Fuzzy duplicates are nearly identical character values that may refer to the same real-world entity. For example, the following four values may all be the same company:
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intrecity Couriers
Common causes of fuzzy duplicates are data entry errors such as typos and misspellings, differing methods of formatting data, and differing data entry conventions. The intentional creation of nearly identical values may indicate fraud. Fuzzy duplicates impede data analysis, which relies upon data referencing real-world entities in a consistent manner.
Fuzzy duplicates versus fuzzy join
The fuzzy duplicates feature analyzes values in a single field in a single Analytics table. To use fuzzy matching to combine fields from two Analytics tables into a new, third table, see Fuzzy join.
How it works
The fuzzy duplicates feature in Analytics lets you test a specific character field in a table to identify any fuzzy duplicates contained by the field. The output results group fuzzy duplicates based on a degree of difference that you specify. By adjusting the degree of difference, you can control the number and the size of output groups and the amount of difference between group members.
To confirm whether fuzzy duplicate group members do in fact reference the same real-world entity, you may need to perform additional analysis, such as a duplicates test of fields other than the test field.
Note
Testing for fuzzy duplicates is more involved than identifying exact duplicates. Understanding the settings that control the degree of difference between fuzzy duplicates, and how fuzzy duplicates are grouped in the output results, will help optimize your use of the feature.
Fuzzy duplicate output results
The example below shows the output results produced by testing for fuzzy duplicates in the Last Name field of a table.
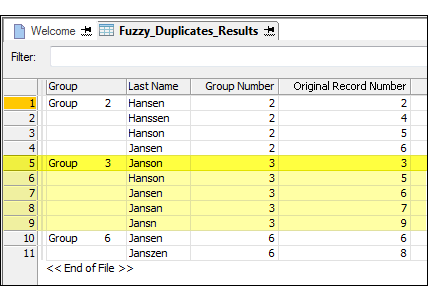
The output results are arranged in groups identified as 2, 3, and 6. The Original Record Number of the first fuzzy duplicate in each group is used to identify the group. For example, “Janson” is the name in record number 3 in the original table, and because “Janson” is the first value in the group, based on record sequence in the original table, the group is identified as Group 3. For more information, see How fuzzy duplicates are grouped.
The fuzzy duplicates feature uses character-based comparison
When comparing two values, the fuzzy duplicates feature performs a character-based comparison, not a word-based comparison. The feature treats blanks or spaces between words as characters, and does not differentiate between individual words. Regardless of the number of individual words in a value, the feature treats the value as a single, unbroken string of characters.
The implication of this approach is that some values that appear to be fuzzy duplicates to the human eye may not be included in the output results, based on the nature of the data and the difference settings you specify in the Fuzzy Duplicates dialog box.
Example
Consider these names:
- “JW Smith” and “John William Smith”
- “Diamond Tire” and “Diamond Tire & Auto”
The first example could be two versions of the same name, one using initials and the other using spelled-out first and middle names. The second example could be a short version and a longer version of a company name.
Neither of these pairs of names will be returned as fuzzy duplicates unless the difference settings are quite loose, which would have the adverse effect of also returning large numbers of false positives.
The fuzzy duplicates feature processes each pair of names as simply two strings of characters. In each case, because the two strings differ significantly in length, the strings are significantly different from each other when considered at the character level.
For more information, see How the difference settings work.
Improving the effectiveness of fuzzy duplicate analysis
In addition to using the main fuzzy duplicates feature, you may need to limit the size of the test data set, use fuzzy duplicate helper functions, or concatenate test fields, to achieve your goals.
The table below summarizes the different techniques for improving the effectiveness of fuzzy duplicate analysis.
For more information about the helper functions, see Fuzzy duplicate helper functions.
|
Technique |
Analytics feature |
Details |
|---|---|---|
|
Limit the size of the test data set |
Filters Extracting subsets of data |
Reduce execution time by processing only records that are meaningful to your analysis |
| Sort individual elements in test field values |
SORTWORDS( ) function |
Reduce the size and increase the precision of results by minimizing the importance of the physical position of individual elements in test values Note Although the fuzzy duplicates feature uses character-based comparison, sorting words or elements in test values has the benefit of aligning characters more closely between strings being compared. |
|
Remove generic elements from test field values |
OMIT( ) function |
Reduce the size and increase the precision of results by focusing on just the portion of test values where meaningful differences may occur |
|
Concatenate fields to increase the uniqueness of test values |
an Analytics expression using the Add operator (+) |
Reduce the size and increase the precision of results by testing values of greater uniqueness, which are produced by concatenating two or more fields |
|
Generate a single, exhaustive list of fuzzy duplicates for a specific value in the fuzzy duplicates output results |
ISFUZZYDUP( ) function |
Produce a convenient and exhaustive list of fuzzy duplicates for a output value of particular relevance to your analysis goal |
Should I sort the test field?
Testing a field for fuzzy duplicates does not require that the field is sorted. Sorting a table by the test field in advance of testing does not increase the effectiveness of the fuzzy duplicates operation in any way. However, you may choose to sort a test field in advance because it can make the output results easier to scan, and the Fuzzy Duplicates dialog box does not include the Presort option.
Note
Although sorting test field values does not increase effectiveness, sorting individual elements in field values with multiple elements, such as addresses, can significantly increase effectiveness. For more information, see Fuzzy duplicate helper functions.
Including exact duplicates
When testing for fuzzy duplicates, you can optionally include exact duplicates in the output results. If you are interested in finding only exact duplicates, use the duplicates feature instead. For more information, see Testing for duplicates.