Información de concepto
Una unión de inexactos de Analytics utiliza la correspondencia inexacta de los valores del campo clave para combinar dos tablas de Analytics en una tercera tabla. En la mayoría de los aspectos, una unión de inexactos es como una unión de Analytics común (consulte Unir tablas). La principal diferencia es que, además de unir los registros basándose en los valores de los campos clave con una correspondencia exacta, una unión de inexactos puede unir registros que tienen una correspondencia aproximada.
La unión de inexactos es útil cuando las claves primaria y secundaria contienen el mismo tipo de datos, pero con leves diferencias de forma. O si los datos de los campos clave tienen pequeñas irregularidades, como errores de tipeo, que podrían impedir una correspondencia exacta.
Ejemplo
Escenario
Desea identificar a los proveedores que también son empleados como una de las formas de analizar datos para posibles pagos inadecuados.
Enfoque
Usted une la tabla maestra Vendor (Proveedores) con la tabla Employees (Empleados) utilizando el campo de domicilio como la clave común (Vendor_Street y Emp_Address). Sin embargo, la forma de los datos de domicilio en los campos clave tienen leves diferencias; por eso, utiliza una unión de inexactos en lugar de una unión común.
Una mirada a algunos de los datos
Sin un trabajo significativo de limpieza y unificación de los datos, sería imposible unir los valores de clave primaria y secundaria que se muestran a continuación utilizando una unión común de Analytics, aun cuando los domicilios son bastante similares.
| Valores de clave primaria | Valores de clave secundaria |
|---|---|
| 605 3rd Avenue | 605 Third Avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
Aunque se realizara una limpieza y unificación de los datos, los valores clave con diferencias mínimas de ortografía, como "Rowan" y "Rowen", probablemente no coincidirían.
Los valores clave podrían unirse con una unión de inexactos, según la configuración que se utilice.
Resultados de la salida
En el ejemplo de la tabla unida a continuación, las correspondencias exactas de los campos clave se destacan en violeta y las correspondencias inexactas de los campos clave, en verde.
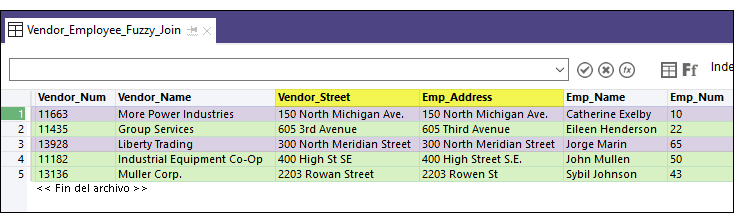
Comparación entre unión de inexactos y duplicados inexactos
Una unión de inexactos analiza los valores de los campos clave de dos tablas. Si desea comprobar un campo único en una tabla única de Analytics para detectar valores casi idénticos, consulte Análisis de los falsos duplicados.
Mejorar la efectividad de la unión de inexactos
Puede mejorar significativamente la efectividad de la unión de inexactos incorporando una o más de las siguientes técnicas:
- ordenar los elementos individuales en los valores del campo clave primario y secundario
- quitar los elementos genéricos de los valores del campo clave primario y secundario
- armonizar los valores del campo clave primario y secundario
Estas técnicas le permiten usar ajustes de inexactitud más estrictos y obtener las mismas coincidencias inexactas, al tiempo que se reduce la cantidad de coincidencias falso positivas. Puede usar las técnicas de manera independiente o combinadas.
Crear una expresión o un campo calculado
Para usar cualquiera de estas técnicas, debe crear una expresión o un campo calculado usando la función adecuada de Analytics y uno o ambos campos clave.
Si desea obtener más información sobre las expresiones, consulte Utilizar expresiones.
Si desea obtener más información acerca de los campos calculados, consulte Campos calculados.
Nota
El cuadro de diálogo Unir inexactos no permite crear una expresión en un campo clave secundario. Sin embargo, puede crear manualmente una expresión de campo clave secundario en la línea de comandos de Analytics o en un script. Otra opción consiste en crear un campo calculado para usarlo como campo clave secundario.
Ordenar los elementos individuales en los valores del campo clave
La función SORTWORDS( ) puede mejorar la efectividad de la unión de inexactos ordenando secuencialmente los elementos individuales del campo clave primario y secundario.
Ordenar los elementos, como los componentes de una dirección, puede hacer que los valores del campo con la misma información, pero con un formato diferente, se asemejan más entre sí. Una mayor semejanza mejora las posibilidades de que los valores del campo clave sean seleccionados como duplicados inexactos.
Si desea obtener más información, consulte Función SORTWORDS( ).
Si desea ver un video con una descripción general de SORTWORDS( ), vea Fuzzy Matching Using SORTWORDS() (Coincidencias inexactas con SORTWORDS()) (solo disponible en inglés).
Nota
Ordenar los elementos de los valores del campo clave es más conveniente para unir inexactos utilizando el algoritmo de distancia de Levenshtein.
Ordenar los elementos al unir inexactos con el algoritmo del coeficiente de Dice puede no ser beneficioso. Pruebe un conjunto de datos de muestra antes de decidir si usar SORTWORDS( ) junto con el algoritmo del coeficiente de Dice en un entorno de producción.
¡Precaución!
Si usa SORTWORDS( ) junto con la unión de inexactos, debe aplicar SORTWORDS( ) a ambas cadenas o ambos campos que se comparan.
Quitar elementos genéricos de los valores del campo clave
La función OMIT( ) puede mejorar la efectividad de la unión de inexactos quitando los elementos genéricos, como "Corporation" o "Inc.", o los caracteres como comas, puntos y símbolos "&", de los valores del campo clave primario y secundario.
La eliminación de los elementos genéricos y la puntuación centra la correspondencia inexacta únicamente en la parte de los valores del campo clave donde puede haber una diferencia significativa.
Si desea obtener más información, consulte Función OMIT( ).
Armonizar los valores del campo clave
Las funciones REPLACE( ) o REGEXREPLACE( ) pueden mejorar la efectividad de la unión de inexactos armonizando las diferentes formas del mismo elemento en los valores del campo primario y secundario. Por ejemplo, puede armonizar "Street", "St." y "St" para utilizar siempre el valor "St".
Armonizar los elementos puede hacer que los valores del campo clave con la misma información, pero un formato diferente, se asemejen más entre sí. Una mayor semejanza mejora las posibilidades de que los valores del campo clave sean seleccionados como duplicados inexactos.
Si desea obtener más información, consulte Función REPLACE( ) para realizar reemplazos directos y Función REGEXREPLACE( ) para realizar reemplazos más complejos.
Tamaño de la tabla de salida y rendimiento del comando
Tamaño de la tabla de salida
La unión de inexactos es similar a la unión de muchos a muchos de Analytics. En principio, todos los valores clave primarios podrían tener una correspondencia con todos los valores clave secundarios. El tamaño de la tabla de salida puede ser muchas veces mayor que el tamaño de cualquiera de las tablas de entrada primaria o secundaria.
Desempeño del comando
Los algoritmos de correspondencia inexacta se aseguran de que solo se unan los valores clave que tienen un grado específico de imprecisión o los valores con una correspondencia exacta. Sin embargo, se deben probar todas las posibles correspondencias primarias. Esto significa que el proceso de unión de inexactos puede llevar mucho tiempo. La cantidad de pruebas individuales que se deben realizar es igual a la cantidad de registros de la tabla primaria por la cantidad de registros de la tabla secundaria.
Limitar la coincidencia a la primera correspondencia secundaria
Puede reducir significativamente el tiempo de procesamiento y reducir el tamaño de los resultados de la salida seleccionando Unir únicamente la primera instancia de las correspondencias clave secundarias. Al activar esta opción, se especifica que cada valor clave primario se une exclusivamente a la primera instancia de cualquier valor clave secundario.
La activación de esta opción es adecuada en cualquiera de las siguientes situaciones:
- ¿Hay alguna correspondencia? Solo desea saber si existe alguna correspondencia, exacta o inexacta, entre dos tablas, y desea reducir el tiempo de procesamiento necesario para identificar todas las correspondencias.
- Una correspondencia como máximo está seguro de que existe como máximo una correspondencia en la tabla secundaria para el valor de clave primaria.
Esta opción no es adecuada si necesita obtener resultados que contengan todas las uniones posibles entre los valores de clave primaria y secundaria.
Nota
Si selecciona Unir únicamente la primera instancia de las correspondencias clave secundarias y la primera instancia de una correspondencia es exacta, las correspondencias inexactas posteriores del valor clave primario no se incluyen en la tabla de salida unida.
Mejores prácticas
Al preparar las tablas de entrada primaria y secundaria, y especificar el nivel de inexactitud, tenga en cuenta el tamaño de la tabla de salida y el desempeño del comando.
- Adapte los datos Asegúrese de que se incluyan únicamente los registros pertinentes en las tablas primaria y secundaria. Si algunos registros no tienen probabilidades de tener una correspondencia, quítelos con un filtro antes de realizar la unión de inexactos.
- Pruebas de ensayo Si tiene conjuntos de datos de gran volumen, realice pruebas de ensayo con una pequeña parte de los datos para determinar de forma más eficiente los ajustes de los algoritmos de la unión de inexactos. Comience con un ajuste de inexactos más conservador y, si es necesario, hágalo progresivamente más laxo.
Algoritmos de correspondencia de inexactos
Al realizar una unión de inexactos, debe escoger entre dos algoritmos de correspondencia de inexactos diferentes:
- Coeficiente de Dice
- Distancia de Levenshtein
Los algoritmos actúan de manera independiente entre sí y pueden generar resultados algo distintos. Un enfoque consiste en realizar una unión de inexactos dos veces, una vez con cada algoritmo, y después comparar los resultados. En general, en cada conjunto de resultado existe una cantidad de correspondencias inexactas que se superponen, pero algunos resultados pueden ser exclusivos de cada conjunto de resultados.
Grado de inexactitud
Usted especifica el grado de inexactitud de cada algoritmo, lo cual puede modificar drásticamente el tamaño y la conformación del conjunto de resultados. El "grado de inexactitud" se relaciona con el nivel de coincidencia entre dos valores.
Según el algoritmo que seleccione, utilizará los siguientes ajustes para controlar el grado de inexactitud:
| Algoritmo | Ajuste |
|---|---|
|
Coeficiente de Dice |
|
|
Distancia de Levenshtein |
|
Haga pruebas con diferentes grados de inexactitud. Comience de manera conservadora y genere conjuntos de resultados más pequeños. A continuación, haga los ajustes progresivamente más laxos hasta que comience a obtener demasiados valores unidos que obviamente no son correspondencias (falsos positivos).
Coeficiente de Dice
El algoritmo del coeficiente de Dice mide el grado de similitud entre un valor clave primario y uno secundario, utilizando una escala de 0,0000 a 1,0000. Cuanto mayor sea el coeficiente de Dice de los dos valores, mayor será su similitud.
| Coeficiente de Dice | Significado |
|---|---|
| 1,0000 |
Cada valor está conformado por un conjunto de caracteres idéntico, aunque estos puedan estar en un orden diferente y presentar diferencias en el uso de mayúsculas y minúsculas. Los n-gramas de los dos valores son 100 % idénticos. A continuación, se explican los N-gramas. |
| 0,7500 |
Los n-gramas de los dos valores son 75 % idénticos. |
| 0,0000 | Los dos valores no tienen n-gramas idénticos, o la longitud especificada en el ajuste del N-grama es superior al más corto de los dos valores que se están comparando. |
N-gramas
El coeficiente de Dice se calcula dividiendo primero los valores que se están comparando en n-gramas. Los N-gramas son bloques superpuestos de caracteres, con una longitud de n, que es la longitud que usted especifica en el ajuste N-grama.
Aquí se incluyen dos de los valores del ejemplo anterior divididos en n-gramas con una longitud de 2 caracteres (n = 2).
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
|---|---|
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
El coeficiente de Dice representa el porcentaje de n-gramas de los dos valores que son idénticos. En este caso, 20 de 28 n-gramas son idénticos, lo que equivale a 71,43 %, o a 0,7143 en una expresión decimal.
Nota
El incremento de la longitud en el ajuste N-grama hace que el criterio para la similitud entre dos valores sea más estricto.
Porcentaje
Al especificar un ajuste de Porcentaje, está especificando el coeficiente de Dice mínimo permitido entre dos valores para que se los considere una correspondencia inexacta. Por ejemplo, si especifica 0,7500, al menos el 75 % de los n-gramas de los dos valores deben ser idénticos para que haya una correspondencia.
| Ajuste del porcentaje | Significado | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0,7500 |
Para que se considere una correspondencia inexacta, al menos el 75 % de los n-gramas de los dos valores deben ser idénticos. |
Sin correspondencia, no se incluyen en la tabla unida (Coeficiente de Dice = 0,7143) |
| 0.7000 |
Para que se considere una correspondencia inexacta, al menos el 70 % de los n-gramas de los dos valores deben ser idénticos. |
Con correspondencia, se incluyen en la tabla unida (Coeficiente de Dice = 0,7143) |
Si desea obtener información detallada sobre el funcionamiento del coeficiente de Dice, consulte Función DICECOEFFICIENT( ).
Distancia de Levenshtein
El algoritmo de la distancia de Levenshtein mide el grado de diferencia entre el valor clave primario y el secundario, en una escala de números enteros que comienza en 0. La escala representa el número de ediciones de caracteres individuales requerido para hacer que un valor sea idéntico a otra. Mientras mayor sea la distancia de Levenshtein entre dos valores, mayor será la diferencia entre ellos.
| Distancia de Levenshtein | Significado |
|---|---|
| 0 | Cada valor está conformado por un conjunto de caracteres idéntico, en el mismo orden. El uso de mayúsculas y minúsculas puede ser diferente. |
| 2 |
Se necesitan dos ediciones de caracteres individuales para que los dos valores sean idénticos. Por ejemplo: "Smith" y "Smythe"
|
| 3 |
Se necesitan tres ediciones de caracteres individuales para que los dos valores sean idénticos. Por ejemplo: "Hanssen" y "Jansn"
|
Distancia
Al especificar un ajuste de Distancia, está especificando la distancia de Levenshtein máxima permitida entre dos valores para que se los considere una correspondencia inexacta. Por ejemplo, si especifica 2, no se necesitan más de dos ediciones para que los valores sean idénticos.
| Ajuste de la Distancia | Significado | Hanssen / Jansn |
|---|---|---|
| 2 |
Para que se considere una correspondencia inexacta, no se deben necesitar más de dos ediciones de caracteres para que los valores sean idénticos. |
Sin correspondencia, no se incluyen en la tabla unida (Distancia de Levenshtein = 3) |
| 3 |
Para que se considere una correspondencia inexacta, no se deben necesitar más de tres ediciones de caracteres para que los valores sean idénticos. |
Con correspondencia, se incluyen en la tabla unida (Distancia de Levenshtein = 3) |
Si desea obtener información detallada acerca del funcionamiento de la distancia de Levenshtein, consulte Función LEVDIST( ). A diferencia de la función, el algoritmo de la distancia de Levenshtein que se utiliza en la unión de inexactos recorta automáticamente los espacios en blanco iniciales y finales, y no distingue entre mayúsculas y minúsculas.
Pasos
Puede usar la correspondencia inexacta de los valores del campo clave para combinar dos tablas de Analytics en una tercera tabla.
- En el navegador, abra la tabla primaria, haga clic con el botón derecho en la tabla secundaria y seleccione Abrir como secundaria.
Los iconos de las tablas primaria y secundaria se actualizan con los números 1 y 2 para indicar su relación entre ellas

 .
. - Seleccione Datos > Unir inexactos.
- En la ficha Principal seleccione el algoritmo de correspondencia inexacta que desea utilizar:
- Coeficiente de Dice
- Levenshtein
- Según el algoritmo que seleccionó, proporcione los ajustes para controlar el grado de inexactitud.
Coeficiente de Dice
- N-grama
- Porcentaje
Levenshtein
- Distancia
Los ajustes se explican a continuación.
- (Opcional) Seleccione Unir únicamente la primera instancia de las correspondencias clave secundarias para especificar que cada valor clave primario se una exclusivamente a la primera instancia de cualquier valor clave secundario correspondiente.
- Seleccione el campo clave principal de la lista Claves primarias.
Solo puede seleccionar un campo clave primario y debe ser un campo de caracteres.
- Seleccione el campo clave secundario de la lista Claves secundarias.
Solo puede seleccionar un campo clave secundario y debe ser un campo de caracteres.
- En las listas Campos primarios y Campos secundarios, seleccione los campos que desea incluir en la tabla unida.
Nota
Debe seleccionar explícitamente los campos de clave primaria y secundaria si desea incluirlos en la tabla unida.
Consejo
Puede presionar Ctrl+clic para seleccionar varios campos no adyacentes y Mayús+clic para seleccionar varios campos adyacentes.
- En el cuadro de texto En, especifique el nombre de la nueva tabla unida.
- (Opcional) En la ficha Más:
- Si solo desea procesar un subconjunto de registros, seleccione una de las opciones del panel Alcance.
- Si desea anexar (agregar) los resultados de salida al final de una tabla de Analytics existente, seleccione Anexar a archivo existente.
- Haga clic en Aceptar.
La nueva tabla unida se envía a la salida.
Opciones del cuadro de diálogo Unir inexactos
Las tablas a continuación proporcionan información detallada acerca de las opciones del cuadro de diálogo Unir inexactos.
Ficha Principal
| Opciones: Cuadro de diálogo Unir inexactos | Descripción |
|---|---|
| Coeficiente de Dice |
Use el coeficiente de Dice para obtener correspondencias inexactas entre los valores clave primario y secundario.
|
| Levenshtein |
Use la distancia de Levenshtein para obtener correspondencias inexactas entre los valores clave primario y secundario.
|
| Unir únicamente la primera instancia de las correspondencias clave secundarias |
Especifica que cada valor clave primario se une exclusivamente a la primera instancia de cualquier clave secundaria correspondiente. Si deja la opción sin marcar, el comportamiento predeterminado es unir cada valor de clave primaria con todas las instancias de cualquier correspondencia de clave secundaria. |
| Tabla secundaria | Un método alternativo de seleccionar la tabla secundaria. |
| Claves primarias Claves secundarias |
Especifica el campo clave común a usar para unir las dos tablas.
Pautas para campo clave:
|
| Campos primarios Campos secundarios |
Especifica los campos que se incluirán en la tabla unida.
|
| Utilizar la tabla de salida | Especifica si una tabla de Analytics que contiene resultados de salida se abre automáticamente al finalizar la operación |
| Si |
(Opcional) Le permite crear una condición para excluir registros del procesamiento.
|
| En | Especifica el nombre y la ubicación de la tabla de salida.
Independientemente del lugar en que guarde la tabla de salida, esta se agrega al proyecto abierto si ya no está en el proyecto. Si Analytics pre-completa un nombre de tabla, puede aceptar el nombre pre-completado o cambiarlo. |
Ficha Más
| Opciones: Cuadro de diálogo Unir inexactos | Descripción |
|---|---|
| Panel de alcance | Especifica qué registros en la tabla primaria son procesados:
Nota El número de registros especificados en las opciones Primero o Siguiente hace referencia tanto al orden físico como al orden indexado de los registros de una tabla y hace caso omiso de cualquier filtrado u ordenación rápida aplicados a la vista. Sin embargo, los resultados de las operaciones analíticas respetan cualquier filtrado. Si a una vista se aplica ordenación rápida, Siguiente se comporta como Primero. |
| Anexar al archivo existente | Especifica que los resultados de salida se anexan (agregan) al final de una tabla de Analytics existente. Nota Se recomienda dejar Anexar a archivo existente sin seleccionar si no está seguro de que los resultados de la salida y la tabla existente tengan una estructura de datos idéntica. Si desea más información acerca de la anexión y la estructura de datos, consulte Anexión de resultados de la salida a una tabla existente. |
| Aceptar | Ejecuta la operación.
|