従来の変数サンプリングの準備
データ セットをサンプリングする前に、レコードが格納されているテーブルを階層化し、各層の統計的に有効なサンプル サイズを計算します。
Analytics の CVS 準備機能は、ユーザーが提供する入力値に基づき必要な値を計算します。
サンプル サイズを計算することの重要性
後続のサンプルの有効性を計るには、適切なサンプル サイズを計算することが重要になります。 サンプルが有効でない、または代表を表してない場合は、全母集団に対してサンプルで実行する監査手続きの結果を信頼して予測することはできません。
サンプル サイズの計算を省略したり、サンプル サイズを推定しないでください。
サンプル サイズの計算に使用するほとんどの入力値は、専門的な判断に基づきます。 運用環境でサンプリングの結果を信頼する前に、値が示す意味を十分理解するようにしてください。 不明な点がある方は、監査サンプリング担当者、または監査サンプリング スペシャリストにお問い合わせください。
数値の長さ制限
従来の変数サンプリングの準備段階では、いくつかの内部計算が行われます。 これらの計算では、最大 17 桁の数値がサポートされます。 計算結果が 17 桁を超える場合には、その計算結果が出力に含まれなくなるため、サンプリング処理を続行できなくなります。
注意:17 桁未満のソース データの数値から、17 桁を超える内部計算結果が生成される場合もあります。
精度上限の仕組み
従来の変数サンプリングを準備するときには、精度上限について、以下の一覧のオプションを 1 つ選択する必要があります。
選択したオプションは、サンプリング処理の CVS 評価ステージ中に生成する推定範囲の種類を指定します。
準備ステージ中にはオプションを選択する必要があります。選択するオプションは、サンプル サイズの計算の要件の 1 つであるためです。
| 精度制限 | CVS 評価中にこの種類の推定の場合: |
|---|---|
| BOTH:上限および下限 | 点推定と上下限のある両面範囲 |
| UPPER:上限 | 点推定と上限のある片面範囲 |
| LOWER:下限 | 点推定と下限のある片面範囲 |
範囲の面がないこと
範囲の面がないことは、従来の変数サンプリングの基礎を構成する正規分布またはベル曲線から発生します。
両面範囲
全体として過剰表示または過小表示されている可能性がある勘定を検査する場合は、一般的に、いずれかの方向の虚偽表示が許容可能または承認可能であると判断される虚偽表示金額を超えているかどうかということに関心があります。
両面範囲または推定が必要です。
- 下限は、指定する信頼度について勘定に存在しうる過剰表示の最大金額の推定です
- 上限は、指定する信頼度について勘定に存在しうる過小表示の最大金額の推定です
片面範囲
全体として過剰表示または過小表示されている可能性が高い勘定を検査する場合は、一般的に、1 つの方向の虚偽表示が許容可能または承認可能であると判断される虚偽表示金額を超えているかどうかということにのみ関心があると考えられます。
片面範囲または推定を使用できます。
- 下限のみの範囲は、指定する信頼度について勘定に存在しうる過剰表示の最大金額の推定です
- 上限のみの範囲は、指定する信頼度について勘定に存在しうる過小表示の最大金額の推定です
両面範囲または片面範囲を使用するべきですか。
CVS 評価ステージ中には、両面範囲の使用は、より慎重な選択です。 両面範囲では、勘定の虚偽表示の全体的な方向に関係なく、勘定が公正に表示されているかどうかを判断できます。
片面範囲を使用する利点は、必要なサンプル サイズを削減できることです。これにより、サンプル データの分析にかかる作業とコストが削減されます。 削減金額はさまざまなですが、一般的には 50% 未満です。
片面範囲を使用するリスクは、勘定の虚偽表示の全体的な方向が間違っている場合に、検査されていない方向における重大な虚偽表示を見逃し、勘定残高の公正さについて誤った判断を行う可能性があるということです。
入力値がサンプル サイズに影響する方法
入力値は Analytics で計算されるサンプル サイズに影響します。 [CVS 準備]ダイアログ ボックスで異なる入力値を実験し、サンプル サイズへの影響を確認できます。
注意
本番環境では、サンプル サイズを小さくする目的だけで、入力値を操作しないでください。 入力値は、サンプリングされるデータと監査目的に対して最も適切であるという専門的な判断に基づいているべきです。
| この入力値を増やす: | サンプル サイズを小さくします | サンプル サイズを大きくします |
|---|---|---|
| 階層数 |
特定の点の顎、層数を増やしても、ほとんどあるいはまったくサンプル サイズに影響しません。 |
|
| セル数 |
データの本質に応じてサンプル サイズを増やすか減らし、全体的にサンプル サイズを小さくします 特定の点の顎、セル数を増やしても、ほとんどあるいはまったくサンプル サイズに影響しません。 |
|
| 層のサンプル サイズの最小値 |
最小しきい値が 1 つ以上の層に適用される場合はサンプル サイズを大きくします |
|
| 最低合計サンプル サイズ |
最小しきい値が適用される場合はサンプル サイズを大きくします |
|
| 上位確実性層カットオフ |
データの本質に応じてサンプル サイズを増やすか減らします データの値が比較的均等に分布している場合は、上位確実性層カットオフを大きくすると、サンプル サイズが小さくなります |
|
| 下位確実性層カットオフ |
|
データの本質に応じてサンプル サイズを増やすか減らします データの値が比較的均等に分布している場合は、下位確実性層カットオフを大きくすると、サンプル サイズが大きくなります メモ マイナスのカットオフ値の場合、"大きくする" とはゼロ(0)に近づけることを意味します。 |
| 信頼度 (%) |
|
|
| 金額精度 |
|
|
| 推定誤謬数 | サンプル サイズには影響がありません | |
| 精度制限 | 両方は上または下よりも大きいサンプル サイズが必要です | |
手順
メモ
値を指定する際、3 桁の区切り記号やパーセント記号は含めないでください。 これらの文字を使用すると、コマンドを実行できないか、エラーが発生します。
- サンプリングする予定の簿価を含むテーブルを開きます。
- [サンプリング > 従来の変数サンプリング (CVS) > 準備]を選択します。
メモ
メニュー オプションは、テーブルが開いていない場合は無効です。
- [メイン]タブで[簿価]ドロップダウン リストから簿価フィールドを選択します。
- [精度制限]ドロップダウン リストで、該当するオプションを選択します。
- BOTH:上限および下限
- UPPER:上限
- LOWER:下限
メモ
オプションは以下で詳細に説明します。
- サンプル デザインを準備するために使用する入力値を入力します。
- 階層数
- セル数
- 層のサンプル サイズの最小値
- 最低合計サンプル サイズ
- 上位確実性層カットオフ
- 下位確実性層カットオフ
- 信頼度 (%)
- 金額精度
- 推定誤謬数
メモ
入力値は以下で詳細に説明します。
- 省略可能。 現在のビューの中に処理から除外したいレコードがある場合は、[If]テキスト ボックスに条件を指定します。直接入力するか、または[If]ボタンをクリックし、式ビルダーを利用して IF ステートメントを作成します。
注意
条件式を指定する場合、サンプル サイズの計算時とサンプルの抽出時とで、同じ条件式を使用する必要があります。
一方の段階で使用した条件を他方の段階で使用しない場合、つまり 2 つの条件が同一でない場合、サンプリング結果が通常、統計的に無効になります。
- [出力]タブ
- [To]パネルで、次のいずれかを選択します。
- 画面 - Analytics の表示領域に結果を表示します
ヒント
表示領域内で、リンク付きの任意の結果値をクリックすると、関連付けられているソース テーブル内の 1 つまたは複数のレコードにドリルダウンすることができます。
- ファイルは結果をテキスト ファイルに保存または追加します
ファイルは Analytics の外部に保存されます。
- 画面 - Analytics の表示領域に結果を表示します
- 出力タイプとして[ファイル]を選択した場合、次のいずれかを実行します。
- [名前]テキスト ボックスにファイル名を入力します。
- [名前]ボタンをクリックして、[保存]または[ファイルを保存する名前]ダイアログ ボックスでファイル名を入力するか、既存のファイルに上書きまたは追加する場合はそのファイルを選択します。
Analytics によってファイル名があらかじめ設定されている場合は、その設定されている名前を受け入れることも、あるいは変更することもできます。
また、絶対ファイル パスや相対ファイル パスを指定したり、別のフォルダーへ移動したり、プロジェクトの場所以外の場所にファイルを保存したり、その場所にあるファイルに追加したりすることもできます。 たとえば、C:\Results\Output.txt または Results\Output.txt のように指定します。
メモ
ファイル タイプ オプションは、使用している Analytics のエディションに応じて、ASCII テキスト ファイルまたは Unicode テキスト ファイルのいずれかのみです。
- [To]パネルで、次のいずれかを選択します。
- [OK]をクリックします。
CVS 準備出力結果が画面表示されるか、ファイルに保存されます。
値が入力済みの CVSSAMPLE コマンドのバージョンは表示に含まれます。
メモ
出力結果は以下で詳細に説明します。
CVSEVALUATE コマンドを後で使用するために保存しておきます(任意)。
従来の変数サンプリングによるサンプルを準備したら、CVSSAMPLE コマンドを再利用のために保存しておくと便利です。
- CVS 準備の表示領域の下部にある CVSSAMPLE へのリンクをクリックすることで、コマンドをコマンドラインに読み込みます。
- コマンドラインに読み込んだコマンドの全体をコピーし、Analytics スクリプトに保存します。
サンプルを準備したら、[CVS サンプル]ダイアログ ボックスまたは CVSSAMPLE コマンドを使ってレコードのサンプルを抽出できます。
メモ
CVSSAMPLE コマンドを実行する場合は、そのコマンドに出力テーブルの名前(と、オプションでシード値)を追加する必要があります。
詳細については、CVSSAMPLE コマンドを参照してください。
CVS 準備ダイアログ ボックスの入力値と結果
次の表は、[CSV 準備]ダイアログ ボックスの入力値と出力結果の詳細を示します。
メイン タブ – 入力値
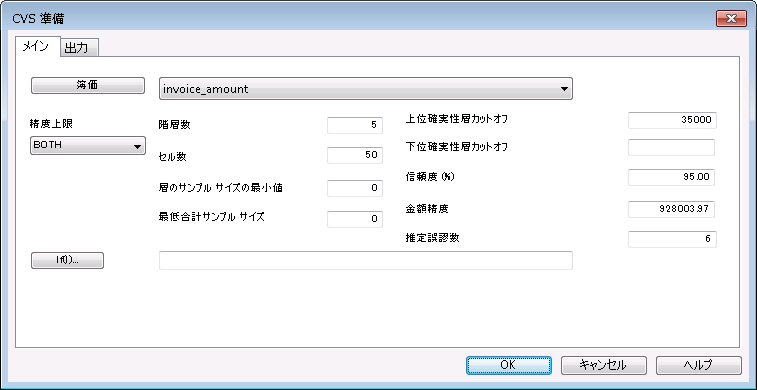
|
入力値 – CVS 準備ダイアログ ボックス |
説明 |
|---|---|
| 簿価 | 監査対象となる簿価が格納されているフィールド。 |
| 精度制限 |
使用する精度制限のタイプ。 BOTH:上限および下限 次の場合はこのオプションを選択します。
UPPER:上限 次の場合はこのオプションを選択します。
LOWER:下限 次の場合はこのオプションを選択します。
注意 選択するオプションがわからない場合は、両方を選択します。 詳細については、精度上限の仕組みを参照してください。 |
| 階層数 |
データセットを数値的に階層化するために使用する層(小グループ)の数。 層の数は下限が 1、上限が 256 です。 確実性層を指定する場合は、層数に含まれません。 詳細については、階層化を参照してください。 メモ 層数はセル数の 50% を超えることができません。 |
| セル数 |
データセットをあらかじめ階層化するために使用するセルの数。 セルの数は下限が 2、上限が 999 です。 詳細については、階層化を参照してください。 メモ セル数は少なくとも層の数の 2 倍である必要があります。\n |
| 層のサンプル サイズの最小値 | 各層からサンプリングする最小レコード数。 |
| 最低合計サンプル サイズ | データセット全体からサンプリングするレコードの最小数。 |
| 上位確実性層カットオフ |
省略可能。 上位確実性層のカットオフ値。 カットオフ値以上の簿価フィールドの金額が自動的に選択され、サンプルに取り込まれます。 カットオフ値を指定しない場合は、上位確実性層にレコードが追加されないようにする、次のデフォルトのカットオフ値が使用されます。 [簿価]フィールドの最高額より大きい(>)
詳細については、確実性層を参照してください。 |
| 下位確実性層カットオフ |
省略可能。 下位確実性層のカットオフ値。 カットオフ値以下の簿価フィールドの金額が自動的に選択され、サンプルに取り込まれます。 カットオフ値を指定しない場合は、下位確実性層にレコードが追加されないようにする、次のデフォルトのカットオフ値が使用されます。 [簿価]フィールドの最低額より小さい(<)
詳細については、確実性層を参照してください。 |
| 信頼度 (%) |
必要な信頼度。この信頼度で、結果のサンプルが母集団全体を表します。 たとえば、95 を指定した場合は、サンプルが 実際に 95% の確率で母集団を代表しているとお客様が信頼したいということを意味します。 信頼度は "サンプリング リスク" の補数です。 信頼度が 95% ということはサンプリング リスクが 5% ということと同じです。
|
|
金額精度 |
許容虚偽表示および勘定で想定される虚偽表示の間の差異である金額。 たとえば、許容虚偽表示が $29,000 であり、想定される虚偽表意が $5,800 の場合、23200($23,200 の差異)を入力します。 金額精度は、勘定が公正に表記されていると見なされる許容度の範囲を確立します。 |
| 推定誤謬数 |
省略可能。 サンプルで想定する最低誤謬数。 この値は CVS 計算で使用されません。 代わりに、次の状況のいずれかで、通知を発生させるために使用されます。
このような状況のいずれかでは、使用可能な唯一の評価方法は単位あたりの平均です。 |
出力結果
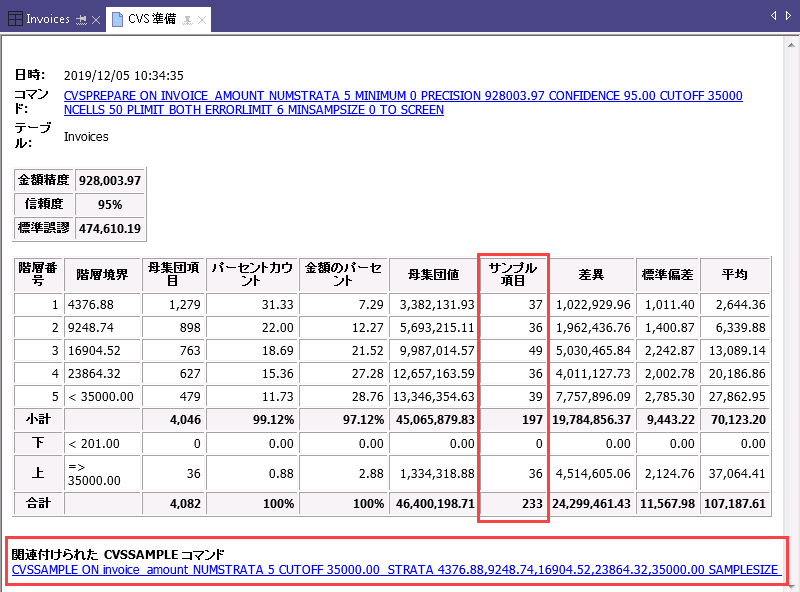
| 出力結果 – CVS 準備 | 説明 |
|---|---|
| 金額精度 | 入力として指定した金額精度。 |
| 信頼度 | 入力として指定した信頼度。 |
| 階層番号 |
各層に割り当てられた連続で増える数。 また、確実性層には次の数値が割り当てられます(ただし、この画面には表示されていません)。
|
| 階層境界 |
確実性層のカットオフ値と各層の上限の境界。 簿価は以下の場合に層に割り当てられます。
簿価はカットオフ値以上の場合に確実性層に割り当てられます。 簿価はカットオフ値以上の場合に上位確実性層に割り当てられます。 |
| 母集団項目 |
テーブルのレコード数。確実性層などの層にブレークダウンされます。 |
| パーセントカウント | 確実性層などの各層に含まれるレコード数の割合。 |
| 金額のパーセント | 合計簿価に対する割合。確実性層などの各層に含まれます。 |
| 母集団値 | テーブルの合計簿価。確実性層などの層にブレークダウンされます。 |
| サンプル項目 |
合計必要サンプル サイズ。層にブレークダウンされます。 確実性層のすべての項目を含みます。 |
| 関連付けられた CVSSAMPLE コマンド |
CVS サンプル段階を実行するためのコマンド。CVS 準備段階の値があらかじめ入力されています。 |