Los duplicados inexactos son valores de caracteres casi idénticos que pueden hacer referencia a la misma entidad en el mundo real. Por ejemplo, los cuatro valores siguientes pueden ser la misma compañía:
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intrecity Couriers
Entre las causas comunes de duplicados inexactos está los errores de entrada de datos tales como errores tipográficos y errores ortográficos, métodos diferentes de formato de datos, y convenciones diferentes de entrada de datos. La creación intencional de valores casi idénticos puede indicar fraude. Los duplicados inexactos obstaculizan el análisis de datos, el cual se basa en referencia de datos de entidades del mundo real de una forma uniforme.
Comparación entre duplicados inexactos y unión de inexactos
La función duplicados inexactos analiza valores de un único campo en una única tabla de Analytics. Para utilizar la correspondencia inexacta para combinar campos de dos tablas de Analytics en una nueva tabla única, consulte Unión de inexactos.
Cómo funciona
La función duplicados inexactos de Analytics le permite probar un campo de caracteres específico de una tabla para identificar los duplicados inexactos presentes en el campo. Los resultados de la salida agrupan los duplicados inexactos sobre la base del nivel de diferencia que usted especifique. Por medio del ajuste del nivel de diferencia, puede controlar la cantidad y el tamaño de los grupos de la salida, así como la cantidad de diferencia entre los miembros del grupo.
Para confirmar si los miembros del grupo de duplicados inexactos hacen referencia a la misma entidad del mundo real, probablemente deberá realizar análisis adicionales, como una prueba de duplicados de campos distintos del campo de prueba.
Nota
Detectar duplicados inexactos es más complicado que identificar duplicados exactos. Comprender la configuración que controla el grado de diferencia entre duplicados inexactos, y cómo se agrupan los duplicados inexactos en los resultados de salida, ayudará a optimizar su uso de la función.
Resultados de salida de duplicados inexactos
El siguiente ejemplo muestra los resultados de la salida que se obtienen al buscar duplicados inexactos en el campo Apellido de una tabla.
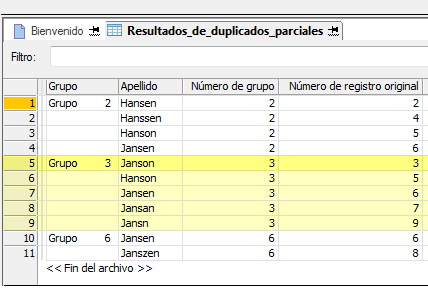
Los resultados de la salida se distribuyen en grupos que se identifican como 2, 3 y 6. El Número de registro original del primer duplicado inexacto de cada grupo se utiliza para identificar al grupo. Por ejemplo, “Janson” es el nombre del número de registro 3 en la tabla original y, como “Janson” es el primer valor del grupo, basándose en la secuencia de registros de la tabla original, el grupo se identifica como Grupo 3. Si desea obtener más información, consulte Cómo agrupar duplicados inexactos.
La función duplicados inexactos utiliza una comparación basada en caracteres
Al comparar dos valores, la función de duplicados inexactos realiza una comparación basada en caracteres, no una comparación basada en palabras. La función trata los espacios en blanco entre palabras como caracteres, y no diferencia entre palabras individuales. Independientemente del número de palabras individuales en un valor, la función trata los valores como una cadena de caracteres individual ininterrumpida.
La implicación de este enfoque es que algunos valores que, a simple vista, son duplicados inexactos podrían no ser incluidos en los resultados de salida, según la naturaleza de los datos y la configuración de diferencia que especifique en el cuadro de diálogo Duplicados inexactos.
Ejemplo
Considere estos nombres:
- “JW Smith” y “John William Smith”
- “Diamond Tire” y “Diamond Tire & Auto”
El primer ejemplo podría ser dos versiones del mismo nombre, uno que usa iniciales y el otro que usa el primer y el segundo nombre explícitos. El segundo ejemplo podría ser una versión corta y una versión larga del nombre de una compañía.
Ninguno de estos pares de nombres se devolverá como duplicado inexacto a menos que la configuración de diferencia sea bastante flexible, lo cual tendría el efecto adverso de devolver también grandes números de falsos positivos.
La función de duplicados inexactos procesa cada par de nombres simplemente como dos cadenas de caracteres. En cada caso, debido a que las dos cadenas difieren significativamente en longitud, las cadenas son significativamente diferentes entre sí cuando se consideran a nivel de los caracteres.
Si desea obtener más información, consulte Cómo funciona la configuración de diferencia.
Mejorar la efectividad del análisis de duplicados inexactos
Además de usar la función principal de duplicados inexactos, es posible que necesite limitar el tamaño del conjunto de datos de prueba, utilizar las funciones de ayuda de duplicados inexactos o concatenar los campos de prueba para alcanzar sus metas.
La siguiente tabla resume las distintas técnicas que se pueden usar para mejorar la efectividad del análisis de duplicados inexactos.
Si desea obtener más información acerca de las funciones de ayuda, consulte Funciones de ayuda de duplicados inexactos.
|
Técnica |
Función de Analytics |
Detalles |
|---|---|---|
|
Limite el tamaño del conjunto de datos de prueba |
Filtros Extraer subconjuntos de datos |
Reducir el tiempo de ejecución procesando solo registros que sean significativos para su análisis |
| Ordenar los elementos individuales en los valores del campo de prueba |
Función SORTWORDS( ) |
Reduzca el tamaño y aumente la precisión de los resultados minimizando la importancia de la posición física de los elementos individuales de los valores de prueba Nota Si bien la función de duplicados inexactos utiliza comparaciones basadas en caracteres, ordenar las palabras o los elementos de los valores de prueba tiene la ventaja de alinear los caracteres de forma más precisa entre las cadenas que se están comparando. |
|
Quitar los elementos genéricos de los valores del campo de prueba |
Función OMIT( ) |
Reduzca el tamaño y aumente la precisión de los resultados concentrándose solo en la parte de los valores de prueba donde pueda haber diferencias significativas |
|
Concatenar los campos para aumentar la unicidad de los valores de prueba |
una expresión de Analytics que utiliza el operador de suma (+) |
Reduzca el tamaño y aumente la precisión de los resultados probando valores más exclusivos, que se generan al concatenar dos o más campos |
|
Generar una lista única y exhaustiva de duplicados inexactos para un valor específico en los resultados de la salida de duplicados inexactos |
Función ISFUZZYDUP( ) |
Genere una lista conveniente y exhaustiva de duplicados inexactos para un valor de salida de relevancia particular para el objetivo de su análisis |
¿Debo ordenar el campo de prueba?
La comprobación de un campo en busca de duplicados inexactos no requiere el ordenamiento del campo. Ordenar una tabla por el campo de prueba antes de realizar la prueba no incrementa, de ninguna manera, la efectividad de la operación de duplicados inexactos. Sin embargo, puede elegir ordenar un campo de prueba por adelantado debido a que puede hacer más fácil examinar los resultados de salida, y el cuadro de diálogo Duplicados inexactos no incluye la opción Preordenar.
Nota
Si bien el ordenamiento de los valores del campo de prueba no incrementa la efectividad, ordenar los elementos individuales en los valores del campo con varios elementos, como domicilios, puede aumentar significativamente la efectividad. Si desea obtener más información, consulte Funciones de ayuda de duplicados inexactos.
Inclusión de duplicados exactos
Al detectar duplicados inexactos, usted tiene la opción de incluir duplicados exactos en los resultados de salida. Si está interesado en buscar sólo duplicados exactos, utilice en cambio la función de duplicados. Si desea obtener más información, consulte Detección de duplicados.