Fuzzy join
An Analytics fuzzy join use fuzzy matching of key field values to combine two Analytics tables into a new third table. In most respects, a fuzzy join is like a regular Analytics join (see Joining tables). The main difference is that in addition to joining records based on exact matching of key field values, a fuzzy join can join records based on approximate matching.
Fuzzy joining is useful when primary and secondary keys contain the same kind of data, but in slightly different form. Or the data in the keys has slight irregularities, such as typos, that might prevent an exact match.
Example
Scenario
You want to identify any vendors who are also employees as one way of analyzing data for possible improper payments.
Approach
You join the Vendor master table with the Employee table, using the address field in each table as a common key (Vendor_Street, and Emp_Address). However, the form of the address data in the key fields varies slightly, so you use a fuzzy join instead of a regular join.
A look at some of the data
Without significant data cleansing and harmonization work, the primary and secondary key values shown below would not be joined by a regular Analytics join, even though they are very likely matching addresses.
| Primary key values | Secondary key values |
|---|---|
| 605 3rd Avenue | 605 Third Avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
Even with data cleansing and harmonization, key values with minor differences in spelling, such as "Rowan" and "Rowen", would probably not be matched.
The key values could be joined by a fuzzy join, depending on the fuzzy join settings.
Output results
In the example of the joined table below, exact key field matches are highlighted purple, and fuzzy key field matches are highlighted green.
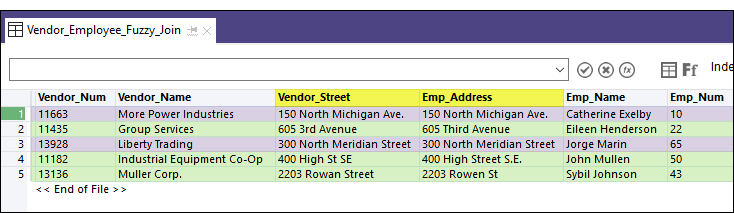
Fuzzy join versus fuzzy duplicates
A fuzzy join analyzes values in key fields in two tables. To test a single field in a single Analytics table for nearly identical values, see Fuzzy duplicates overview.
Output table size and command performance
Output table size
The fuzzy join is similar to the Analytics many-to-many join. All primary key values can potentially be matched to all secondary key values. The size of the output table can be many times greater than the size of either the primary or the secondary input tables.
Command performance
The fuzzy matching algorithms ensure that only key values within a specified degree of fuzziness, or exactly matching values, are actually joined. However, every possible primary-secondary match must be tested, which means that the fuzzy joining process can be time-consuming. The number of individual tests that must be performed is equal to the number of records in the primary table times the number of records in the secondary table.
Best practices
Keep output table size and command performance in mind when you prepare primary and secondary input tables, and specify the degree of fuzziness.
- Tailor the data Ensure that only relevant records are included in the primary and secondary tables. If some records have no chance of being matched, filter them out before performing fuzzy matching.
- Test runs For large data sets, do test runs on a small portion of the data as a more efficient way of arriving at suitable settings for the fuzzy matching algorithms. Start with more conservative fuzzy settings, and if required, progressively loosen them.
Fuzzy matching algorithms
When you perform a fuzzy join, you choose between two different fuzzy matching algorithms:
- Dice coefficient
- Levenshtein distance
The algorithms operate completely independently of each other, and can produce somewhat different results. One approach is to perform a fuzzy join twice, once with each algorithm, and compare results. Typically, a number of the fuzzy matches in each result set overlap, but some matches can be unique to each result set.
Degree of fuzziness
You specify the degree of fuzziness for each algorithm, which can dramatically change the size and makeup of the result set. "Degree of fuzziness" refers to how closely two values match.
Depending on the algorithm you select, you use the following settings to control the degree of fuzziness:
| Algorithm | Setting |
|---|---|
|
Dice coefficient |
|
|
Levenshtein distance |
|
Try experimenting with different degrees of fuzziness. Begin conservatively and produce smaller result sets, and then progressively loosen the settings until you start getting too many joined values that are obviously not matches (false positives).
Dice coefficient
The Dice coefficient algorithm works by measuring the degree of similarity between a primary and a secondary key value, on a scale from 0.0000 to 1.0000. The greater the Dice's coefficient of the two values, the more similar they are.
| Dice's coefficient | Meaning |
|---|---|
| 1.0000 |
Each value is composed of an identical set of characters, although the characters may be in a different order, and may use different case. The n-grams in the two values are 100% identical. N-grams are explained below. |
| 0.7500 |
The n-grams in the two values are 75% identical. |
| 0.0000 | The two values have no identical n-grams, or the length specified in the N-gram setting is longer than the shorter of the two values being compared. |
N-grams
Dice's coefficient is calculated by first dividing the values being compared into n-grams. N-grams are overlapping blocks of characters, with a length of n, which is whatever length you specify in the N-gram setting.
Here are two of the values from the example above, divided into n-grams with a length of 2 characters (n = 2).
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
|---|---|
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
The Dice's coefficient is the percentage of n-grams in the two values that are identical. In this case, 20 of 28 n-grams are identical, which is 71.43%, or 0.7143 expressed as a decimal fraction.
Note
Increasing the length in the N-gram setting makes the criterion for similarity between two values stricter.
Percent
When you specify a Percent setting, you are specifying the minimum allowable Dice's coefficient of two values for them to qualify as a fuzzy match. For example, if you specify 0.7500 , at least 75% of the n-grams in two values must be identical to create a match.
| Percent setting | Meaning | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0.7500 |
To qualify as a fuzzy match, at least 75% of the n-grams in two values must be identical. |
Not matched, not included in the joined table (Dice's coefficient = 0.7143) |
| 0.7000 |
To qualify as a fuzzy match, at least 70% of the n-grams in two values must be identical. |
Matched, included in the joined table (Dice's coefficient = 0.7143) |
For detailed information about how Dice's coefficient works, see DICECOEFFICIENT( ) function.
Levenshtein distance
The Levenshtein distance algorithm works by measuring the degree of difference between a primary and a secondary key value, on a whole number scale starting at 0. The scale represents the number of single-character edits required to make one value identical to the other value. The greater the Levenshtein distance between the two values, the more different they are.
| Levenshtein distance | Meaning |
|---|---|
| 0 | Each value is composed of an identical set of characters, in an identical order. Case may differ. |
| 2 |
Two single-character edits are required to make the two values identical. For example: "Smith" and "Smythe"
|
| 3 |
Three single-character edits are required to make the two values identical. For example: "Hanssen" and "Jansn"
|
Distance
When you specify a Distance setting, you are specifying the maximum allowable Levenshtein distance between two values for them to qualify as a fuzzy match. For example, if you specify 2 , no more than two edits can be required to make two values identical.
| Distance setting | Meaning | Hanssen / Jansn |
|---|---|---|
| 2 |
To qualify as a fuzzy match, no more than 2 character edits can be required to make two values identical. |
Not matched, not included in the joined table (Levenshtein distance = 3) |
| 3 |
To qualify as a fuzzy match, no more than 3 character edits can be required to make two values identical. |
Matched, included in the joined table (Levenshtein distance = 3) |
For detailed information about how Levenshtein distance works, see LEVDIST( ) function. Unlike the function, the Levenshtein distance algorithm used in the fuzzy join automatically trims leading and trailing blanks, and is not case-sensitive.
Getting better results
Using Analytics functions to perform data cleansing and harmonization of the primary and secondary key fields can improve the effectiveness of the fuzzy join. For example, if you harmonize values such as "Street", "St.", and "St", or remove them altogether, you can use tighter fuzzy settings and still get the same fuzzy matches, while reducing the number of false positive matches.
Removing generic elements
You can use the OMIT( ) and EXCLUDE( ) functions to remove generic elements such as "Corporation" or "Inc.", or characters such as commas, periods, and ampersands (&), from field values.
Removal of generic elements and punctuation focuses the fuzzy join comparison of key field values on just the portion of the values where a meaningful difference may occur.
Steps
You can use fuzzy matching of key field values to combine two Analytics tables into a new third table.
- In the Navigator, open the primary table, and right-click the secondary table
and select Open as Secondary.
The primary and secondary table icons update with the numbers 1 and 2 to indicate their relation to each other

 .
. - Select Data > Fuzzy Join.
- On the Main tab select the fuzzy matching algorithm you want to use:
- Dice coefficient
- Levenshtein
- Depending on the algorithm you selected, provide settings to control the degree of fuzziness.
Dice coefficient
- N-gram
- Percent
Levenshtein
- Distance
The settings are explained below.
- Select the primary key field from the Primary
Keys list.
You can select only one primary key field, and it must be a character field.
- Select the secondary key field from the Secondary
Keys list.
You can select only one secondary key field, and it must be a character field.
- Select the fields to include in the joined
table from the Primary
Fields and Secondary Fields lists.
Note
You must explicitly select the primary and secondary key fields if you want to include them in the joined table.
Tip
You can Ctrl+click to select multiple non-adjacent fields, and Shift+click to select multiple adjacent fields.
- In the To text box, specify the name of the new, joined table.
- (Optional) On the More tab:
- If you want to process only a subset of records, select one of the options in the Scope panel.
- If you want to append (add) the output results to the end of an existing Analytics table, select Append To Existing File.
- Click OK.
The new, joined table is output.
Fuzzy Join dialog box options
The tables below provide detailed information about the options in the Fuzzy Join dialog box.
Main tab
| Options – Fuzzy Join dialog box | Description |
|---|---|
| Dice coefficient |
Use Dice's coefficient for fuzzy matching between primary and secondary key values.
|
| Levenshtein |
Use Levenshtein distance for fuzzy matching between primary and secondary key values.
|
| Secondary Table | An alternate method for selecting the secondary table. |
| Primary
Keys Secondary Keys |
Specifies the common key field to use to join the two tables.
Key field guidelines:
|
| Primary
Fields Secondary Fields |
Specifies the fields to include in the joined
table.
|
| Use Output Table | Specifies whether the Analytics table containing the output results opens automatically upon completion of the operation. |
| If |
(Optional) Allows you to create a condition to exclude records from processing.
|
| To | Specifies the name and location of the output table.
Regardless of where you save the output table, it is added to the open project if it is not already in the project. If Analytics prefills a table name, you can accept the prefilled name, or change it. |
More tab
| Options – Fuzzy Join dialog box | Description |
|---|---|
| Scope panel | Specifies which records in the primary table are processed:
Note The number of records specified in the First or Next options references either the physical or the indexed order of records in a table, and disregards any filtering or quick sorting applied to the view. However, results of analytical operations respect any filtering. If a view is quick sorted, Next behaves like First. |
| Append To Existing File | Specifies that the output results are appended (added) to the end of
an existing Analytics table. Note Leaving Append To Existing File deselected is recommended if you are uncertain whether the output results and the existing table have an identical data structure. For more information about appending and data structure, see Appending results to Analytics tables and text files. |
| OK | Executes the operation.
|