Les doublons approximatifs sont des valeurs de type caractère quasiment identiques faisant référence à la même entité réelle. Par exemple, les quatre valeurs suivantes peuvent désigner la même entreprise :
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intrecity Couriers
Les causes courantes des doublons approximatifs sont les erreurs de saisie de données comme les fautes typographiques et d'orthographe, des méthodes de mise en forme des données différentes et des conventions de saisie de données différentes. Une création volontaire de valeurs quasiment identiques peut révéler une fraude. Les doublons approximatifs impliquent une analyse de données qui repose sur des données faisant référence de manière cohérente à des entités réelles.
Doublons approximatifs et jointures approximatives
La fonctionnalité de doublons approximatifs analyse les valeurs d'un seul champ dans une seule table Analytics. Pour utiliser les correspondances approximatives afin de combiner des champs de deux tables Analytics dans une nouvelle troisième table, reportez-vous à la rubrique Jointure approximative.
Fonctionnement
La fonction de doublons approximatifs dans Analytics vous permet de tester un champ caractère spécifique dans une table pour identifier les doublons approximatifs contenus dans le champ. Les résultats de sortie regroupent les doublons approximatifs en fonction d'un niveau de différence que vous spécifiez. En ajustant le niveau de différence, vous pouvez contrôler le nombre et la taille des groupes de sortie et la quantité de différence entre les membres du groupe.
Pour confirmer si les membres du groupe de doublons approximatifs font effectivement référence à la même entité réelle, vous devrez peut-être effectuer des analyses supplémentaires, comme un test de doublons sur des champs autres que le champ test.
Remarque
La recherche de doublons approximatifs est un processus plus avancé que l'identification des doublons exacts. La connaissance des paramètres qui commandent le degré de différence entre les doublons et du regroupement des doublons approximatifs dans les résultats de sortie permet d'optimiser l'utilisation de la fonction.
Résultats de sortie de doublons approximatifs
L'exemple ci-après présente les résultats de sortie générés par la recherche de doublons approximatifs dans le champ Nom d'une table.
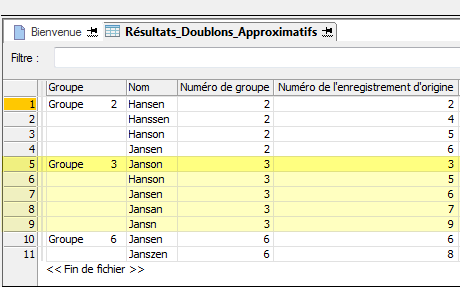
Les résultats de sortie sont organisés en groupes identifiés sous les chiffres 2, 3 et 6. Le Numéro de l'enregistrement d'origine du premier doublon approximatif de chaque groupe permet d'identifier le groupe. Par exemple, Janson est le nom de l'enregistrement numéro 3 de la table d'origine et, comme Janson est également la première valeur du groupe basé sur la séquence d'enregistrement de la table d'origine, le groupe est identifié comme étant le Groupe 3. Pour plus d'informations, consultez la section Regroupement des doublons approximatifs.
La fonction de doublons approximatifs utilise une comparaison basée sur le caractère
Lors de la comparaison de deux valeurs, la fonction de doublons approximatifs effectue une comparaison basée sur le caractère et non sur le mot. La fonction gère les blancs ou les espaces entre les mots comme des caractères et ne différencie pas chaque mot. Quel que soit le nombre de mots dans une valeur, la fonction gère la valeur comme une chaîne de caractères unique et ininterrompue.
Cette approche implique que certaines valeurs considérées comme des doublons approximatifs pour l’œil humain peuvent ne pas apparaître dans les résultats de sortie en fonction de la nature des données et des paramètres de différence spécifiés dans la boîte de dialogue Doublons approximatifs.
Exemple
Prenez ces noms :
- JW Smith et John William Smith
- Diamond Tire et Diamond Tire & Auto
Le premier exemple peut représenter deux versions du même nom, l'une utilisant des initiales et l'autre utilisant le prénom et second prénom en toutes lettres. Le second exemple peut représenter la version abrégée et la version développée d'un nom d'entreprise.
Aucune de ces paires de noms ne sera considérée comme un doublon approximatif sauf si les paramètres de différence sont relativement faibles, produisant ainsi l'effet inverse, c'est-à-dire renvoyer un grand nombre de faux positifs.
La fonction de doublons approximatifs traite simplement chaque paire de noms ci-dessous comme deux chaînes de caractères. Dans chaque cas de figure, étant donné que la différence de longueur des deux chaînes est significative, la différence entre ces chaînes au niveau du caractère est importante.
Pour plus d'informations, consultez la section Application des paramètres de différence.
Améliorer l'efficacité de l'analyse des doublons approximatifs
Outre l'utilisation de la fonction principale de doublons approximatifs, vous devrez peut-être limite la taille du jeu de données test, utiliser les fonctions d'aide des doublons approximatifs ou concaténer des champs de test afin d'atteindre vos objectifs.
Le tableau ci-dessous résume les différentes techniques permettant d'améliorer l'efficacité de l'analyse des doublons approximatifs.
Pour plus d'informations sur les fonctions d'aide, consultez la rubrique Fonctions d'aide des doublons approximatifs.
|
Technique |
Fonction Analytics |
Détails |
|---|---|---|
|
Limiter la taille de l'ensemble de données à tester |
Filtres Extraction de sous-ensembles de données |
Réduisez la durée d'exécution en ne traitant que les enregistrements pertinents pour votre analyse |
| Trier les éléments individuels dans les valeurs des champs tests |
Fonction SORTWORDS( ) |
Réduisez la taille et augmentez la précision des résultats en minimisant l'importance de la position physique des éléments individuels dans les valeurs tests Remarque Bien que la fonction de doublons approximatifs utilise une comparaison basée sur les caractères, le tri des mots ou des éléments dans des valeurs de test présente l'avantage d'aligner plus étroitement les caractères entre les chaînes comparées. |
|
Supprimer des éléments génériques des valeurs des champs tests |
Fonction OMIT( ) |
Réduire la taille et améliorer la précision des résultats en ciblant uniquement la portion des valeurs de test où des différences significatives sont possibles |
|
Concaténer des champs pour augmenter l'unicité des valeurs de test |
Une expression Analytics utilisant l'opérateur d'addition (+) |
Réduire la taille et augmenter la précision des résultats en testant des valeurs d'unicité supérieure, qui sont générées en concaténant deux champs ou plus |
|
Générer une liste unique et exhaustive de doublons approximatifs pour une valeur spécifique dans les résultats de sortie des doublons approximatifs |
Fonction ISFUZZYDUP( ) |
Générer une liste de doublons approximatifs pratique et exhaustive pour une valeur de sortie particulièrement utile pour votre travail d'analyse |
Dois-je trier le champ test ?
La recherche de doublons approximatifs dans un champ n'exige pas que celui-ci soit trié. Trier une table en fonction du champ test avant le test n'augmente en aucune façon l'efficacité de l'opération de doublons approximatifs. Toutefois, vous pouvez choisir de trier un champ de test à l'avance afin de simplifier l'analyse des résultats de sortie et parce que la boîte de dialogue Doublons approximatifs ne contient pas l'option Prétrier.
Remarque
Bien que le tri des valeurs des champs tests n'augmente pas l'efficacité, trier des éléments individuels dans les valeurs des champs comportant plusieurs éléments, comme des adresses, peut augmenter considérablement l'efficacité. Pour plus d'informations, consultez la section Fonctions d'aide des doublons approximatifs.
Inclusion des doublons exacts
Lors de la recherche de doublons approximatifs, vous pouvez éventuellement inclure les doublons exacts dans les résultats de sortie. Si vous souhaitez rechercher des doublons exacts uniquement, utilisez la fonction de doublons. Pour plus d'informations, consultez la section Recherche de doublons.