従来の変数サンプリング
従来の変数サンプリングは、以下を推定するための統計的サンプリング方法です。
- 取引の勘定またはクラスの合計監査済み金額
- 取引の勘定またはクラスの金額虚偽表示の合計金額
従来の変数サンプリングは、次の特性がある財務データで最も効果的に機能します。
|
通常量~大量の虚偽表示 たとえば、5% 以上の数の項目が虚偽表示である場合など。 |
| 過剰計上または過少計上が存在する。 |
| 0 ドルの科目が存在する。 |
ヒント
Analytics における従来の変数サンプリングのエンドツーエンド プロセスに関するクイック スタート ガイドについては、従来の変数サンプリングのチュートリアルを参照してください。
メモ
従来の変数サンプリングは、財務データに使用できるだけでなく、数量や時間単位などの測定単位をはじめとする、可変特性を持つ任意の数値データに対して使用することができます。
機能の仕組み
従来の変数サンプリングでは、アカウンのレコードの小さいサブセットを選択して分析できます。 サブセットの分析結果に基づいて、アカウントの合計監査金額と、虚偽表示の合計金額を推定できます。
2 つの推定金額は範囲として計算されます。
- 点推定値は範囲の中点です。
- 上限と下限は、範囲に含まれる 2 つの端点です。
点推定値と上限だけまたは下限だけを使って、片側推定または範囲を計算することもできます。
推定された範囲を、勘定の簿価、または重大と判断される虚偽表示金額と比較し、勘定に関する決定を行います。
従来の変数サンプリングでは、次のような表示がサポートされます。
- 勘定の真の監査金額が、勘定簿価 46,400,198.71 が含まれる 45,577,123.95 ~ 46,929,384.17 の間となる確率が 95% あります。 このため、勘定の金額表示は公正であると見なされます。
- 勘定残高の虚偽表示額が– 813,074.76 ~ 539,185.46 となる確率が 95% あります。これは金額精度 ±928,003.97 の範囲を逸脱していません。 このため、勘定の金額表示は公正であると見なされます。
従来の変数サンプリング処理の概要
注意
有効なサンプル サイズの計算をスキップしないでください。
すぐにレコードのサンプルを抽出し、サンプル サイズで推定する場合は、分析結果の推定が無効になる確率が高く、最終結果に欠陥が生じます。
従来の変数サンプリング処理には、以下のステージがあります。
- 従来の変数サンプリングの準備(計画)
- レコードのサンプルを描画する
- サンプリングされたデータで意図した監査手順を実行します。
- 以下を評価します。
- 全体として勘定に対して推定されるときに、サンプリングされたデータの監査済み金額が記録された簿価の許容可能な範囲内に入るかどうか
- サンプリングされたデータの金額虚偽表示の観察されたレベルが全体として勘定で虚偽表示の許容可能な金額を表すかどうか
各値は保持され、次の段階に移動すると入力されます。
Analytics での従来の変数サンプリングには、3 つの異なるダイアログ ボックスに情報を入力し、関連するコマンドを次の順に実行します。
- [CVS 準備]ダイアログ ボックス
- [CVS サンプル]ダイアログ ボックス
- [CVS 評価]ダイアログ ボックス
この処理を進める過程で、1 つのダイアログ ボックスに入力した情報が次のダイアログ ボックスに自動的にあらかじめ入力されます。 値があらかじめ入力されることで、手間が省かれるとともに、誤って不適切な値を入力してサンプルが無効とされるリスクを防ぐことができます。
なお、[CVS サンプル]および[CVS 評価]ダイアログ ボックスに自動的に入力された値は、一時的に保存されるだけであり、Analytics プロジェクトを閉じれば削除されます。
従来の変数サンプリングの値の再生成
実稼働環境では、タイミングが異なれば、従来の変数サンプリングのプロセスの異なる段階を実行するのが一般的です。 Analytics をクローズしたときに失われた従来の変数サンプリングの値を再生成するには、次のいずれかの方法を使用できます。
最初の方法は最も簡単です。
- あらかじめ入力されたコマンドを保存
CVS 準備段階と CVS サンプル段階の結果には、従来の変数サンプリングのプロセス内の後続のコマンドが含まれます。これらのコマンドには、必要な値があらかじめ入力されています。 あらかじめ入力されたこれらのコマンドを、後で使用できるように、独立したスクリプトに保存します。
詳細については、従来の変数サンプリングのチュートリアルを参照してください。
- 実行したコマンドをスクリプトに保存
fCVS 準備段階と CVS サンプル段階を実行した後で、Analytics の表示領域に表示されている CVSPREPARE および CVSSAMPLE コマンドをコピーし、独立したスクリプトに保存します。 このようなスクリプトを後で実行することで、従来の変数サンプリングの値を再生成することができます。
この方法の欠点は、レコードの冗長なサンプルが抽出されることです。
- 実行したコマンドをログから取得
ログに記録されている CVSPREPARE および CVSSAMPLE コマンドをコピーし、これらのコマンドをコマンド ラインで再実行して、従来の変数サンプリングの値を再生成します。
この方法の欠点は、ログ内のコマンドの正しいインスタンスを見つけるのが困難な場合があることであり、その場合はレコードの冗長なサンプルが抽出されます。
あらかじめ入力された値の変更
従来の変数サンプリングのあらかじめ入力された値は通常、変更しないでください。 あらかじめ入力された値を変更すると、サンプリング プロセスの統計の有効性が否定される可能性があります。
注意
あらかじめ入力された値を更新するのは、変更の影響を理解するための統計に関する知識がある場合に限ります。
数値の長さ制限
従来の変数サンプリングの準備段階では、いくつかの内部計算が行われます。 これらの計算では、最大 17 桁の数値がサポートされます。 計算結果が 17 桁を超える場合には、その計算結果が出力に含まれなくなるため、サンプリング処理を続行できなくなります。
注意:17 桁未満のソース データの数値から、17 桁を超える内部計算結果が生成される場合もあります。
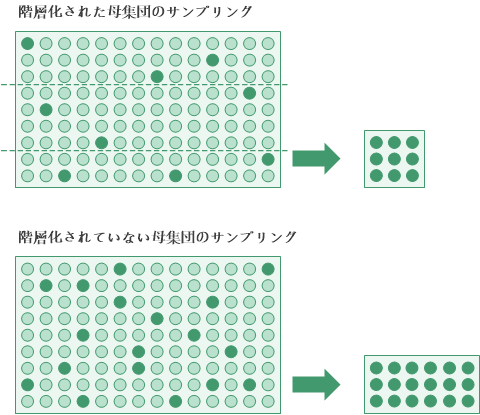
階層化
従来の変数サンプリングでは、サンプルを抽出する前に、母集団のレコードを数値的に階層化することができます。
階層化のメリットは、必要なサンプル サイズが通常、大幅に小さくなるとともに、統計的有効性が維持されることです。 サンプル サイズが小さくなるとは、目標を達成するのに必要なデータ分析作業が少なくなるということです。
機能の仕組み
階層化とは、層と呼ばれるいくつかの小グループに母集団を分割することです。 各層内の値は、比較的に同質であるのが理想です。
層間の境界は統計的アルゴリズム(ネイマン配分法)によって設定されます。 このアルゴリズムでは、各層内の値の散布度が最小化されるように境界の位置が決定されるため、母分散を使用する効果が減少します。 分散または '散らばり具合' が小さくなれば、必要なサンプル サイズも小さくて済みます。 設計上、各層の範囲は均一ではありません。
必要なサンプル数は、階層化されていない母集団全体に対して計算されるのでなく、層別に計算されて合計されます。 通常、非階層化アプローチより階層化アプローチの方が、データ セットに対するサンプル サイズがはるかに小さくて済みます。
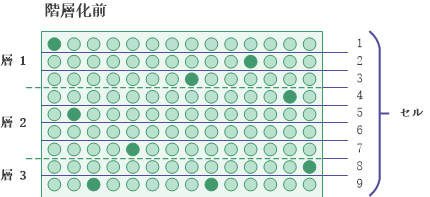
セルを使用した、階層化の前処理
階層化処理の一部として、母集団階層化の前処理に使用するセル数を指定します。 セルは分割間隔が均等であり、層より幅が狭くなります。
統計的アルゴリズムでは、層間の最適な境界を割り当てる計算の一部として各層内のレコード数が使用されます。 最終的に階層化された出力には、セルは保持されません。
指定するセルの数は、指定する層の数の 2 倍以上である必要があります。
メモ
階層化の前処理に使用するセル数と、セル方式のサンプル選択で使用するセル数は、同じものではありません。
過ぎたるは及ばざるがごとし
階層化はサンプル サイズを管理できる強力なツールですが、層数とセル数は慎重に指定してください。
手始めに以下を試してください。
- 層数:4 ~ 5
- セル数:50
ある層数またはセル数より大きい値を指定すると、ほとんどあるいはまったくサンプル サイズに影響しなくなる値があります。 ただし、これらの値も、大きなデータ セットを階層化する場合には、サンプルの設計や Analytics のパフォーマンスに悪影響を及ぼす可能性があります。
サンプル設計については、評価ステージに入ったら、母集団全体の虚偽表示を高い信頼性で推定するために、各層に最低限の数の虚偽表示が含まれていることを確認する必要があります。 虚偽表示数に比べて層数が多すぎる場合は、推定時に問題が発生する可能性があります。
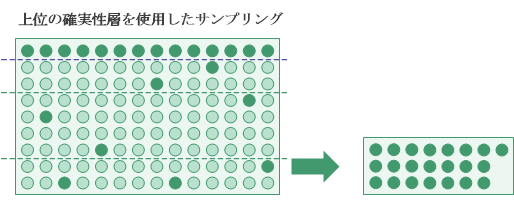
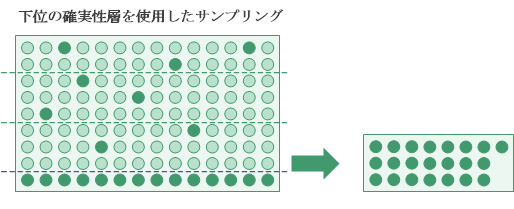
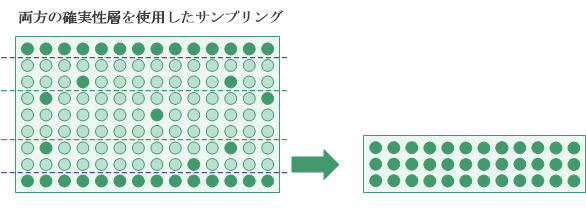
確実性層
階層化で使用可能なもう 1 つのオプションとして、確実性層があります。 上位確実性層、下位確実性層、またはその両方を定義できます。
確実性層の使用には以下の 2 つのメリットがあります。
- 自動包含単独で重要な項目や高額項目は、自動的にサンプルに含まれるため、ランダム選択方法によって除外されるリスクがありません。
- 分散減少法 確実性層項目はサンプル サイズ計算の対象から除外されます。 高額項目はその性質上、母分散(および、高額項目が計算対象になる場合は、必要なサンプル サイズ)の値を大幅に大きくする可能性があります。
確実性層の定義
確実性層を定義するには、カット オフ数値を指定します。
- 上位確実性層カットオフ カットオフ値以上のキー フィールドの簿価がすべて自動的に選択され、サンプルに取り込まれます。
- 下位確実性層カットオフカットオフ値未満のキー フィールドの簿価がすべて自動的に選択され、サンプルに取り込まれます。
下位確実性層を使用すると便利なのは、大量のマイナス値が母集団に存在し、かつそれらを自動で含めたい場合です。
確実性層によって捕捉されない母集団の部分は、ランダム選択方法を使用してサンプリングされます。
メモ
上位確実性層のカットオフ値を低くしたり、下位確実性層のカットオフ値を高くすると、データの性質に応じてサンプル サイズ全体が増える場合があります。
そのような極端なカットオフ値を設定しないようにしてください。 カットオフ値の設定値がわからない場合は、サンプリングのスペシャリストにお問い合わせください。
上位確実性層と下位確実性層の調整
サンプル抽出時に上位確実性層と下位確実性層を両方とも使用する場合は、上位確実性層カットオフ値と下位確実性層カットオフ値の関係を考慮する必要があります。
- 上位確実性層と下位確実性層は重なることができない 下位確実性層カットオフ値よりも小さい上位確実性層カットオフ値を指定すると、エラーが発生します。
- 十分に差がある上位確実性層カットオフ値と下位確実性層カットオフ値を選択する 互いに近すぎる上位確実性層カットオフ値と下位確実性層カットオフ値を指定すると、母集団の大部分が自動的にサンプルに含まれてしまうので、サンプリングの目的が達せられなくなります。
従来の変数サンプリングでレコードが選択される仕組み
従来の変数サンプリングでは、次の手順を使って、Analytics テーブルからサンプル レコードを選択します。
- サンプリングの基準として数値フィールドを指定します。 サンプリング単位はテーブル内のレコードです。
- Analytics では、ランダム選択方法を使ってテーブル内のレコードからサンプルが選択されます。
- 階層化を使用する場合は、各層からほぼ等しい数のレコードがランダムに選択されます。
- 階層化を使用しない場合は、母集団全体からレコードがランダムに選択されます。
- 選択されたレコードは、サンプリング出力テーブルに含まれます。
例
300 レコードあるテーブルが、Analytics により、3 つの層に分割され、以下のレコード番号が選択されます。
| 層 1 | 層 2 | 層 3 |
|---|---|---|
|
|
|
300 レコードある階層化されていないテーブルから、Analytics により下記のレコード番号が選択されます。 選択されたレコード番号が、階層化されているテーブルほど均一に分布していないことがわかります。
メモ
下記のレコード番号は比較しやすいように 3 つの列にグループ化してありますが、列が層を表しているわけではありません。
|
|
|
バイアスのないサンプルの選択
従来の変数サンプリングは、バイアスがかかっておらず、レコードに含まれる金額に基づいていません。 サンプルの対象として選択される可能性はどのレコードについても等しくなります。 金額を 1000 ドル含むレコード、250 ドル含むレコード、および 1 ドル含むレコードの選択されるチャンスは同等です。
つまり、指定したレコードが選択される確率は、そのレコードに含まれる金額とは無関係です。
最大級の金額が含まれるレコードを確実に選択したい場合は、確実性層を参照してください。