,如果组所有者是测试域中其他值的模糊重复,则两个值在结果中将同时出现在组的某个位置,但并不一定是在与组所有者相关联的组中。因此,组可能是非详尽的,但结果总的来说是详尽的。
如果为测试域中的特定值生成单个详尽的模糊重复列表对于您的分析很重要,您可以使用 ISFUZZYDUP( ) 函数来实现此目的。有关详细信息,请参阅模糊重复帮助功能。
组构成详细信息
模糊重复功能通过从组中排除值(如果它们已在以前的组中随组所有者出现)来创建非详尽的组。这种构成组的方法可降低多余模糊重复对的数量,并且有助于控制结果的总体大小。
下面介绍了有关组构成的规则,并提供了相关示例。
| 规则 | 解释 |
|---|---|
| 所有者-成员关系为非双向的 |
由于模糊重复操作时在测试域中向下移动,所以组所有者仅与域中出现在其值下方的模糊重复相互关联,而不会与其上方显示的模糊重复相关联。 大多情况下,组所有者是其上方所显示的一个或多个组的成员。不过,反之并不正确。上方的组所有者不是后续组的成员。在值成为组所有者后,则不会再出现在后续组中。 在上述示例中,组 6 所有者“Jansen”是之前两个组的成员,但这些组的所有者(“Hansen”和“Janson”)即使是“Jansen”的模糊重复值,也不是组 6 的成员。 |
| 如果两个值是之前组的成员,则如果其中一个值是后续组的所有者,则它们不会被一起放在一个后续组中 |
在上述示例中,“Jansen”、“Jansan”和“Jansn”均是组 3 的所有成员。当“Jansen”成为组 6 所有者时,“Jansan”和“Jansn”不会放在该组中,即使它们都是测试域中“Jansen”下面出现的模糊重复。 |
| 如果两个值是之前组的成员,则如果其中任一值都不是后续组的所有者,便可能一起出现在一个后续组中 |
在上述示例中,“Hanson”和“Jansen”一起出现在组 2 和组 3 中。这种情况下,可以同时出现在多个组中,因为差异程度基于各自的组所有者(而不是彼此)进行衡量。 |
说明
有时,第二条和第三条规则可能存在例外。执行时,模糊重复操作会存储临时值。如果已填充分配给这些临时值的空间,结果可能是一些组所有者及一个或多个多余的组成员。(组所有者和组成员已经一起出现在前一个组中。)模糊重复组指定的最大大小越小,这种冗余越有可能发生。
模糊重复数据处理和组构成
下表显示了上述示例的逐个记录处理。按降序处理数据。为减少数据冗余,如果值与组所有者一起出现在之前的组中,则会将其从组中排除。
(差异设置:差异阈值 = 1,差异比例 = 99)
| 记录编号 | 姓氏 | 找到的模糊重复项 | 输出结果 |
|---|---|---|---|
|
1 |
Ronson |
|
|
|
2 |
Hansen |
Hanssen、Hanson、Jansen |
组 2 组所有者:Hansen 组成员:Hanssen、Hanson、Jansen |
|
3 |
Janson |
Hanson、Jansen、Jansan、Jansn |
组 3 组所有者:Janson 组成员:Hanson、Jansen、Jansan、Jansn |
|
4 |
Hanssen |
|
|
|
5 |
Hanson |
|
|
|
6 |
Jansen |
Jansan, Janszen, Jansn |
组 6 组所有者:Jansen 组成员:Janszen |
|
7 |
Jansan |
Jansn |
|
|
8 |
Janszen |
|
|
|
9 |
Jansn |
|
|
在结果中包含完全匹配重复
处理数据时,模糊重复操作始终包括完全匹配重复,但会将它们从结果中过滤掉,除非您在模糊重复对话框中选择了包括完全匹配重复。
完全重复遵守与模糊重复相同的组构成规则。如果它们已随组所有者一起出现在之前的组中,则会被从该组中排除。如果组所有者和排除的值属于完全匹配重复,则看起来排除的值应位于所有者的组中。不过,排除符合组构成规则,因为两个值已同时出现在之前的组中。
下表显示了完全重复的处理。按降序处理数据。
- “Ronson (3)”不会与 “Ronson (4)”形成组,因为两个值已经在组 1 中。
- “Jansen (9)”被排除在 “Jansen (8)”形成的组之外,因为两个值已经一起在组 2 和组 5 中。
(差异设置:差异阈值 = 1,差异比例 = 99,包括完全重复 = Y)
| 记录编号 | 姓氏 | 找到模糊重复和完全匹配重复 | 输出结果 |
|---|---|---|---|
|
1 |
Ronson |
Ronson (3)、Ronson (4) |
组 1 组所有者:Ronson 组成员:Ronson (3)、Ronson (4) |
|
2 |
Hansen |
Hanssen、Hanson、Jansen (8)、Jansen (9) |
组 2 组所有者:Hansen 组成员:Hanssen、Hanson、Jansen (8)、Jansen (9) |
|
3 |
Ronson |
Ronson (4) |
|
|
4 |
Ronson |
|
|
|
5 |
Janson |
Hanson、Jansen (8)、Jansen (9)、Jansan、Jansn |
组 5 组所有者:Janson 组成员:Hanson、Jansen (8)、Jansen (9)、Jansan、Jansn |
|
6 |
Hanssen |
|
|
|
7 |
Hanson |
|
|
|
8 |
Jansen |
Jansen (9)、Jansan、Janszen、Jansn |
组 8 组所有者:Jansen 组成员:Janszen |
|
9 |
Jansen |
Jansan, Janszen, Jansn |
组 9 组所有者:Jansen 组成员:Janszen |
|
10 |
Jansan |
Jansn |
|
|
11 |
Janszen |
|
|
|
12 |
Jansn |
|
|