曖昧結合
Analytics 曖昧結合は、キー フィールドと値の曖昧一致を使用して、2 つの Analytics テーブルを新しい 3 番目のテーブルに結合します。ほとんどの点において、曖昧結合は標準の Analytics 結合に似ています(テーブルの結合を参照)。主な違いは、曖昧結合は、キー フィールド値の完全一致に基づくレコードの結合のほかに、近似一致に基づくレコードの結合ができることです。
曖昧結合は、主キーおよび副キーに同じ種類のデータが少し異なる形式で含まれているときに役立ちます。あるいは、キーのデータに、完全一致を妨げる可能性がある誤字などの少しの不規則性があります。
例
シナリオ
考えられる不適切な報酬のデータを分析する方法の 1 つとして、従業員でもある業者を特定する必要があります。
アプローチ
ベンダー マスター テーブルと従業員テーブルが、共通キーとして各テーブルの住所フィールド(Vendor_Street、および Emp_Address)を使用して結合されます。ただし、キー フィールドの住所データの形式は少し異なります。このため、標準の結合ではなく、曖昧結合を使用します。
データの一部の概要
重要なデータ クレンジングと調整作業がないと、以下に示す主キーおよび副キー値は、非常に一致の確率が高い住所であっても、標準の Analytics 結合では結合されません。
| 主キー値 | 副キー値 |
|---|---|
| 605 3rd Avenue | 605 Third Avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
データ クレンジングと調整を行ったとしても、"Rowan" や "Rowen" といった綴りにわずかな違いがあるキー値はおそらく一致しません。
キー値は、曖昧結合設定に応じて、曖昧結合で結合できます。
出力結果
以下の結合されたテーブルの例では、正確なキー フィールド一致は紫でハイライトされています。曖昧キー フィールド一致は緑でハイライトされています。
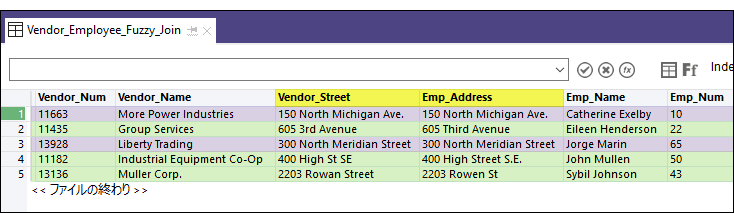
曖昧結合と曖昧重複
曖昧結合は 2 つのテーブルのキー フィールドの値を分析します。ほぼ同一の値の単一の Analytics テーブルの単一のフィールドをテストするには、あいまい重複の概要を参照してください。
出力テーブル サイズとコマンド パフォーマンス
出力テーブル サイズ
曖昧結合は、Analytics 多対多結合と似ています。すべての主キー値は、すべての副キー値と一致する可能性があります。出力テーブルのサイズは、主または副入力テーブルのサイズの数倍の大きさになることがあります。
コマンド パフォーマンス
曖昧一致アルゴリズムは、指定された度合いの曖昧さのキー値または完全に一致する値のみが実際に結合されることを保証します。ただし、すべての考えられる主と副の一致はテストされる必要があります。つまり、曖昧結合処理は時間がかかることがあります。実行する必要がある個別のテスト数は、主テーブルのレコード数を副テーブルのレコード数で乗算した値です。
ベスト プラクティス
主および副入力テーブルを準備し、曖昧さの度合いを指定するときには、出力テーブル サイズとコマンド パフォーマンスに注意してください。
- データのカスタマイズ 関連するレコードのみが主および副テーブルに含まれることを保証します。一部のレコードに一致の可能性がない場合は、曖昧一致を実行する前に、除外します。
- テスト実行 大きいデータ セットの場合は、データの一部のみでテストを実行します。これは、曖昧一致アルゴリズムの適切な設定を得るためのより効率的な方法です。保守的な曖昧設定から開始し、必要に応じて、徐々に緩めて行きます。
曖昧一致アルゴリズム
曖昧結合を実行するときには、2 つの異なる曖昧一致アルゴリズムから選択します。
- ダイス係数
- レーベンシュタイン距離
このアルゴリズムは、相互に完全に独立しているため、異なる結果を生成することができます。1 つのアプローチは、曖昧結合を 2 回(各アルゴリズムで 1 回ずつ)実行し、結果を比較することです。一般的に、各結果セットの多数の曖昧一致は重複しますが、一部の一致は各結果セットに対して一意であることがあります。
曖昧度
各アルゴリズムの曖昧さの度合いを指定します。これにより、結果セットのサイズと構成を動的に変更することができます。「曖昧度」とは、2 つの値がどれほど近く一致しているのかを差します。
選択するアルゴリズムに応じて、次の設定を使用して、曖昧度を制御します。
| アルゴリズム | 設定 |
|---|---|
|
ダイス係数 |
|
|
レーベンシュタイン距離 |
|
異なる曖昧さの度合いで実験する保守的に開始し、小さい結果セットを生成します。次に、明らかに一致ではない(誤検出)結合された値が多くなりすぎるまで、徐々に設定を緩めます。
ダイス係数
ダイス係数アルゴリズムは、0.0000 ~ 1.0000 の尺度で、主キー値と副キー値の間の類似性の度合いを測定することで動作します。2 つの値のダイス係数が大きいほど、類似性が高くなります。
| ダイス係数 | 意味 |
|---|---|
| 1.0000 |
各文字列は同じ文字から構成されています。ただし、文字の順序と大文字小文字の表記は異なる場合があります。 2 つの値の n-gram は 100% 同一です。 N-gram は以下で説明します。 |
| 0.7500 |
2 つの値の n-gram は 75% 同一です。 |
| 0.0000 | 2 つの値には同一の n-gram がないか、N-gram 設定で指定された長さが比較対象の 2 つの値の短い方よりも長くなっています。 |
N-gram
まず、ダイス係数は比較対象の 2 つの値を n-gram 文字ずつに分割して計算されます。N-gram は文字の重複するブロックです。n の長さは、N-gram 設定で指定する長さです。
ここには、上記の例の 2 つの値があります。長さが 2 文字の n-gram に分割されています(n = 2)。
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
|---|---|
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
ダイス係数は、同一の 2 つの値の n-gram の割合を表します。この場合、28 n-gram 中 20 が同一であり、71.43% です。0.7143 は小数として表されます。
メモ
N-gram 設定の長さを大きくすると、2 つの値の類似度の基準が厳しくなります。
パーセント
パーセント設定を指定するときには、曖昧一致となるための、2 つの値の許容可能な最低ダイス係数を指定しています。たとえば、0.7500 を指定すると、一致を作成するためには、2 つの値の少なくとも 75% の n-gram が同一である必要があります。
| パーセント設定 | 意味 | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0.7500 |
曖昧一致となるためには、2 つの値の少なくとも 75% の n-gram が同一である必要があります。 |
一致しません。結合されたテーブルに含まれません (ダイス係数 = 0.7143) |
| 0.7000 |
曖昧一致となるためには、2 つの値の少なくとも 70% の n-gram が同一である必要があります。 |
一致します。結合されたテーブルに含まれます (ダイス係数 = 0.7143) |
ダイス係数の仕組みの詳細については、DICECOEFFICIENT( ) 関数を参照してください。
レーベンシュタイン距離
レーベンシュタイン距離アルゴリズムは、0 から開始する整数の尺度で、主キー値と副キー値の間の差異を測定して機能します。この尺度は、ある値を他の値と同一にするために必要な、1 文字の編集の回数を表します。2 つの値間のレーベンシュタイン距離がより大きければ、相違も大きくなります。
| レーベンシュタイン距離 | 意味 |
|---|---|
| 0 | 各値は、同一の順序の、同一の文字セットから構成されます。大文字と小文字は異なる場合があります。 |
| 2 |
2 つの値を同一にするには、2 つの単一の文字の編集が必要です。 例:"Smith" と "Smythe"
|
| 3 |
2 つの値を同一にするには、3 つの単一の文字の編集が必要です。 例: "Hanssen" と "Jansn"
|
距離
距離設定を指定するときには、曖昧一致となるための、2 つの値間の許容可能な最大レーベンシュタイン距離を指定しています。たとえば、2 を指定する場合、2 つの値を同一にするために、2 回以下の編集が必要です。
| 距離設定 | 意味 | Hanssen / Jansn |
|---|---|---|
| 2 |
曖昧一致となるためには、2 つの値を同一にするために、2 回以下の編集が必要です。 |
一致しません。結合されたテーブルに含まれません (レーベンシュタイン距離 = 3) |
| 3 |
曖昧一致となるためには、2 つの値を同一にするために、3 回以下の編集が必要です。 |
一致します。結合されたテーブルに含まれます (レーベンシュタイン距離 = 3) |
レーベンシュタイン距離の仕組みの詳細については、LEVDIST( ) 関数を参照してください。関数とは異なり曖昧結合で使用されるレーベンシュタイン距離アルゴリズムは、自動的に先頭と末尾の空白を取り除きます。大文字と小文字は区別されません。
結果の精度を高める
Analytics 関数を使用して、主キー フィールドと副キー フィールドのデータ クレンジングと調整を実行すると、曖昧結合の効果が上がります。たとえば、"Street"、"St."、"St" などの値を調整するか、まとめて削除する場合は、より厳しい曖昧設定を使用すい、同じ曖昧一致を得ながら、誤検出の一致数を減らすことができます。
一般的要素の除去
OMIT( ) と EXCLUDE( ) 関数を使用すると、フィールド値から "Corporation" や "Inc."、カンマ、ピリオド、アンパサンド(&)文字などの一般的要素を除去することができます。
一般的要素と句読点の除去により、キー フィールド値の曖昧結合の値比較は、意味のある違いが発生する可能性のある文字列の部分だけに集中されます。
手順
曖昧結合を使用すると、キー フィールドと値の曖昧一致を使用して、2 つの Analytics テーブルを新しい 3 番目のテーブルに結合できます。
- ナビゲーターで、主テーブルを開き、(ナビゲーターで)副テーブルを右クリックして[副テーブルとして開く]を選択します。
主および副テーブル アイコンが数字 1 ~ 2 で更新され、相互への関連を示します
 。
。
- [データ > 曖昧結合]の順にクリックします。
- [メイン]タブで、使用する曖昧一致アルゴリズムを選択します。
- ダイス係数
- レーベンシュタイン
- 選択するアルゴリズムに応じて、設定を使用して、曖昧度を制御します。
ダイス係数
- N-gram
- 割合
レーベンシュタイン
- 距離
設定は以下で説明します。
- [主キー]リストから主キー フィールドを選択します。
1 つの主キー フィールドのみを選択できます。これは、文字フィールドである必要があります。
- [副キー]リストから副キー フィールドを選択します。
1 つの副キー フィールドのみを選択できます。これは、文字フィールドである必要があります。
- [主フィールド]および[副フィールド]リストから、結合テーブルに含めたいフィールドを選択します。
メモ
結合テーブルに含める場合は、主キーおよび副キー フィールドを明示的に選択する必要があります。
ヒント
隣接する複数のフィールドを選択するには、Shift キー + クリックを、隣接していない複数のフィールドを選択するには、Ctrl キー + クリックを利用できます。
- [保存先]テキスト ボックスに、新しい結合された ACL テーブルの名前を指定します。
- (省略可能)[詳細]タブ:
- レコードのサブセットのみが処理されることを指定する場合は、[範囲]パネルでオプションのいずれかを選択します。
- 出力結果を既存の Analytics テーブルの末尾に追加する場合は、[既存のファイルに追加する]を選択します。
- [OK]をクリックします。
新しい結合されたテーブルが出力です。
[曖昧結合]ダイアログ ボックス オプション
次の表は、[曖昧結合]ダイアログ ボックスのオプションの詳細を示します。
[メイン]タブ
| オプション – [曖昧結合]ダイアログ ボックス | 説明 |
|---|---|
| ダイス係数 |
主キー値と副キー値の間の曖昧一致には、ダイス係数を使用します。
|
| レーベンシュタイン |
主キー値と副キー値の間の曖昧一致には、レーベンシュタイン距離を使用します。
|
| 副テーブル | 副テーブルを選択する代替方法。 |
| 主キー 副キー |
2 つのテーブルを結合するために使用する共通キー フィールドを指定します。
キー フィールドのガイドライン:
|
| 主フィールド 副フィールド |
結合テーブルに含めるフィールドを指定します。
|
| 出力テーブルを開く | 操作の完了時に、出力結果を含んでいる Analytics テーブルを自動的に開くかどうかを指定します。 |
| もし次の |
(省略可能)レコードを処理から除外する条件を作成できます
|
| 変換先 | 出力テーブルの名前と場所を指定します。
保存する出力テーブルの場所に関係なく、そのテーブルが開いているプロジェクトにまだ存在しないときは、プロジェクトに追加されます。 Analytics によってテーブル名があらかじめ設定されている場合は、その設定されている名前を受け入れることも、あるいは変更することもできます。 |
[詳細]タブ
| オプション – [曖昧結合]ダイアログ ボックス | 説明 |
|---|---|
| 範囲パネル | 処理される主テーブルのレコードを指定します。
メモ "先頭" または "次" オプションで指定されたレコード数は、テーブル内の物理的な順番またはインデックス順のレコードを参照するもので、ビューに適用されたフィルターやクイック ソートは一切無視します。ただし、分析操作の結果ではすべてのフィルターを考慮します。 ビューでクイック ソートが実行されている場合、"次" は "先頭" のように動作します。 |
| 既存のファイルに追加する | 出力結果が既存の Analytics テーブルの最後に追加されることを指定します。 メモ 出力結果と既存のテーブルの構造が同一であるかどうかが不確かな場合は、[既存のファイルに追加する]を選択解除されたままにしておくことをお勧めします。 追加およびデータ構造の詳細については、Analytics テーブルおよびテキスト ファイルへの結果の追加を参照してください。 |
| OK | 処理を実行します。
|