Muestreo de variables clásicas
El muestreo de variables clásicas es un método de muestreo estadístico para calcular lo siguiente:
- el valor auditado total de una cuenta o clase de transacciones
- el importe total de la información errónea monetaria en una cuenta o clase de transacciones
El muestreo de variables clásicas funciona mejor con datos financieros que tengan las siguientes características:
|
una cantidad moderada a elevada de información errónea Por ejemplo, se informan incorrectamente 5 % o más elementos. |
| es posible que existan tanto sobrestimaciones como subestimaciones |
| es posible que existan valores de cero en dólares |
Consejo
Para ver una introducción práctica del proceso de muestreo de variables clásicas completo en Analytics, consulte Tutorial de muestreo de variables clásicas.
Nota
Además de los datos financieros, puede usar el muestreo de variables clásicas con cualquier dato numérico que tenga una característica variable; por ejemplo, cantidad, unidades de tiempo u otras unidades de medida.
Cómo funciona
El muestreo de variables clásicas le permite seleccionar y analizar un pequeño subconjunto de registros de una cuenta y, sobre la base del resultado, calcular el valor auditado total de la cuenta y el importe total de información errónea monetaria.
Las estimaciones se calculan como intervalos:
- La estimación puntual es el punto medio del intervalo.
- El límite superior y el límite inferior son los dos puntos extremos del intervalo.
También puede optar por calcular un intervalo o una estimación hacia un solo extremo, con una estimación puntual y únicamente un límite superior o únicamente un límite inferior.
Usted compara el intervalo estimado con el valor contable de la cuenta o con el importe de información errónea que usted considera trascendente y toma una determinación respecto de la cuenta.
El muestreo de variables clásicas permite hacer este tipo de declaración:
- Existe un 95 % de probabilidades de que el valor auditado real de la cuenta esté entre 45.577.123,95 y 46.929.384,17, un intervalo que contiene el valor contable de la cuenta que es 46.400.198,71. Por lo tanto, los importes de la cuenta se consideran razonablemente precisos.
- Hay un 95 % de probabilidades de que la información errónea en el saldo de la cuenta se encuentre entre – 813.074,76 y 539.185,46; lo cual no supera la precisión monetaria de ±928.003,97. Por lo tanto, los importes de la cuenta se consideran razonablemente precisos.
Descripción general del proceso de muestreo de variables clásicas
¡Precaución!
No saltee el cálculo de un tamaño de muestra válido.
Si pasa directamente a extraer una muestra de registros y no calcula el tamaño de la muestra, es altamente probable que la proyección de los resultados de su análisis no sea válida y que su conclusión final sea errónea.
El proceso de muestreo de variables clásicas incluye los siguientes pasos generales:
- Preparar (planificar) la muestra de variables clásicas
- Extraer la muestra de los registros
- Realizar los procedimientos de auditoría deseados en los datos de muestra.
- Evaluar lo siguiente:
- si el valor auditado de los datos de los que se extrae la muestra, al ser proyectado a la totalidad de la cuenta, cae dentro de un rango aceptable del valor contable registrado
- si los niveles observados de información monetaria errónea representan un grado de error aceptable o inaceptable en la totalidad de la cuenta
Limitación de la longitud de los números
Durante la etapa de preparación del muestreo de variables clásicas, se realizan varios cálculos internos. Estos cálculos admiten números con una longitud máxima de 17 dígitos. Si el resultado de algún cálculo supera los 17 dígitos, no se lo incluye en la salida y usted no puede continuar con el proceso de muestreo.
Tenga en cuenta que los números de datos de origen con menos de 17 dígitos pueden generar un cálculo interno cuyo resultado supere los 17 dígitos.
Los valores se conservan y se completan automáticamente entre las etapas
Cuando utiliza Analytics para el muestreo de variables clásicas, usted introduce información en tres cuadros de diálogo independientes y ejecuta los comandos asociados, en este orden:
- Cuadro de diálogo CVS Preparar
- Cuadro de diálogo CVS Muestra
- Cuadro de diálogo CVS Evaluar
Al avanzar en el proceso, la información de un cuadro de diálogo se coloca automáticamente en el cuadro de diálogo siguiente. Esto ahorra trabajo y elimina el riesgo de introducir erróneamente valores incorrectos e invalidar la muestra.
Consideraciones importantes
- Cambio de los valor autocompletadosen general, no debe cambiar ninguno de los valores autocompletados. Si cambia los valores autocompletados, puede negar la validez estadística del proceso de muestreo.
Precaución
Actualice los valores autocompletados únicamente si tiene conocimientos de estadística como para comprender el efecto del cambio.
-
Almacenamiento temporal de los valores los valores que se autocompletan en los cuadros de diálogo CVS Muestra y CVS Evaluar solo se almacenan temporalmente y se los elimina al cerrar el proyecto de Analytics.
Pautas
Siga estas pautas para realizar el proceso completo sin interrupciones:
- No cierre el proyecto de Analytics entre las etapas CVS Preparar y CVS Muestra.
Consejo
Si cierra el proyecto, puede restaurar los valores temporales de CVS volviendo a introducir la información necesaria en el cuadro de diálogo CVS Preparar o volviendo a ejecutar el comando CVSPREPARE desde el log.
- Opcional. Después de ejecutar CVS Preparar y CVS Muestra, guarde los comandos en un script. Puede copiar los comandos desde la visualización de la salida o desde el log.
También puede copiar la versión preliminar del comando CVSEVALUATE que se incluye en la salida de CVS Muestra.
Si es necesario, puede volver a ejecutar uno o más comandos CVS desde el script. Escriba COMMENT antes de cualquier comando que no desee ejecutar. Usted probablemente necesitará actualizar la versión preliminar del comando CVSEVALUATE. Si desea obtener más información, consulte Realización del muestreo de variables clásicas.
Estratificación
El muestreo de variables clásicas le da la opción de estratificar numéricamente los registros de una población antes de extraer una muestra.
El beneficio de la estratificación es que con frecuencia reduce drásticamente el tamaño necesario de la muestra mientras que mantiene la validez estadística. Si el tamaño de muestra es reducido, se necesita menos trabajo de análisis de datos para alcanzar un objetivo.
Cómo funciona
La estratificación funciona dividiendo la población en una cantidad de subgrupos, o niveles, denominados estratos. Lo ideal es que los valores de cada estrato sean relativamente homogéneos.
Un algoritmo estadístico (el método de Neyman) establece los límites entre los estratos. El algoritmo fija los límites con el fin de minimizar la dispersión de los valores de cada estrato, lo cual reduce el efecto de la varianza de la población. Al reducir la varianza, o 'dispersión', se reduce el tamaño necesario de la muestra. Por diseño, el rango de cada estrato no es uniforme.
Por eso, la cantidad de muestras necesarias se calcula estrato por estrato y se totaliza en lugar de calcularse para toda la población sin estratificar. Para el mismo conjunto de datos, el enfoque estratificado suele requerir un tamaño de muestra más pequeño que el enfoque no estratificado.
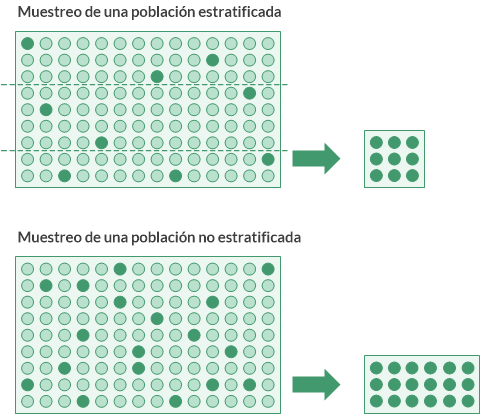
Pre-estratificación con el uso de celdas
Como parte del proceso de estratificación, usted especifica la cantidad de celdas que se deben utilizar para estratificar la población. Las celdas son divisiones numéricas uniformes más estrechas que los estratos.
Un algoritmo estadístico utiliza el recuento de los registros de cada celda como parte del cálculo que asigna los límites óptimos de los estratos. Las celdas no se conservan en la salida estratificada final.
Como mínimo, la cantidad de celdas especificadas debe ser el doble de la cantidad de estratos especificados.
Nota
Las celdas de preestratificación y las celdas que se utilizan en el método de selección de muestras por celdas no son lo mismo.
Exceso de algo positivo
La estratificación es una herramienta potente para manejar el tamaño de las muestras, pero debe tener cuidado al especificar la cantidad de estratos y la cantidad de celdas.
Como punto de partida, intente lo siguiente:
- 4 a 5 estratos
- 50 celdas
Después de cierto punto, el incremento del número de estratos tiene un efecto mínimo o nulo sobre el tamaño de la muestra Sin embargo, este incremento puede afectar de forma negativa el diseño de la muestra o el desempeño de Analytics al estratificar grandes conjuntos de datos.
En lo que concierne al diseño de las muestras, al alcanzar la etapa de evaluación, es necesario contar con una cantidad mínima de información errónea en cada estrato para proyectar de forma confiable esos errores a toda la población. Si tiene demasiados estratos en relación a la cantidad de información errónea, pueden surgir problemas en el momento de la proyección.
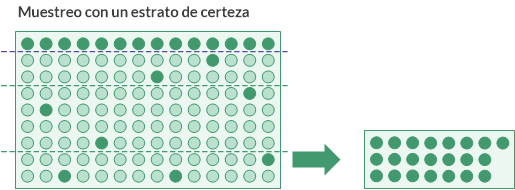
El estrato de certeza
Otra opción de estratificación disponible consiste en definir un estrato de certeza.
El uso de un estrato de certeza tiene dos ventajas:
- Los elementos individualmente significativos o los elementos de valor elevado se incluyen automáticamente en la muestra y no existe riesgo de que sean excluidos por el método de selección aleatoria.
- Los elementos del estrato de certeza se quitan del cálculo del tamaño de la muestra. Por su naturaleza, si los elementos de valor elevado se incluyen en el cálculo, pueden incrementar la varianza de la población y el tamaño de muestra necesario.
Definición de un estrato de certeza
Para definir un estrato de certeza, usted debe especificar un valor de corte numérico. Todos los valores contables de los campos clave que sean mayores o iguales al valor de corte se seleccionan automáticamente y se incluyen en la muestra. En el resto de la población, se toman muestras con el método de selección aleatorio.
Nota
Cuanto más bajo se establezca el valor de corte del estrato de certeza, más se incrementará el tamaño de la muestra general.
Debe evitar establecer un valor de corte innecesariamente bajo. Si no está seguro en qué nivel fijar el valor, consulte con un especialista en muestreo.
Estrato de certeza superior e inferior
La opción de estrato de certeza en Analytics define únicamente un estrato de certeza superior. Los números superiores o iguales al valor de corte se incluyen en el estrato de certeza.
Es posible que también desee tener un estrato de certeza inferior para incluir automáticamente valores negativos considerables en la muestra y para reducir la varianza.
Para crear un estrato de certeza inferior, puede usar cualquiera de los siguientes métodos:
- Antes de comenzar con el proceso de variables clásicas, utilice un filtro y extraiga todos los valores de la población que sean inferiores o iguales a un valor de corte inferior.
Puede conservar estos registros en una tabla independiente o puede anexarlos a la tabla de salida que contiene las muestras del resto de la población.
Si desea obtener más información, consulte Extracción y adición de datos.
- Durante las etapas CVS Preparar y CVS Muestra, utilice la condición Si para filtrar los elementos del estrato de certeza inferior.
Precaución
Este método es más riesgoso y menos recomendable, porque usted debe recordar aplicar sistemáticamente la condición Si en ambas etapas y durante cualquier repetición posterior de las etapas.
De qué manera selecciona registros el muestreo de variables clásicas
El muestreo de variables clásicas usa el siguiente proceso para seleccionar registros de muestra de una tabla de Analytics:
- Especifique un campo numérico como base para el muestreo. La unidad de muestreo es un registro individual de la tabla.
- Con el método de selección aleatorio, Analytics selecciona muestras de entre los registros de la tabla.
- Si está usando la estratificación, se selecciona de manera aleatoria una cantidad aproximadamente igual de registros de cada estrato.
- Si no está utilizando la estratificación, los registros se seleccionan de manera aleatoria de la población completa.
- Los registros seleccionados se incluyen en la tabla de salida de muestreo.
Ejemplo
En una tabla con 300 registros, divididos en 3 estratos, Analytics podría seleccionar los siguientes números de registros:
| Estrato 1 | Estrato 2 | Estrato 3 |
|---|---|---|
|
|
|
En una tabla no estratificada, con 300 registros, Analytics podría seleccionar los números de registros que se muestran a continuación: Puede ver que el número de registros seleccionados está distribuido de manera menos uniforme.
Nota
Los números de registros a continuación se agrupan en tres columnas para facilitar la comparación, pero las columnas no representan a los estratos.
|
|
|
Selección de muestra sin desviación
El muestreo de variables clásicas no tiene sesgo y no se basa en los importes contenidos en un registro. Cada registro tiene la misma posibilidad de ser seleccionado para su inclusión en la muestra. Un registro que contiene un importe de $1000, un registro que contiene un importe de $250 y un registro que contiene un importe de $1 tienen la misma oportunidad de ser seleccionados.
En otras palabras, la probabilidad de que cualquier registro determinado sea seleccionado no tiene ninguna relación con el tamaño del importe que contiene.