Information de concept
Une jointure approximative Analytics utilise la jointure approximative des valeurs de champs clés pour combiner deux tables Analytics dans une nouvelle troisième table. À tous les égards, une jointure approximative ressemble à une jointure Analytics ordinaire (voir Jonction de tables). La principale différence, c'est qu'en plus de joindre des enregistrements à partir de la correspondance exacte des valeurs de champs clés, une jointure approximative peut joindre des enregistrements à partir d'une correspondance approximative.
Une jointure approximative s'avère utile lorsque les clés primaires et secondaires contiennent le même type de données, mais sous une forme légèrement différente. Ou bien lorsque les données des clés présentent de légères irrégularités, comme des fautes de frappe, qui peuvent empêcher l'existence d'une correspondance exacte.
Exemple
Scénario
Vous voulez identifier les fournisseurs qui sont également des employés via une seule méthode d'analyse des données afin de trouver d'éventuels paiements incorrects.
Approche
Vous joignez la table maître Fournisseurs à la table maître Employés à l'aide du champ adresse dans chaque table comme clé commune (Rue_Fournisseur et Adresse_Emp). Toutefois, la forme des données d'adresse dans les champs clés varie légèrement ; ainsi, vous utilisez une jointure approximative au lieu d'une jointure ordinaire.
Regardons certaines données
Sans un important travail de nettoyage et d'harmonisation des données, les valeurs clés primaires et secondaires indiquées ci-dessous ne seraient pas jointes par une jointure Analytics ordinaire, même s'il s'agit très probablement d'adresses correspondantes.
| Valeurs clés primaires | Valeurs clés secondaires |
|---|---|
| 605, 3e Avenue | 605, troisième avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
Même avec le nettoyage et l'harmonisation des données, les valeurs clés présentant des différences orthographiques mineures, telles que « Rowan » et « Rowen », ne seraient probablement pas correspondantes.
Les valeurs clés peuvent être jointes par une jointure approximative, en fonction des paramètres de jointure approximative.
Résultats de sortie
Dans l'exemple de table jointe ci-dessous, les correspondances exactes des champs clés sont surlignées en violet et les correspondances approximatives des champs clés sont surlignées en vert.
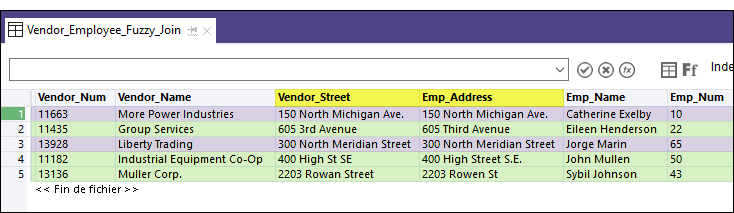
Jointures approximatives et doublons approximatifs
Une jointure approximative analyse les valeurs des champs clés dans deux tables. Pour rechercher des valeurs quasi-identiques dans un champ unique dans une seule table Analytics, consultez la section Analyse de doublons approximatifs.
Améliorer l'efficacité des jointures approximatives
Vous pouvez sensiblement améliorer l'efficacité des jointures approximatives en incorporant une ou plusieurs des techniques suivantes :
- trier les éléments individuels dans les valeurs des champs clés primaires et secondaires
- supprimer les éléments génériques des valeurs des champs clés primaires et secondaires
- harmoniser les valeurs des champs clés primaires et secondaires
Ces techniques vous permettent d'utiliser des paramètres approximatifs plus stricts et d'obtenir toujours les mêmes correspondances approximatives, tout en réduisant le nombre de fausses correspondances positives. Vous pouvez utiliser ces techniques séparément ou en combinaison.
Créer une expression ou un champ calculé
Pour utiliser une ou plusieurs de ces techniques, vous devez créer une expression ou un champ calculé à l'aide de la fonction Analytics appropriée et à l'aide d'un ou des deux champs clés.
Pour plus d'informations sur les expressions, consultez la section Utilisation d'expressions.
Pour plus d'informations sur les champs calculés, consultez la rubrique Champs calculés.
Remarque
La boîte de dialogue Jointure approximative ne permet pas la création d'une expression sur un champ clé secondaire. Cependant, vous pouvez créer manuellement une expression de champ clé secondaire dans la ligne de commande Analytics ou dans un script. Une autre option consiste à créer un champ calculé qui sera utilisé comme champ clé secondaire.
Trier les éléments individuels dans les valeurs des champs clés
La fonction SORTWORDS( ) peut améliorer l'efficacité des jointures approximatives en triant les éléments individuels des valeurs des champs clés primaires et secondaires dans un ordre séquentiel.
Trier des éléments, comme les composantes d'une adresse, permet de faire en sorte que des valeurs de champs clés comportant les mêmes informations, mais à un format différent, se ressemblent davantage. Une ressemblance plus proche améliore la probabilité que des valeurs de champs clés soient sélectionnées comme correspondances approximatives les unes des autres.
Pour plus d'informations, consultez la section Fonction SORTWORDS( ).
Pour une vidéo de présentation de SORTWORDS( ), consultez Correspondance approximative avec SORTWORDS() (en anglais uniquement).
Remarque
Le tri des éléments dans les valeurs des champs clés est le mieux adapté aux jointures approximatives en utilisant l'algorithme de distance Levenshtein.
Le tri des éléments pendant les jointures approximatives à l'aide de l'algorithme du coefficient de Dice peut être avantageux ou non. Tester un jeu de données d'échantillon avant de décider d'utiliser SORTWORDS( ) conjointement avec l'algorithme du coefficient de Dice dans un cadre de production.
Attention
Si vous utilisez SORTWORDS( ) conjointement avec les jointures approximatives, vous devez appliquer SORTWORDS( ) aux deux chaînes de caractères ou aux deux champs comparés.
Suppression des éléments génériques des valeurs des champs clés
La fonction OMIT( ) peut améliorer l'efficacité de la jointure approximative en supprimant des éléments génériques tels que « Corporation » ou « Inc. » ou des caractères comme les virgules, les points et les esperluettes (&) dans les valeurs des champs clés primaires et secondaires.
La suppression d'éléments génériques et de ponctuation recentre la correspondance approximative des valeurs de champs clés uniquement sur la portion des valeurs dans lesquelles une différence significative peut se présenter.
Pour plus d'informations, consultez la section Fonction OMIT( ).
Harmoniser les valeurs des champs clés
Les fonctions REPLACE( ) ou REGEXREPLACE( ) peuvent améliorer l'efficacité des jointures approximatives en harmonisant les formes variantes d'un même élément dans les valeurs des champs clés primaires et secondaires. Par exemple, vous pourriez harmoniser "Street", "St." et "St" pour utiliser la valeur unique "St".
Harmoniser des éléments permet de faire en sorte que des valeurs de champs clés comportant les mêmes informations, mais à un format différent, se ressemblent davantage. Une ressemblance plus proche améliore la probabilité que des valeurs de champs clés soient sélectionnées comme correspondances approximatives les unes des autres.
Pour plus d'informations, consultez Fonction REPLACE( ) concernant les remplacements directs et Fonction REGEXREPLACE( ) concernant les remplacements plus complexes.
Taille de la table de sortie et performances des commandes
Taille de la table de sortie
La jointure approximative est similaire à la jointure plusieurs-à-plusieurs Analytics. Toutes les valeurs clés primaires peuvent potentiellement correspondre à toutes les valeurs clés secondaires. La taille de la table de sortie peut être beaucoup plus grande que la taille des tables d'entrée primaire ou secondaire.
Performances des commandes
Les algorithmes de correspondance approximative permettent de s'assurer que seules les valeurs clés d'un certain degré d'approximation, ou que seules les valeurs correspondantes exactement, sont effectivement jointes. Cependant, chaque correspondance primaire-secondaire possible doit être testée, ce qui signifie que le processus de correspondance approximative peut prendre beaucoup de temps. Le nombre de tests individuels à effectuer est égal au nombre d'enregistrements de la table primaire multiplié par le nombre d'enregistrements de la table secondaire.
Limiter le rapprochement à la première correspondance secondaire
Vous pouvez réduire considérablement le temps de traitement et la taille des résultats de sortie en cochant l'option Joindre uniquement la première occurrence des correspondances de clés secondaires. L'activation de cette option spécifie que chaque valeur de clé primaire n'est jointe qu'à la première occurrence de valeurs de clé secondaire correspondantes.
L'activation de cette option est appropriée dans l'une ou l'autre de ces situations :
- Des correspondances ? vous voulez seulement savoir s'il existe des correspondances, exactes ou approximatives, entre deux tables, et vous souhaitez éviter le temps de traitement nécessaire pour identifier toutes les correspondances.
- Au plus une correspondance vous êtes certain qu'il n'existe qu'une seule correspondance dans la table secondaire pour chaque valeur de clé primaire.
L'activation de cette option n'est pas appropriée si vous avez besoin de résultats de sortie qui contiennent toutes les jointures possibles entre les valeurs de clés primaires et secondaires.
Remarque
Si vous sélectionnez Joindre uniquement la première occurrence des correspondances de clés secondaires et s'il se trouve que la première occurrence est une correspondance exacte, les correspondances approximatives suivantes pour la valeur de clé primaire ne sont pas incluses dans la table de sortie jointe.
Méthodes conseillées
Gardez à l'esprit la taille de la table de sortie et la performance des commandes lorsque vous préparez des tables d'entrée primaires et secondaires, et précisez le degré d'approximation.
- Adapter les données Assurez-vous que seuls les enregistrements pertinents sont inclus dans les tables primaires et secondaires. Si certains enregistrements n'ont aucune chance de correspondre, filtrez-les avant d'effectuer des correspondances approximatives.
- Exécution de tests Pour les grands jeux de données, lancez des tests sur une petite partie des données afin d'obtenir plus efficacement des paramètres appropriés pour les algorithmes de correspondance approximative. Commencez par des paramètres de correspondances approximatives plus prudents et, si nécessaire, assouplissez-les progressivement.
Algorithmes de correspondances approximatives
Lorsque vous effectuez une jointure approximative, vous pouvez choisir entre deux algorithmes différents de correspondances approximatives :
- Coefficient de Dice
- Distance Levenshtein
Les algorithmes fonctionnent indépendamment les uns des autres et peuvent produire des résultats quelque peu différents. Une méthode consiste à effectuer une jointure approximative deux fois, une fois avec chaque algorithme, et à comparer les résultats. Généralement, un certain nombre de correspondances approximatives dans chaque jeu de résultats se chevauche, mais certaines correspondances peuvent être propres à chaque jeu de résultats.
Degré d'approximation
Vous spécifiez le degré d'approximation pour chaque algorithme, ce qui peut modifier considérablement la taille et la composition du jeu de résultats. Le « degré d'approximation » fait référence à la mesure dans laquelle deux valeurs correspondent étroitement.
Selon l'algorithme que vous sélectionnez, vous utilisez les options suivantes pour contrôler le degré d'approximation :
| Algorithme | Paramètre |
|---|---|
|
Coefficient de Dice |
|
|
Distance Levenshtein |
|
Essayez de tester différents degrés d'approximation. Commencez prudemment et produisez des ensembles de résultats plus petits, puis assouplissez progressivement les paramètres jusqu'à ce que vous commenciez à obtenir trop de valeurs jointes qui ne correspondent évidemment pas (faux positifs).
Coefficient de Dice
L'algorithme du coefficient de Dice fonctionne en mesurant le degré de similitude entre une valeur clé primaire et une valeur clé secondaire, sur une échelle de 0,0000 à 1,0000. Plus le coefficient de Dice des deux valeurs est élevé, plus elles sont similaires.
| Coefficient de Dice | Signification |
|---|---|
| 1,0000 |
Chaque valeur est composée d'un jeu de caractères identique, bien que les caractères puissent être présentés dans un ordre différent et utiliser une casse différente. Les n-grammes dans les deux valeurs sont identiques à 100 %. Les N-grammes sont expliqués ci-dessous. |
| 0,7500 |
Les n-grammes dans les deux valeurs sont identiques à 75 %. |
| 0,0000 | Les deux valeurs ne présentent pas de n-grammes identiques, ou la longueur spécifiée dans le paramètre N-grammes est plus longue que la plus courte des deux valeurs comparées. |
N-grammes
Le coefficient de Dice est calculé en divisant d'abord les valeurs à comparer en n-grammes. Les N-grammes sont des blocs de caractères qui se chevauchent, d'une longueur n, qui correspond à la longueur que vous spécifiez dans le paramètre N-grammes.
Voici deux des valeurs de l'exemple ci-dessus, divisées en n-grammes de 2 caractères (n = 2).
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
|---|---|
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
Le coefficient de Dice représente le pourcentage du nombre total de n-grammes dans les deux valeurs qui sont identiques. Dans ce cas, 20 des 28 n-grammes sont identiques, soit 71,43 %, ou 0,7143 exprimé sous forme décimale.
Remarque
Augmenter la longueur dans le paramètre n-grammes rend encore plus strict le critère de similarité entre deux valeurs.
Pourcentage
Lorsque vous spécifiez un paramètre Pourcentage, vous spécifiez le coefficient de Dice minimum autorisé de deux valeurs pour qu'elles puissent être qualifiées de correspondance approximative. Par exemple, si vous spécifiez 0,7500, cela signifie qu'au moins 75 % des n-grammes de deux valeurs doivent être identiques pour créer une correspondance.
| Paramètre Pourcentage | Signification | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0,7500 |
Pour qu'il y ait correspondance approximative, au moins 75 % des n-grammes de deux valeurs doivent être identiques. |
Sans correspondance, ne figure pas dans la table jointe (coefficient de Dice = 0,7143) |
| 0,7000 |
Pour qu'il y ait correspondance approximative, au moins 70 % des n-grammes de deux valeurs doivent être identiques. |
Correspondance, figure dans la table jointe (coefficient de Dice = 0,7143) |
Pour des informations détaillées sur le fonctionnement du coefficient de Dice, consultez la section Fonction DICECOEFFICIENT( ).
Distance Levenshtein
L'algorithme de distance Levenshtein fonctionne en mesurant le degré de différence existant entre une valeur clé primaire et une valeur clé secondaire, sur une échelle de nombres entiers commençant à 0. L'échelle représente le nombre de modifications d'un caractère unique requises pour rendre une valeur identique à une autre valeur. Plus la distance Levenshtein est grande entre les deux valeurs, plus la différence entre ces dernières est importante.
| Distance Levenshtein | Signification |
|---|---|
| 0 | Chaque valeur est composée d'un ensemble de caractères identiques, dans un ordre identique. La casse peut différer. |
| 2 |
Deux modifications à un seul caractère sont nécessaires pour que les deux valeurs soient identiques. Par exemple : "Smith" et "Smythe"
|
| 3 |
Trois modifications à un seul caractère sont nécessaires pour que les deux valeurs soient identiques. Par exemple : "Hanssen" et "Jansn"
|
Distance
Lorsque vous spécifiez un paramètre Distance, vous spécifiez la distance Levenshtein maximale permise entre deux valeurs pour qu'elles puissent être qualifiées de correspondance approximative. Par exemple, si vous spécifiez 2, cela signifie qu'un maximum de deux modifications peut être nécessaire pour rendre deux valeurs identiques.
| Paramètre Distance | Signification | Hanssen / Jansn |
|---|---|---|
| 2 |
Pour qu'il y ait correspondance approximative, 2 modifications de caractères au maximum peuvent être nécessaires pour rendre deux valeurs identiques. |
Sans correspondance, ne figure pas dans la table jointe (Distance Levenshtein = 3) |
| 3 |
Pour qu'il y ait correspondance approximative, 3 modifications de caractères au maximum peuvent être nécessaires pour rendre deux valeurs identiques. |
Correspondance, figure dans la table jointe (Distance Levenshtein = 3) |
Pour obtenir des informations détaillées sur le fonctionnement de la distance Levenshtein, consultez la section Fonction LEVDIST( ). Contrairement à la fonction, l'algorithme de la distance Levenshtein utilisé dans la jointure approximative tronque automatiquement les espaces de début et de fin, et n'est pas sensible à la casse.
Étapes
Vous pouvez utiliser la jointure approximative des valeurs de champs clés pour combiner deux tables Analytics dans une nouvelle troisième table.
- Dans le navigateur, ouvrez la table principale et cliquez avec le bouton droit de la souris sur la table secondaire puis sélectionnez Ouvrir en tant que secondaire.
Les icônes des tables principale et secondaire sont mises à jour avec les numéros 1 et 2 pour indiquer leur relation l'une à l'autre

 .
. - Sélectionnez Données > Jointure approximative.
- Dans l'onglet Principal, sélectionnez l'algorithme de correspondances approximatives que vous souhaitez utiliser :
- Coefficient de Dice
- Levenshtein
- Selon l'algorithme que vous avez sélectionné, indiquez des paramètres pour contrôler le degré d'approximation.
Coefficient de Dice
- N-grammes
- Pourcentage
Levenshtein
- Distance
Les paramètres sont expliqués ci-dessous.
- (facultatif) Sélectionnez Joindre uniquement la première occurrence des correspondances de clés secondaires pour spécifier que chaque valeur de clé primaire n'est jointe qu'à la première occurrence d'une valeur de clé secondaire correspondante.
- Sélectionnez le champ clé primaire dans la liste Clés primaires.
Vous pouvez sélectionner uniquement un seul champ de clé primaire, et il doit être de type caractère.
- Sélectionnez le champ clé secondaire dans la liste Clés secondaires.
Vous pouvez sélectionner uniquement un seul champ de clé secondaire, et il doit être de type caractère.
- Sélectionnez les champs à inclure dans la table jointe depuis les listes Champs primaires et Champs secondaires.
Remarque
Vous devez sélectionner de manière explicite les champs clés primaires et secondaires si vous voulez les intégrer dans la table jointe.
Astuce
Vous pouvez utiliser la combinaison Ctrl+clic pour sélectionner plusieurs champs non adjacents, et Maj+clic pour sélectionner plusieurs champs adjacents.
- Dans la zone de texte Vers, indiquez le nom de la nouvelle table jointe.
- (Facultatif) Dans l'onglet Plus :
- Si vous souhaitez traiter uniquement un sous-ensemble d'enregistrements, sélectionnez une des options du panneau Étendue.
- Si vous voulez concaténer (ajouter) les résultats de sortie à la fin d'une table Analytics existante, sélectionnez Ajouter au fichier existant.
- Cliquez sur OK.
La nouvelle table jointe est sortie.
Options de la boîte de dialogue Jointure approximative
Les tableaux ci-dessous fournissent des informations détaillées sur les options disponibles dans la boîte de dialogue Jointure approximative.
Onglet Principal
| Options – Boîte de dialogue Jointure approximative | Description |
|---|---|
| Coefficient de Dice |
Utilisez le coefficient de Dice pour des correspondances approximatives entre des valeurs clés primaires et secondaires.
|
| Levenshtein |
Utilisez la distance Levenshtein pour une correspondance approximative entre les valeurs clés primaires et secondaires.
|
| Joindre uniquement la première occurrence des correspondances de clés secondaires |
Spécifie que chaque valeur de clé primaire n'est jointe qu'à la première occurrence d'une correspondance de clé secondaire. Si vous laissez l'option non cochée, le comportement par défaut consiste à joindre chaque valeur de clé primaire à toutes les occurrences des correspondances de clés secondaires. |
| Table secondaire | Une méthode alternative pour sélectionner la table secondaire. |
| Clés primaires Clés secondaires |
Indique le champ clé commun à utiliser pour joindre les deux tables.
Instructions relatives aux champs clés :
|
| Champs primaires Champs secondaires |
Indique les champs à inclure dans la table jointe.
|
| Utiliser la table de sortie | Indique si la table Analytics qui contient les résultats de sortie s'ouvre automatiquement dès la fin de l'opération. |
| Si |
(Facultatif) Vous permet de créer une condition pour exclure les enregistrements du traitement.
|
| Vers | Indique le nom et l'emplacement de la table de sortie.
Indépendamment de l'emplacement dans lequel vous enregistrez la table de sortie, cette dernière est ajoutée au projet ouvert si elle ne s'y trouve pas déjà. Si Analytics prérenseigne le nom de la table, vous pouvez l'accepter ou le modifier. |
Onglet Plus
| Options – Boîte de dialogue Jointure approximative | Description |
|---|---|
| Panneau étendue | Indique quels enregistrements de la table primaire sont traités :
Remarque Le nombre d'enregistrements indiqué dans les options Premiers ou Suivants fait référence à l'ordre physique ou d'indexation des enregistrements dans une table, quels que soient les filtres ou les tris express appliqués à la vue. Toutefois, les résultats des opérations analytiques tiennent compte de tous les filtres appliqués. Si un tri express est appliqué à une vue, l'option Suivant se comporte comme l'option Premier. |
| Ajouter au fichier existant | Indique que les résultats édités sont ajoutés à la fin de la table Analytics existante. Remarque Nous vous conseillons de ne pas sélectionner Ajouter au fichier existant si vous avez un doute quant aux résultats de sortie et si la table disponible a une structure de données identique. Pour plus d’informations sur l'ajout des résultats et la structure des données, consultez la section Concaténation de résultats de sortie dans une table existante. |
| OK | Exécute l'opération.
|