Nutzen Sie automatisiertes maschinelles Lernen in Analytics, um zu Daten ohne Labels gehörende Klassen oder numerische Werte vorherzusagen. Daten haben keine Labels, falls die Klassen oder numerischen Werte, an denen Sie interessiert sind, nicht in den Daten existieren. Sie könnten zum Beispiel maschinelles Lernen verwenden, um Kreditausfälle oder zukünftige Hauspreise vorherzusagen:
| Vorhersageproblem | Vorhersagetyp | Beschreibung |
|---|---|---|
| Kreditausfälle | Klassifizierung |
Auf Basis von Informationen über Antragsteller, wie Alter, Berufskategorie usw., möchten Sie vorhersagen, bei welchen Antragstellern es zu einem Kreditausfall kommen könnte. Fallen Antragsteller anders ausgedrückt in die Klasse Ausfall = Ja oder Ausfall = Nein? |
| Künftige Hauspreise | Regression | Auf Basis von Features wie Alter, Fläche, Postleitzahl, Anzahl Schlaf- und Badezimmer usw. möchten Sie den zukünftigen Verkaufspreis von Häusern vorhersagen. |
Automatisiertes maschinelles Lernen
Maschinelles Lernen in Analytics ist „automatisiert“, weil zwei verbundene Befehle (Trainieren und Vorhersagen) alle Berechnungen vornehmen, um ein Vorhersagemodell zu trainieren sowie auszuwerten und um das Vorhersagemodell auf ein Dataset ohne Labels anzuwenden. Die von Analytics zur Verfügung gestellte Automatisierung ermöglicht Ihnen die Nutzung von maschinellem Lernen für Daten Ihres Unternehmens, ohne dass Sie dafür spezialisierte Data-Science-Kenntnisse benötigen.
Workflow für das Trainieren und Vorhersagen
Der Workflow für das Trainieren und Vorhersagen besteht aus zwei verwandten Prozessen sowie zwei verwandten Datasets:
- Training verwendet ein Trainingsdataset (mit Labels)
- Vorhersage verwendet ein neues Dataset (ohne Labels)
Training
Das Training wird zuerst durchgeführt. Dabei wird ein Trainingsdataset verwendet, das ein Label-Feld (auch als Zielfeld bezeichnet) beinhaltet.
Das Label-Feld enthält die bekannte Klasse oder den bekannten numerischen Wert jedes Datensatzes innerhalb des Trainingsdatasets, also beispielsweise, ob ein Kreditnehmer bei einem Kredit säumig wurde (J/N), oder den Verkaufspreis eines Hauses.
Mit Algorithmen für maschinelles Lernen erstellt das Training ein Vorhersagemodell. Das Training erstellt einige unterschiedliche Modellpermutationen, um das Modell zu finden, das für Ihre Vorhersage am besten geeignet ist.
Vorhersage
Als Zweites wird die Vorhersage durchgeführt. Die Vorhersage wendet das im Training erstellte Vorhersagemodell auf ein neues Dataset ohne Labels an, das Daten enthält, die dem Trainingsdataset ähneln.
Labelwerte, wie Kreditausfälle oder Verkaufspreise von Häusern, sind im neuen Dataset nicht vorhanden, weil es sich dabei um zukünftige Ereignisse handelt.
Mit dem Vorhersagemodell sagt die Vorhersage eine Klasse oder einen numerischen Wert vorher, die/der jedem Datensatz im neuen Dataset ohne Labels zugeordnet wird.
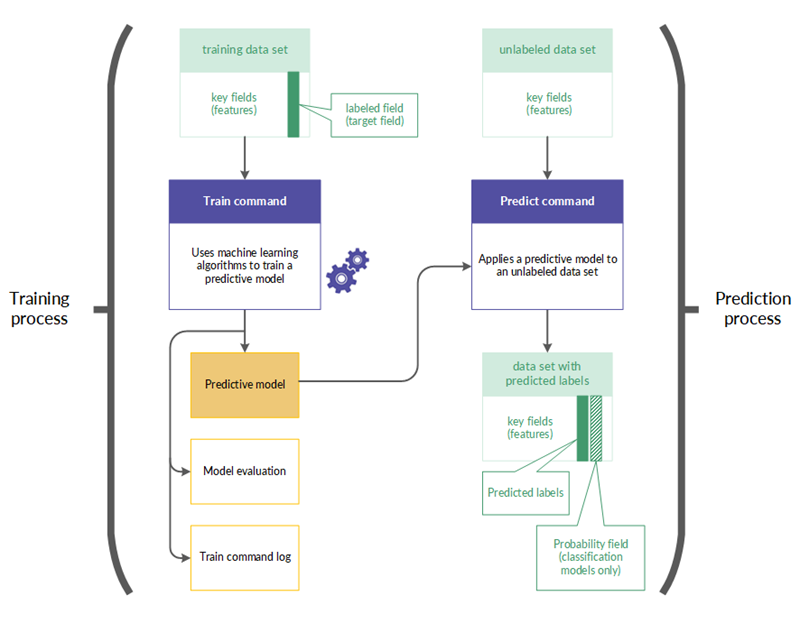
Workflow für das Trainieren und Vorhersagen im Detail
| Sortierfolge | Prozess | Beschreibung | Dataset-Beispiele |
|---|---|---|---|
| 1 |
Training (Trainingsbefehl) |
|
|
| 2 |
Vorhersage (Vorhersagebefehl) |
|
|
Verarbeitungszeit
Die für maschinelles Lernen benötigten Berechnungen sind zeitaufwändig und rechenintensiv. Das Training für ein Vorhersagemodell mit großem Dataset und vielen Feldern kann Stunden dauern und ist in der Regel ein Task, der über Nacht ausgeführt werden sollte.
Das Einschließen von Datumzeit-Schlüsselfeldern in das Training ist besonders rechenintensiv, weil jedes Datumzeit-Feld verwendet wird, um automatisch zehn synthetische Features abzuleiten. Synthetische Datumzeit-Features können den Umfang der Daten für Vorhersagen beträchtlich erweitern. Sie sollten Datumzeit-Felder aber nur dann einschließen, wenn Sie meinen, dass sie relevant sein könnten.
Tipp
Wenn Sie sich in maschinelles Lernen mit Analytics nur einarbeiten, verwenden Sie kleine Datasets, sodass die Verarbeitungszeiten überschaubar bleiben und Sie recht schnell Ergebnisse sehen.
Strategien zur Verringerung der Größe des Trainingsdatasets
Sie können unterschiedliche Strategien verwenden, um die Größe des Trainingsdatasets und die damit zusammenhängende Verarbeitungszeit zu verringern, ohne die Genauigkeit des entstehenden Vorhersagemodells zu beeinträchtigen.
- Schließen Sie Felder vom Training aus, die nicht zur Vorhersagegenauigkeit beitragen. Schließen Sie irrelevante und redundante Felder aus.
- Schließen Sie Datumzeit-Felder vom Training aus, wenn sie nicht zur Vorhersagegenauigkeit beitragen. Seien Sie aber mit der Annahme vorsichtig, dass Datumzeit-Felder nicht relevant sind. Weitere Informationen finden Sie unter Datumzeit-Schlüsselfelder.
- Ziehen Sie eine Stichprobe aus dem Trainingsdataset und verwenden Sie die Stichprobendaten als Eingabe für das Training. Beispiele für mögliche Stichprobenansätze:
- Abwägung der Größe der Datenklassen durch Stichprobe vorherrschender Klassen, um durchschnittliche Mindestgröße von Klassen zu schätzen
- zufällige Stichprobe des gesamten Trainingsdatasets
- geschichtete Stichprobe auf Basis von Features
- geschichtete Stichprobe auf Basis von Clustering
Datumzeit-Schlüsselfelder
Sie können ein oder mehrere Datumzeit-Felder als Schlüsselfelder verwenden, wenn Sie ein Vorhersagemodell trainieren. Normalerweise gibt es in einem Datumzeit-Feld zu viele eindeutige Werte, um das Feld beim Training zu einer angemessenen Quelle für Kategorien bzw. identifizierbare Features zu machen. Datumzeit-Rohdaten mögen auch den Eindruck erwecken, keinen Zusammenhang zu dem Zielfeld zu haben, das Sie interessiert.
Nach der Kategorisierung könnten Datumzeit-Daten aber relevant sein. Von Ihnen untersuchte Ereignisse treten möglicherweise an bestimmten Wochentagen oder zu bestimmten Tageszeiten auf.
Im Training wird aus jedem Datumzeit-Feld automatisch eine Reihe synthetischer Features abgeleitet, indem Datumzeit-Rohdaten kategorisiert werden. Diese synthetischen Features werden dann in den Algorithmus einbezogen, der ein Vorhersagemodell generiert.
Aus Datumzeit-Feldern abgeleitete synthetische Features
Die aus Datum-, Zeit- oder Datumzeit-Felder abgeleiteten synthetischen Features sind unten aufgelistet.
| Beschreibung des synthetischen Features | Art des Features | Name des synthetischen Features |
|---|---|---|
| Wochentag | Numerisch (1 bis 7) | Feldname_DOW |
| Monat des Jahres | Numerisch (1 bis 12) | Feldname_MONTH |
| Quartal | Numerisch (1 bis 4) | Feldname_QTR |
| Anzahl der Tage seit Monatsbeginn | Numerisch (1 bis 31) | Feldname_DAY |
| Anzahl der Tage seit Jahresbeginn | Numerisch (1 bis 366) | Feldname_DOY |
| Sekunden | Numerisch (00 bis 59) | Feldname_SECOND |
| Stunde des Tages | Numerisch (1 bis 24) | Feldname_HOUR |
| Anzahl der Sekunden seit Tagesbeginn | Numerisch (1 bis 86400) | Feldname_SOD |
| Quartil des Tages |
Kategorisch:
|
Feldname_QOD |
| Oktil des Tages |
Kategorisch:
|
Feldname_OOD |
Vorhersagemodell trainieren
Hinweis
Das Training unterstützt ein Dataset mit maximaler Größe von 1 GB.
Wenn die Menüoptionen für maschinelles Lernen deaktiviert sind, ist die Python Engine wahrscheinlich nicht installiert. Weitere Informationen finden Sie unter Installieren Sie ACL für Windows.
Schritte
Grundlegende Einstellungen des Trainings festlegen
- Öffnen Sie die Analytics-Tabelle mit dem Trainingsdataset.
- Wählen Sie aus dem Analytics-Hauptmenü Maschinelles Lernen > Trainieren.Analytics
- Legen Sie die für das Training eingeräumte Zeit fest:
Option Details Zeit für die Suche nach optimalem Modell Die Gesamtzeit in Minuten, die für das Erstellen und Testen von Vorhersagemodellen und die Auswahl eines Siegermodells verwendet werden soll.
Legen Sie eine Suchzeit fest, die mindestens der zehnfachen maximalen Auswertungszeit pro Modell entspricht.
Maximale Zeit je Modellauswertung Maximale Laufzeit pro Modellauswertung in Minuten.
Planen Sie pro 100 MB an Trainingsdaten 45 Minuten ein.
Hinweis
Die gesamte Laufzeit des Trainings setzt sich aus der Suchzeit zuzüglich bis zur doppelten maximalen Modellauswertungszeit zusammen.
Die vorgeschlagene Zeitzuteilung stellt ein vernünftiges Gleichgewicht zwischen Verarbeitungszeit und der möglichen Auswertung zahlreicher Modelltypen sicher.
- Legen Sie den zu verwendenden Vorhersagetyp fest:
- Klassifizierung Klassifizierungsalgorithmen verwenden, um ein Modell zu trainieren
Verwenden Sie die Klassifizierung, wenn Sie vorhersagen möchten, welcher Klasse oder Kategorie Datensätze eines Datasets ohne Labels angehören.
- Regression Regressionsalgorithmen verwenden, um ein Modell zu trainieren
Verwenden Sie die Regression, wenn Sie numerische Werte für Datensätze eines Datasets ohne Labels vorhersagen möchten.
Informationen über die spezifischen Algorithmen der Klassifizierung und der Regression erhalten Sie unter Trainingsalgorithmen.
- Klassifizierung Klassifizierungsalgorithmen verwenden, um ein Modell zu trainieren
- In der Dropdown-Liste Modell-Scorer wählen Sie die Metrik aus, die für die Einstufung der im Training erstellten Modelle verwendet werden soll.
Das erstellte Modell mit dem besten Wert für diese Metrik wird behalten, die restlichen Modelle werden gelöscht.
Eine unterschiedliche Teilmenge von Metriken ist in Abhängigkeit von Ihrem verwendeten Vorhersagetyp verfügbar:
Vorhersagetyp Verfügbare Kennzahlen Klassifizierung Kreuzentropieverlust | AUC | Korrektklassifikationsrate | F1 | Genauigkeit | Trefferquote Regression Mittlere quadratische Abweichung | Mittlerer absoluter Fehler | R2 Hinweis
Die Klassifizierungsmetrik AUC ist nur gültig, wenn sie mit einem Zielfeld verwendet wird, das binäre Daten enthält, also zwei Klassen wie Ja/Nein oder Wahr/Falsch.
Felder auswählen
- Wählen Sie aus der Liste Trainieren für ein oder mehrere Schlüsselfelder als Eingabe für das Trainieren des Modells ein.
Schlüsselfelder sind die Features, welche die Basis für die Vorhersage der Werte des Zielfelds in einem Dataset ohne Labels darstellen. Unterstützt werden Schlüsselfelder vom Typ Zeichen, numerisch, Datumzeit oder logisch. Aus Datumzeit-Feldern werden synthetische Features automatisch abgeleitet.
Hinweis
Zeichenfelder müssen Kategorien darstellen. Sie müssen also Kategorien oder Klassen identifizieren und dürfen eine maximale Anzahl eindeutiger Werte nicht überschreiten.
Der Maximalwert wird durch die Option Maximalwert der Kategorien festgelegt (Extras > Optionen > Befehl).
Tipp
Sie können mehrere, nicht angrenzende Felder auswählen, indem Sie die Steuerungstaste gedrückt halten und auf die betreffenden Felder klicken. Halten Sie die Umschalttaste gedrückt, und klicken Sie auf angrenzende Felder, um diese auszuwählen.
- Wählen Sie in der Liste Zielfeld das Zielfeld.
Das Zielfeld ist das Feld, für welches das Modell auf Basis der Eingabeschlüsselfelder Vorhersagen trainiert.
Klassifizierung und Regression funktionieren mit unterschiedlichen Zielfelddatentypen:
- Klassifizierung ein Zielfeld mit Zeichentyp oder logischem Typ
- Regression ein numerisches Zielfeld
Modelldatei und Analytics-Ausgabetabelle benennen
- Geben Sie im Textfeld Modellname den Namen der Modelldateiausgabe des Trainings ein.
Die Modelldatei beinhaltet das Modell, das für das Trainingsdataset am besten geeignet ist. Sie werden die Modelldatei als Eingabe für die Vorhersage verwenden, um Vorhersagen für neue, noch unbekannte Datasets zu erstellen.
- Im Textfeld Nach legen Sie den Namen der Modellauswertungstabelle fest, die durch das Training ausgegeben wird.
Die Modellauswertungstabelle beinhaltet zwei unterschiedliche Informationstypen:
- Scorer/Metrik Quantitative Schätzungen für die Klassifizierungs- oder Regressionsmetriken, welche Vorhersageleistung die durch das Training ausgegebene Modelldatei aufweist
- Bedeutung/Koeffizient Die Werte geben in absteigender Reihenfolge an, wie sehr jedes Feature (Vorhersage) zu den Vorhersagen des Modells beiträgt.
Hinweis
Analytics-Tabellennamen sind auf 64 alphanumerische Zeichen beschränkt, was die .FIL- Dateierweiterung nicht einbezieht. Der Name kann den Unterstrich beinhalten ( _ ), aber keine anderen Sonderzeichen oder Leerzeichen. Er kann nicht mit einer Ziffer beginnen.
-
Falls Einträge in der aktuellen Ansicht vorhanden sind, die Sie von der Verarbeitung ausschließen wollen, dann tragen Sie eine Bedingung in das Textfeld Wenn ein oder klicken Sie auf Wenn, um mittels Ausdruck-Generator eine IF-Anweisung zu erstellen.
Hinweis
Die Wenn-Bedingung wird nur für Datensätze ausgewertet, die nach Anwendung von Bereichsoptionen (Erste, Nächste, Solange) in einer Tabelle übrig sind.
Die IF-Anweisung berücksichtigt alle Datensätze in der Ansicht und filtert diejenigen heraus, die der angegebenen Bedingung nicht entsprechen.
Geben Sie an, dass lediglich eine Teilmenge des Trainingsdatasets verwendet wird (optional).
Wählen Sie in der Registerkarte weiter unter Bereich eine der Optionen aus:
| Umfangsoption | Details |
|---|---|
| Alle | (Standard) Gibt an, dass alle Datensätze in der Tabelle verarbeitet sind. |
| Erste |
Geben Sie eine Nummer in das Textfeld ein. Beginnt die Verarbeitung beim ersten Datensatz der Tabelle und bezieht nur die ausgewählte Anzahl von Datensätzen ein. |
| Nächstes |
Wählen Sie diese Option aus, und geben Sie eine Zahl in das Textfeld ein, um die Verarbeitung beim aktuell ausgewählten Datensatz der Tabellenansicht zu beginnen und nur die ausgewählte Anzahl von Datensätzen einzubeziehen. Geben Sie eine Nummer in das Textfeld ein. Beginnt die Verarbeitung beim aktuell ausgewählten Datensatz der Tabellenansicht und bezieht nur die ausgewählte Anzahl von Datensätzen ein. Es muss die tatsächliche Datensatznummer in der äußersten linken Spalte der Ansicht ausgewählt werden, nicht die Daten in der Zeile. |
| Solange |
Begrenzen Sie die zu verarbeitenden Datensätze in der Tabelle mithilfe einer WHILE-Anweisung basierend auf einem Kriterium oder mehreren Kriterien. Geben Sie eine Bedingung in das Textfeld Solange ein oder klicken sie auf Solange klicken, um mit dem Ausdruck-Generator eine WHILE-Anweisung zu erstellen. Eine WHILE-Anweisung ermöglicht, Datensätzen in der Ansicht nur dann zu verarbeiten, wenn die angegebene Bedingung als wahr bewertet wird. Sobald die Bedingung als falsch bewertet wird, wird die Verarbeitung beendet und es werden keine weiteren Datensätze verarbeitet. Sie können die Option Solange in Verbindung mit den Optionen Alle, Erste oder Nächste verwenden. Die Datensatzverarbeitung endet, sobald eine Grenze erreicht wird. |
Fortgeschrittene Einstellungen des Trainings festlegen
- In der Registerkarte Weiter geben Sie die Anzahl der Folds für Kreuzvalidierung ein.
Behalten Sie die Standardanzahl von 5 bei, oder geben Sie eine andere Zahl an. Gültige Zahlen sind 2 bis 10.
Folds sind Unterbereiche des Trainingsdatasets und werden zur Kreuzvalidierung während der Modellauswertung und -optimierung verwendet.
In der Regel werden im Modelltraining gute Ergebnisse durch die Verwendung von 5 bis 10 Folds erreicht.
Tipp
Durch eine höhere Anzahl von Folds kann die Vorhersageleistung eines Modells besser geschätzt werden. Dadurch steigt aber auch die Gesamtlaufzeit.
- Optional. Wählen Sie Grundwert und geben Sie eine Zahl ein.
Der Grundwert wird verwendet, um einen Zufallszahlen-Generator in Analytics zu initialisieren.
Wenn Sie keinen Grundwert angeben, wird Analytics den Grundwert zufällig auswählen.
Legen Sie einen Grundwert explizit fest, und speichern Sie diesen, wenn Sie das Training zukünftig mit demselben Dataset replizieren möchten.
- Optional. Wenn Sie nur lineare Modelle trainieren und einstufen möchten, wählen Sie Nur lineare Modelle auswerten.
Wenn Sie diese Option nicht auswählen, werden alle relevanten Modelltypen der Klassifizierung oder der Regression ausgewertet.
Hinweis
Bei größeren Datasets wird das Training in der Regel schneller abgeschlossen, wenn Sie nur lineare Modelle einschließen.
Wenn nur lineare Modelle einbezogen werden, sind Koeffizienten in der Ausgabe garantiert.
- Optional. Wählen Sie Feature-Auswahl und Vorverarbeitung deaktivieren, wenn Sie diese Unterprozesse vom Training ausschließen möchten.
Feature-Auswahl ist die automatische Auswahl von Feldern im Trainingsdataset, die für die Optimierung des Vorhersagemodells am nützlichsten sind. Eine automatisierte Auswahl kann die Vorhersageleistung steigern und die Datenmenge der Modelloptimierung verringern.
Die Datenvorverarbeitung führt Transformationen wie Skalierung und Standardisierung des Trainingsdatasets durch, damit dieses für die Trainingsalgorithmen besser geeignet ist.
Achtung
Sie sollten die Feature-Auswahl und die Datenvorverarbeitung nur deaktivieren, falls es dafür einen guten Grund gibt.
- Klicken Sie auf OK.
Das Training wird gestartet und ein Dialogfeld erscheint, das die festgelegten Eingabeeinstellungen und die verstrichene Verarbeitungszeit anzeigt.
Vorhersagemodelle auf Datasets ohne Labels anwenden
Hinweis
Wenn die Menüoptionen für maschinelles Lernen deaktiviert sind, ist die Python Engine wahrscheinlich nicht installiert. Weitere Informationen finden Sie unter Installieren Sie ACL für Windows.
Schritte
- Öffnen Sie die Analytics-Tabelle mit dem Trainingsdataset ohne Labels.
- Wählen Sie aus dem Analytics-Hauptmenü Maschinelles Lernen > Vorhersagen.Analytics
- Klicken Sie auf Modell. Wählen Sie dann im Dialogfeld Datei wählen eine Modelldatei aus, welche durch ein vorheriges Training ausgegeben wurde, und klicken Sie auf Öffnen.
Modelldateien besitzen eine *.model-Dateierweiterung.
Hinweis
Das Training der Modelldatei muss für ein Dataset mit denselben Feldern (oder im Wesentlichen denselben Feldern) wie dem Dataset ohne Labels stattgefunden haben.
Sie können keine Modelldatei verwenden, die in Version 14.1 von Analytics trainiert wurde. Modelldateien der Version 14.1 sind mit späteren Analytics-Versionen nicht kompatibel. Trainieren Sie ein neues Vorhersagemodell für die anstehenden Vorhersagen.
- Im Textfeld Nach legen Sie den Namen der Analytics-Tabelle fest, die durch die Vorhersage ausgegeben wird.
Die Ausgabetabelle beinhaltet die Schlüsselfelder, die Sie während des Trainings angegeben haben, sowie eines der beiden Felder, die durch die Vorhersage erstellt wurden:
- Vorhergesagt Die vorhergesagten Klassen oder numerischen Werte, die zu jedem Datensatz im Dataset ohne Labels gehören
- Wahrscheinlichkeit (nur Klassifizierung) Die Wahrscheinlichkeit, dass eine vorhergesagte Klasse genau ist
Hinweis
Analytics-Tabellennamen sind auf 64 alphanumerische Zeichen beschränkt, was die .FIL- Dateierweiterung nicht einbezieht. Der Name kann den Unterstrich beinhalten ( _ ), aber keine anderen Sonderzeichen oder Leerzeichen. Er kann nicht mit einer Ziffer beginnen.
-
Falls Einträge in der aktuellen Ansicht vorhanden sind, die Sie von der Verarbeitung ausschließen wollen, dann tragen Sie eine Bedingung in das Textfeld Wenn ein oder klicken Sie auf Wenn, um mittels Ausdruck-Generator eine IF-Anweisung zu erstellen.
Hinweis
Die Wenn-Bedingung wird nur für Datensätze ausgewertet, die nach Anwendung von Bereichsoptionen (Erste, Nächste, Solange) in einer Tabelle übrig sind.
Die IF-Anweisung berücksichtigt alle Datensätze in der Ansicht und filtert diejenigen heraus, die der angegebenen Bedingung nicht entsprechen.
- Optional. Um nur eine Teilmenge des Datasets ohne Labels zu verarbeiten, wählen Sie in der Registerkarte weiter unter Bereich eine der Optionen aus:
- Klicken Sie auf OK.
Trainingsalgorithmen
Bei drei Optionen des Trainingsbefehls ist vorgeschrieben, welche maschinellen Lernalgorithmen für das Training eines Vorhersagemodells verwendet werden:
| Option | Registerkarte des Dialogfelds „Trainieren“ |
|---|---|
| Klassifizierung oder Regression | Registerkarte Haupt |
| Nur lineare Modelle auswerten | Registerkarte Weiter |
| Feature-Auswahl und Vorverarbeitung deaktivieren | Registerkarte Weiter |
Die folgenden Abschnitte fassen zusammen, wie sich die Optionen auf die verwendeten Algorithmen auswirken.
Die Namen der Algorithmen werden in der Benutzeroberfläche von Analytics nicht angezeigt. Der Name des Algorithmus, der für die Erstellung des Modells letztendlich durch den Trainingsbefehl ausgewählt wird, ist im Protokoll angezeigt.
Hinweis
Ausführliche Informationen zu den Algorithmen finden Sie in der Dokumentation zu scikit-learn. Scikit-learn ist die von Analytics verwendete Python-Bibliothek für maschinelles Lernen.
Klassifizierungsalgorithmen
![]() Verwendeter Algorithmus
Verwendeter Algorithmus ![]() Nicht verwendeter Algorithmus
Nicht verwendeter Algorithmus
| Algorithmusname | Immer einbezogen | Nur lineare Modelle auswerten | Feature-Auswahl und Vorverarbeitung deaktivieren | ||
|---|---|---|---|---|---|
| Option nicht ausgewählt (Standard) | Option ausgewählt | Option nicht ausgewählt (Standard) | Option ausgewählt | ||
| Algorithmentyp: Klassifizierer | |||||
| Logistische Regression |
|
||||
| Lineare Support-Vektor-Maschine |
|
||||
| Random Forest |
|
|
|||
| Extrem randomisierte Bäume |
|
|
|||
| Gradient Boosting Machine |
|
|
|||
| Algorithmentyp: Feature-Präprozessor | |||||
| 1-aus-n-Code – von Features nach Kategorie |
|
||||
| Schnelle Unabhängigkeitsanalyse |
|
|
|||
| Feature-Agglomeration |
|
|
|||
| Hauptkomponentenanalyse – Singulärwertzerlegung |
|
|
|||
| Polynom-Features zweiten Grades |
|
|
|||
| Binarizer |
|
|
|||
| Robuster Scaler |
|
|
|||
| Standard-Scaler |
|
|
|||
| Maximaler absoluter Scaler |
|
|
|||
| Min-Max-Scaler |
|
|
|||
| Normalizer |
|
|
|||
| Nystroem-Kernel-Approximierung |
|
|
|||
| RBF-Kernel-Approximierung |
|
|
|||
| Nullzähler |
|
|
|||
| Algorithmentyp: Feature-Selektor | |||||
| Familien-Fehlerwahrscheinlichkeit |
|
|
|||
| Perzentil der höchsten Einstufungen |
|
|
|||
| Varianzgrenzbetrag |
|
|
|||
| Rekursive Feature-Eliminierung |
|
|
|||
| Bedeutungsgewichtungen |
|
|
|||
Regressionsalgorithmen
![]() Verwendeter Algorithmus
Verwendeter Algorithmus ![]() Nicht verwendeter Algorithmus
Nicht verwendeter Algorithmus
| Algorithmusname | Immer einbezogen | Nur lineare Modelle auswerten | Feature-Auswahl und Vorverarbeitung deaktivieren | ||
|---|---|---|---|---|---|
| Option nicht ausgewählt (Standard) | Option ausgewählt | Option nicht ausgewählt (Standard) | Option ausgewählt | ||
| Algorithmentyp: Regressor | |||||
| Elastic Net |
|
||||
| Lasso |
|
||||
| Ridge |
|
||||
| Lineare Support-Vektor-Maschine |
|
||||
| Random Forest |
|
|
|||
| Extrem randomisierte Bäume |
|
|
|||
| Gradient Boosting Machine |
|
|
|||
| Algorithmentyp: Feature-Präprozessor | |||||
| 1-aus-n-Code – von Features nach Kategorie |
|
||||
| Schnelle Unabhängigkeitsanalyse |
|
|
|||
| Feature-Agglomeration |
|
|
|||
| Hauptkomponentenanalyse – Singulärwertzerlegung |
|
|
|||
| Polynom-Features zweiten Grades |
|
|
|||
| Binarizer |
|
|
|||
| Robuster Scaler |
|
|
|||
| Standard-Scaler |
|
|
|||
| Maximaler absoluter Scaler |
|
|
|||
| Min-Max-Scaler |
|
|
|||
| Normalizer |
|
|
|||
| Nystroem-Kernel-Approximierung |
|
|
|||
| RBF-Kernel-Approximierung |
|
|
|||
| Nullzähler |
|
|
|||
| Algorithmentyp: Feature-Selektor | |||||
| Familien-Fehlerwahrscheinlichkeit |
|
|
|||
| Perzentil der höchsten Einstufungen |
|
|
|||
| Varianzgrenzbetrag |
|
|
|||
| Bedeutungsgewichtungen |
|
|
|||